【大数据】MapReduce开发小实战
Before:前提:hadoop集群应部署完毕。
一、实战科目:做一个Map Reduce分布式开发,开发内容为统计文件中的单词出现次数。
二、战前准备
1、本人在本地创建了一个用于执行MR的的文件,文件中有209行,每行写了“这是一个测试文件”的句子。
2、将该文件上传至HDFS中。你可以使用idea中的插件上传、也可以使用HDFS的可视化页面上传、也可以使用HDFS的命令上传,都可以。目的达到就行。
3、准备好开发环境,准备开发。
三、开战!
1、打开idea,创建com.test.hadoop.mr的包
2、在该包下创建MyWordCount的Java类,并进行如下编程
package com.test.hadoop.mr; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MyWordCount { public static void main(String[] args) throws Exception {
Configuration conf = new Configuration(true);
Job job = Job.getInstance(conf);
job.setJarByClass(MyWordCount.class); // Specify various job-specific parameters
job.setJobName("myJob"); Path input = new Path("/testApi/testUploadFile.txt");
FileInputFormat.addInputPath(job, input);//文件输入格式化;还有其他的数据源的输入格式化 Path output = new Path("/testApi/mr_output.txt");
if (output.getFileSystem(conf).exists(output)){
output.getFileSystem(conf).delete(output,true);//一般不删除!
}
FileOutputFormat.setOutputPath(job, output); job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(MyReducer.class); // Submit the job, then poll for progress until the job is complete
job.waitForCompletion(true);
}
}
3、创建对应的MyMapper和MyReducer类
MyMapper
package com.test.hadoop.mr; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException;
import java.util.StringTokenizer; public class MyMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//AAA BBB CCC
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);//引用传参,减少创建对象的次数。
}
}
}
MyReducer
package com.test.hadoop.mr; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { //相同的key为一组,调用方法,然后在方法内迭代一组数据进行计算(sum/max/min/count/...)。 private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
4、打jar包
右键项目根目录,点击Open Module Settings;然后选择Artifacts,然后右边栏选择要打包的主类以及是否添加lib(lib可能会很大,建议不要在jar中添加lib)。
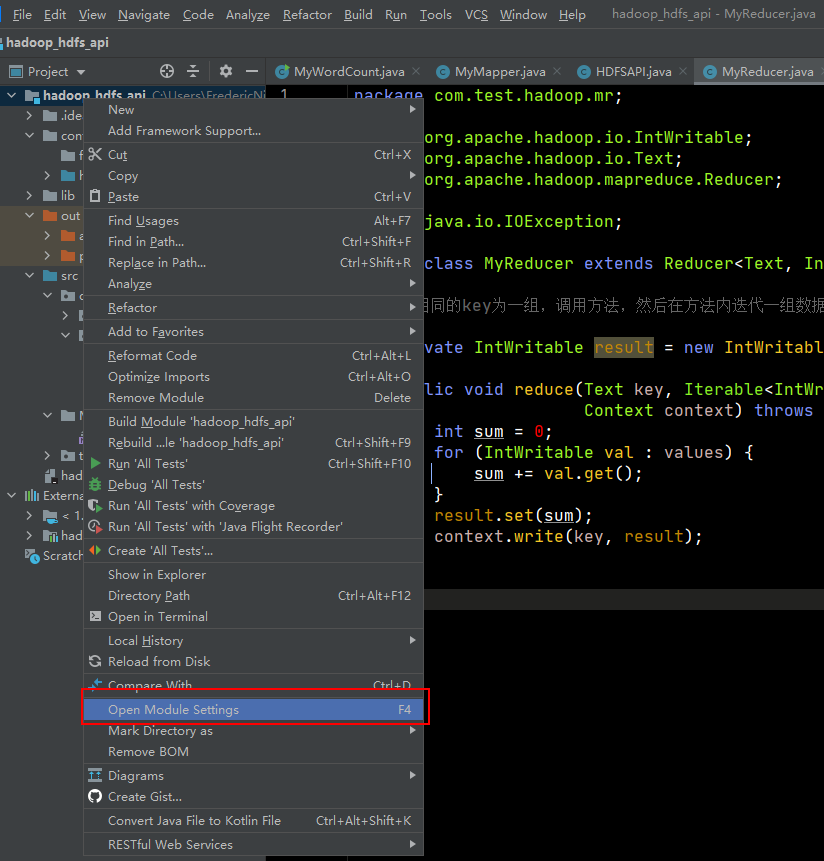

然后,在build中选择build Artifacts进行编译。
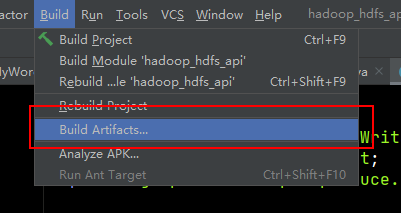

在你设置的目录下,发现输出的jar文件。

5、上传集群
将该文件上传集群某节点,这里选择节点1。
6、执行
定位到jar目录,输入命令,并执行
hadoop jar hadoop_hdfs_api.jar com.test.hadoop.mr.MyWordCount
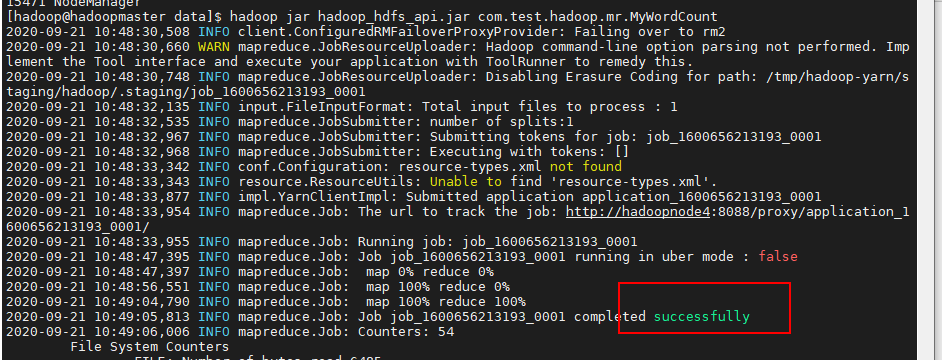
成功执行!
7、查看结果
在节点1的对应位置找到结果文件,cat查看内容

成功统计,说明逻辑以及实战运行均无误!
四、实战总结
首先,要了解MapReduce的运行机制,在客户端的开发中,我们不仅要使用Java实现客户端的基础配置外,还要实现Map Task即对应的MyMapper类,还要实现Reduce Task即对应的MyReducer类。
其次,在进行运行时,可能会报编译版本过高的错误,即你的服务器版本使用java8,而idea本身使用更高版本的Java编译,就会导致此问题,博主就遇到了。因此,要不就是升级服务器Java版本,要么就要用低版本Java进行编译,生成jar。两种策略中,服务器能不动就不动,因为改动成本太大。所以使用idea低版本进行编译,具体如何设置请自行百度或Google。
最后,Java类的编写要参考源码中的例子,在知道了MR的逻辑运行之后,要懂得代码的实现,这条路还很漫长,要加油!
【大数据】MapReduce开发小实战的更多相关文章
- 基于Hadoop2.0、YARN技术的大数据高阶应用实战(Hadoop2.0\YARN\Ma
Hadoop的前景 随着云计算.大数据迅速发展,亟需用hadoop解决大数据量高并发访问的瓶颈.谷歌.淘宝.百度.京东等底层都应用hadoop.越来越多的企 业急需引入hadoop技术人才.由于掌握H ...
- 大数据 --> MapReduce原理与设计思想
MapReduce原理与设计思想 简单解释 MapReduce 算法 一个有趣的例子:你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃? MapReduce方法则是: 给在座 ...
- 我要进大厂之大数据MapReduce知识点(2)
01 我们一起学大数据 今天老刘分享的是MapReduce知识点的第二部分,在第一部分中基本把MapReduce的工作流程讲述清楚了,现在就是对MapReduce零零散散的知识点进行总结,这次的内容大 ...
- 我要进大厂之大数据MapReduce知识点(1)
01 我们一起学大数据 老刘今天分享的是大数据Hadoop框架中的分布式计算MapReduce模块,MapReduce知识点有很多,大家需要耐心看,用心记,这次先分享出MapReduce的第一部分.老 ...
- 大数据框架开发基础之Zookeeper入门
Zookeeper是Hadoop分布式调度服务,用来构建分布式应用系统.构建一个分布式应用是一个很复杂的事情,主要的原因是我们需要合理有效的处理分布式集群中的部分失败的问题.例如,集群中的节点在相互通 ...
- 《Hadoop大数据技术开发实战》学习笔记(一)
基于CentOS7系统 新建用户 1.使用"su-"命令切换到root用户,然后执行命令: adduser zonkidd 2.执行以下命令,设置用户zonkidd的密码: pas ...
- 《Hadoop》大数据技术开发实战学习笔记(二)
搭建Hadoop 2.x分布式集群 1.Hadoop集群角色分配 2.上传Hadoop并解压 在centos01中,将安装文件上传到/opt/softwares/目录,然后解压安装文件到/opt/mo ...
- 大数据mapreduce俩表join之python实现
二次排序 在Hadoop中,默认情况下是按照key进行排序,如果要按照value进行排序怎么办?即:对于同一个key,reduce函数接收到的value list是按照value排序的.这种应用需求在 ...
- 大数据框架开发基础之Sqoop(1) 入门
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , ...
随机推荐
- 动态数组java实现
数组是一种顺序存储的线性表,所有元素的内存地址是连续的. 动态数组相对于一般数组的优势是可以灵活地添加或删除元素.而一般数组则受限于固定的内存空间.只能有限的添加元素 动态数组(Dynamic Arr ...
- 编译u-boot时候,make distclean 出现rm:无法删除,****是一个目录
今天在编译u-boot的时候,make distclean,出现了rm:无法删除 "include/asm-arm/arch": 是一个目录.经过查看网友的解决办法,已经解决了. ...
- 区块链入门到实战(33)之Solidity – 数据类型
在用任何语言编写程序时,都需要使用变量来存储各种信息.变量是内存空间的名称,变量有不同类型,例如整型.字符串类型等等.操作系统根据变量的数据类型分配内存. Solidity中,变量类型有以下几大类: ...
- LR与LR?
目录 逻辑回归与线性回归 逻辑回归 1.建立目标函数 2. 梯度求解 3. 实现 线性回归 1. 建立目标函数 2. 求解 3. 实现 逻辑回归与交叉熵 逻辑回归与线性回归 逻辑回归 线性回归 目标函 ...
- Mac搭建appium环境
1.安装brew 查看是否已经装上brew,终端输入命令:brew --version,已经装上的就不用再装了: 如果没有安装,终端输入命令:ruby -e "$(curl -fsSL ht ...
- Spring Security如何优雅的增加OAuth2协议授权模式
一.什么是OAuth2协议? OAuth 2.0 是一个关于授权的开放的网络协议,是目前最流行的授权机制. 数据的所有者告诉系统,同意授权第三方应用进入系统,获取这些数据.系统从而产生一个短期的进入令 ...
- Android开发之清除缓存功能实现方法,可以集成在自己的app中,增加一个新功能。
作者:程序员小冰,CSDN博客:http://blog.csdn.net/qq_21376985 Android开发之清除缓存功能实现方法,可以集成在自己的app中,增加一个新功能. 下面是一个效果图 ...
- Android Studio Eclipse运行时出现 finished with non-zero exit value 2 错误解决方法
作者:程序员小冰,CSDN博客:http://blog.csdn.net/qq_21376985 QQ986945193 微博:http://weibo.com/mcxiaobing Error:Ex ...
- Activiti7 学习总结
什么是工作流? 就是通过计算机对业务流程进行自动化处理,实现多个参与者按照预定义的流程去自动执行业务流程 什么是Activiti? Activiti是一个工作流引擎,开源的架构,基于BPMN2.0标准 ...
- Codeforces Round #669 (Div. 2)/Codeforces1407 ABCD
A. Ahahahahahahahaha 通过作者半个小时的观察:全零和全一必定有一个是符合要求的答案,因为0的个数和1的个数至少有一个大于等于\(\frac{n}{2}\). B. Big Vova ...