谈谈C++中的数据对齐
对于C/C++程序员来说,掌握数据对齐是很有必要的,因为只有了解了这个概念,才能知道编译器在什么时候会偷偷的塞入一些字节(padding)到我们的结构体(struct/class),也唯有这样我们才能更好的理解、优化结构体和内存。
几个栗子
看看几个简单的Struct,能猜出他们的SIZE吗?(运行于64Bit win10 vs2017)
struct A
{
char c1;
};
struct B
{
int i1;
};
struct C
{
char c1;
int i1;
};
struct D
{
char c1;
int i1;
char c2;
};
struct E
{
char c1;
char c2;
int i1;
};
int main()
{
std::cout << "A's size is " << sizeof(A) << std::endl;
std::cout << "B's size is " << sizeof(B) << std::endl;
std::cout << "C's size is " << sizeof(C) << std::endl;
std::cout << "D's size is " << sizeof(D) << std::endl;
std::cout << "E's size is " << sizeof(E) << std::endl;
}
先揭晓答案
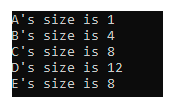
如果对任何一个结构体的大小有疑问,那么这篇文章非常适合你,请接着往下看,我们会解释数据对齐。
数据对齐
处理器读取数据的行为
在C/C++中,每种数据类型都有对齐的要求(这个更多是处理器的要求而非语言层面),大家都知道,处理器工作的时候需要数据总线(data bus)、控制总线(control bus)和地址总线(address bus)一起配合工作。而在数据总线取数据的时候,处理器为了高效的工作,一次会取4byte或者8byte数据(依系统32bit或者64bit而不同),这就是所谓数据字长(word size)。同时在读取内存的时候,也会从4byte或者8byte边界开始读取,这是处理器行为,我们只能尊重不能改变。考虑下面的例子,
struct F
{
int i1
char c1;
int i2;
char c2;
};
#include <iostream>
int main()
{
F f;
printf("0x%p\n", &f);
}
它的起始地址输出是:
0x000000FE8BCFFB88
所以在内存中可能的排列就是:

读取数据的时候,每次读入8btye,8个字节为一个读取单元,就像蒸笼的一格,这样做的好处是每次可以尽可能多的读入数据,减少读取次数。设想,如果一次只读入一个字节数据,那么一个Int就需要4次读取,明显效率就很低。
编译器的做法
如果没有对齐
了解了处理器如何读取数据的,我们就不难理解编译器为什么会做出调整。试想,如果编译器不在后台做出填充(padding),那么我们就会遇到这种情况

像这样的话,访问i1, c1 都不会有问题,但是访问i2就会发现,数据散落在不同的蒸笼,原本只需要一次读取就行的数据,还需要一次额外的数据读取才行,这就造成了读取数据的低效,在某些严格的CPU,比如ARM上面,这种非对齐的数据读操作甚至会被拒绝。
编译器对齐
所以,为了让数据读取效率最大化,编译器会选择牺牲一部分空间来换取效率,他们不会允许i2横跨两个读取单元。在实际中,上面的结构体会是这样的

可以看出,
- 为了解决i2的对齐问题,c1之后填充了3个空字节
- 同时为了保持整个结构体的对齐(结构体对齐字节数等于其最大的数据成员的对齐字节数,这里是4),在结构体的尾部还会有3个空字节
- 整个结构体的大小就是16字节,有6个字节是空字节。
所以,在编译器的作用下,最开始几个Struct实际上扩展为,
struct A
{
char c1; //no padding
};
struct B
{
int i1; //no padding
};
struct C
{
char c1;
char pad[3]; //padding
int i1;
};
struct D
{
char c1;
char pad1[3]; //padding
int i1;
char c2;
char pad2[3]; //padding
};
struct E
{
char c1;
char c2;
char pad[2]; //padding
int i1;
};
对齐的目的是要让数据访问更高效,一般来说,数据类型的对齐要求和它的长度是一致的,比如,
- char 是 1
- short 是 2
- int 是 4
- double 是 8
这不是巧合,比如short,2对齐保证了short只可能出现在一个读取单元的0, 2, 4, 6格,而不会出现在1, 3, 5, 7格;再比如int,4对齐保证了一个读取单元可以装载2个int——在0或者4格。从根本上杜绝了同一个数据横跨读取单元的问题。
总结
可能有人会疑惑了,知道这些对我们工作有什么帮助吗?如果仅仅是比较High-Level的应用程序编程,可能确实感觉不明显,最多就当成一个知识点了解一下,但是对于搞比较底层开发的,比如游戏引擎,或者是在内存环境很紧张的情况下开发,比如嵌入式开发,那了解这个有助于在某些情况下节约内存。
考虑前面的D和E结构体,他们拥有完全一样的成员,却有着不同的结构体大小,就是因为E选择把对齐要求接近的变量类型放在一起,减小了填充padding的数量从而达到了减小结构体大小的目的。
在设计结构体的时候,这个可以作为一个考量,有一些函数可以帮助我们查看某个类型的对齐要求,比如Visual Studio中的__alignof函数。
这就是关于数据对齐的一些基础知识,希望能帮助大家解惑,如果您发现本文有任何写的不对的地方,欢迎留言指出来;如果有其他问题,也欢迎留言一起讨论。
谈谈C++中的数据对齐的更多相关文章
- 【C/C++开发】内存对齐(内存中的数据对齐)、大端模式及小端模式
数据对齐,是指数据所在的内存地址必须是该数据长度的整数倍.DWORD数据的内存起始地址能被4除尽,WORD数据的内存起始地址能被2除尽.X86 CPU能直接访问对齐的数据,当它试图访问一个未对齐的数据 ...
- Ultra Edit中的数据对齐
有时会用到Ultra Edit的数据对齐功能.比如,要求64个符号一组,从低位开始对齐.这时,如果数据长度不是一行长度的整数, 就会产生高位对齐.低位不足的问题.为了调整,往往需要逐行调整,很不方便. ...
- C++中数据对齐问题。struct、union、enum,类继承。再谈sizeof()
首先是struct,在C++中,结构体其实和class有很大的相似了.但是有一点不同的是,struct默认是public,而class中是private. 当然,struct继承等用法也是可以的. 共 ...
- C++中数据对齐
大体看了看数据对齐,不知道是否正确,总结如下: struct A { char name; double dHeight; int age; }; sizeof(A) = (1+7+8+4+4) = ...
- gcc数据对齐之: howto 2.
原文链接:http://www.catb.org/esr/structure-packing/ 谁应阅读本文 本文探讨如何通过手工重新打包C结构体声明,来减小内存空间占用.你需要掌握基本的C语言知识, ...
- DataTable to Excel(使用NPOI、EPPlus将数据表中的数据读取到excel格式内存中)
/// <summary> /// DataTable to Excel(将数据表中的数据读取到excel格式内存中) /// </summary> /// <param ...
- 浅谈Oracle中物理结构(数据文件等。。。)与逻辑结构(表空间等。。。。。)
初始Oracle时很难理解其中的物理结构和逻辑结构,不明白内存中和硬盘中文件的区别和联系,我也是初学Oracle,这里就简单的谈谈我我看法. 首先,你需要明白的一点是:数据库的物理结构是由数据库的操作 ...
- c#.net循环将DataGridView中的数据赋值到Excel中,并设置样式
Microsoft.Office.Interop.Excel.Application excel = new Microsoft.Office.Interop.Excel ...
- ligerui_实际项目_003:form中添加数据,表格(grid)里面显示,最后将表格(grid)里的数据提交到servlet
实现效果: "Form"中填写数据,向本页"Grid"中添加数据,转换成Json数据提交,计算总和,Grid文本框可编辑,排序 图片效果: 总结: //disp ...
随机推荐
- Linux CentOS7.x 升级内核的方法
一.概述 在数据中心基础环境中,Linux系统使用很普遍,但是有时候会遇到应用程序需要运行在高版本的内核上或者有时候系统自身要求需要升级内核,我们要综合考虑升级内核的风险. 二.升级内核的方法 1.查 ...
- Chrome console & Command Line API
Chrome console & Command Line API $ && $$ querySelector querySelectorAll Command Line AP ...
- Nuxt.js SSR Optimizing Tips
Nuxt.js SSR Optimizing Tips 性能优化 FP 首次绘制时间 FCP 首次渲染时间 FMP 首屏渲染时间 FI refs https://vueschool.io/articl ...
- how to open a terminal in finder folder of macOS
how to open a terminal in finder folder of macOS shit service demo refs https://lifehacker.com/launc ...
- NGK与AOFEX交易所达成战略合作,BGV即将上线A网!
据NGK官方消息,NGK官方已经与英国伦敦知名交易所AOFEX交易所达成战略合作,将于12月2日全球首发BGV,现已开启充值服务.同时,在12月3日15:00,用户可以参与BGV交易:在12月4日15 ...
- 人物传记——Kyle Tedford:持之以恒的品质从哪里来?
心理学家表示,95%的人类行为发生在无意识中,而大多数这种行为是由习惯引起的.习惯,就像我们大脑设定的程序.通过每日持续努力,你会把坚持的习惯节奏慢慢进入身体中,并且会很容易加持下去. 做事三分钟热度 ...
- “NGK公链+5G”——打造智慧城市
智慧城市目前被全球各国当成城市建设的重点,旨在城市在智能化的同时,还能给民众带来幸福感和安全感.随着5G的到来,城市智能化又到了一个新的高度.比如无人驾驶.无人机等方面将会产生质的变化,因为5G的加入 ...
- Java并发包源码学习系列:线程池ScheduledThreadPoolExecutor源码解析
目录 ScheduledThreadPoolExecutor概述 类图结构 ScheduledExecutorService ScheduledFutureTask FutureTask schedu ...
- 深入解析 HTTP 缓存控制
缓存(Cache)是计算机领域里的一个重要概念,是优化系统性能的利器. 由于链路漫长,网络时延不可控,浏览器使用 HTTP 获取资源的成本较高.所以,非常有必要把"来之不易"的数据 ...
- SpringBoot源码解析
1.@SpringBootApplication springboot采用注解方式开发的,当创建了一个springboot项目时,在启动类上会有一个注解@SpringBootApplication,这 ...