mapreduce的一些简单使用
一、键值对RDD的创建
1、从文件中加载
/opt目录下创建wordky.txt文件。

wordky.txt文件中输入以下三行字符:
Hadoop is good
Spark is fast
Spark is better
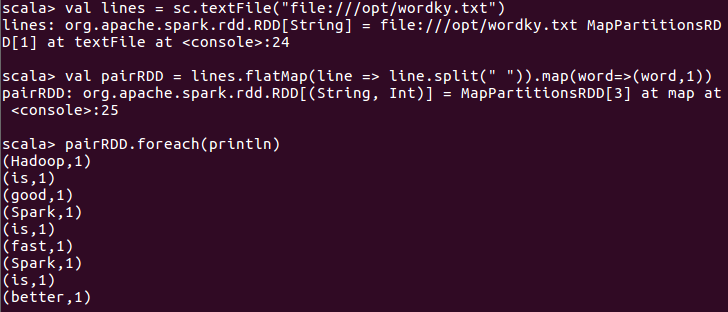
使用map()函数转换得到相应的键值对RDD并输出:

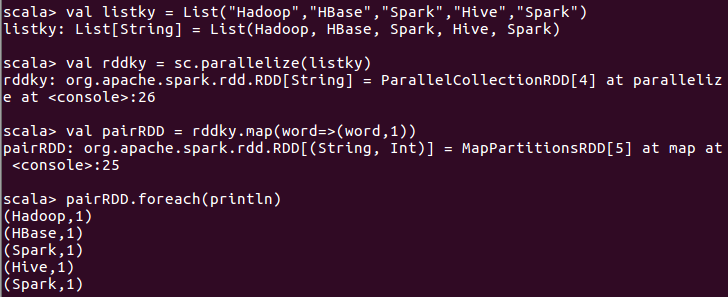
2、从列表中创建键值对RDD
二、常用的键值对转换操作
1、使用reduceByKey(func)统计每个单词的出现次数

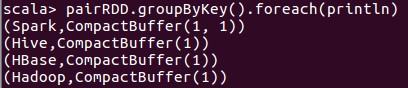
2、使用groupByKey()对具有相同键的值进行分组
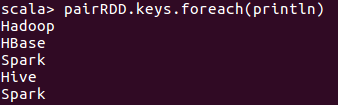
3、使用keys返回所有的key
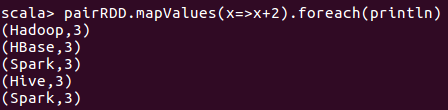
4、使用values返回所有的value值
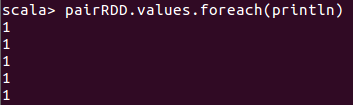
5、使用sortByKey()返回一个根据key排序的RDD
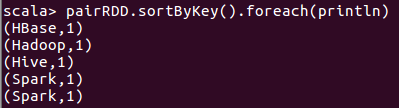
6、使用mapValues(func)
7、综合


8、数据读写



mapreduce的一些简单使用的更多相关文章
- 国内最全最详细的hadoop2.2.0集群的MapReduce的最简单配置
简介 hadoop2的中的MapReduce不再是hadoop1中的结构已经没有了JobTracker,而是分解成ResourceManager和ApplicationMaster.这次大变革被称为M ...
- mapreduce on yarn简单内存分配解释
关于mapreduce程序运行在yarn上时内存的分配一直是一个让我蒙圈的事情,单独查任何一个资料都不能很好的理解透彻.于是,最近查了大量的资料,综合各种解释,终于理解到了一个比较清晰的程度,在这里将 ...
- [How to] MapReduce on HBase ----- 简单二级索引的实现
1.简介 MapReduce计算框架是二代hadoop的YARN一部分,能够提供大数据量的平行批处理.MR只提供了基本的计算方法,之所以能够使用在不用的数据格式上包括HBase表上是因为特定格式上的数 ...
- Hadoop(11)-MapReduce概述和简单实操
1.MapReduce的定义 2.MapReduce的优缺点 优点 缺点 3.MapReduce的核心思想 4.MapReduce进程 5.常用数据序列化类型 6.MapReduce的编程规范 用户编 ...
- mapreduce实现搜索引擎简单的倒排索引
使用hadoop版本为2.2.0 倒排索引简单的可以理解为全文检索某个词 例如:在a.txt 和b.txt两篇文章分别中查找统计hello这个单词出现的次数,出现次数越多,和关键词的吻合度就越高 现有 ...
- MapReduce原理及简单实现
MapReduce是Google在2004年发表的论文<MapReduce: Simplified Data Processing on Large Clusters>中提出的一个用于分布 ...
- MapReduce应用案例--简单排序
1. 设计思路 在MapReduce过程中自带有排序,可以使用这个默认的排序达到我们的目的. MapReduce 是按照key值进行排序的,我们在Map过程中将读入的数据转化成IntWritable类 ...
- MapReduce应用案例--简单的数据去重
1. 设计思路 去重,重点就是无论某个数据在文件中出现多少次,最后只是输出一次就可以. 根据这一点,我们联想到在reduce阶段数据输入形式是 <key, value list>,只要是k ...
- MapReduce几个简单的例子
文件合并和去重: 可以把每一行文本作为key,value为随意值. 数字排序: MapReduce过程中就有排序,它是按照key值进行排序的,如果key为封装int的IntWritable类型,那么M ...
随机推荐
- JavaScript作用域与对象
1 - 作用域 1.1 作用域概述 通常来说,一段程序代码中所用到的名字并不总是有效和可用的,而限定这个名字的可用性的代码范围就是这个名字的作用域.作用域的使用提高了程序逻辑的局部性,增强了程序的可靠 ...
- 2个案例带你快速实现Response返回值
今天先来学习一下Response的相关知识. 所有返回前台的内容其实都应该是Response的对象或者其子类,我们看到如果返回的是字符串直接可以写成return u'字符串内容'的形式,但是其实这个字 ...
- 牛哄哄的celery
一.什么是Celery 1.1.celery是什么 Celery是一个简单.灵活且可靠的,处理大量消息的分布式系统,专注于实时处理的异步任务队列,同时也支持任务调度. Celery的架构由三部分组成, ...
- JS数组遍历的十二种方式
遍历有如下几种方式 数组方法 map forEach filter find findIndex every some reduce reduceRight 其他方法 for for in for o ...
- Kubernetes K8S之通过yaml文件创建Pod与Pod常用字段详解
YAML语法规范:在kubernetes k8s中如何通过yaml文件创建pod,以及pod常用字段详解 YAML 语法规范 K8S 里所有的资源或者配置都可以用 yaml 或 Json 定义.YAM ...
- 《我想进大厂》之mysql夺命连环13问
想进大厂,mysql不会那可不行,来接受mysql面试挑战吧,看看你能坚持到哪里? 1. 能说下myisam 和 innodb的区别吗? myisam引擎是5.1版本之前的默认引擎,支持全文检索.压缩 ...
- 递归方式---通过子级id,获取子级和父级Name
#region 递归--返回 父级|子级 名称 #region --返回 父级|子级 名称 public string RetrurnTypeNames(string TypeId) { String ...
- 小白也能弄懂的目标检测YOLO系列之YOLOV1 - 第二期
上期给大家展示了用VisDrone数据集训练pytorch版YOLOV3模型的效果,介绍了什么是目标检测.目标检测目前比较流行的检测算法和效果比较以及YOLO的进化史,这期我们来讲解YOLO最原始V1 ...
- Spring源码学习(六)-spring初始化回调方法源码学习
1.spring官方指定了三种初始化回调方法 1.1.@PostConstruct.@PreDestory 1.2.实现 InitializingBean DisposableBean 接口 1.3. ...
- RocketMQ的发送模式和消费模式
前言 小伙伴们大家好啊,王子又来和大家一起闲谈MQ技术了. 通过之前文章的学习,我们已经对RocketMQ的基本架构有了初步的了解,那今天王子就和大家一起来点实际的,用代码和大家一起看看RocketM ...