深入Redis 主从复制原理
- 1.复制过程
- 2.数据间的同步
- 3.全量复制
- 4.部分复制
- 5.心跳
- 6.异步复制
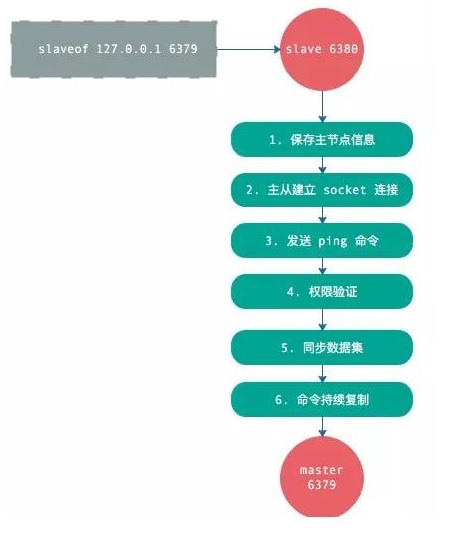
1.复制过程
- 从节点执行 slaveof 命令。
- 从节点只是保存了 slaveof 命令中主节点的信息,并没有立即发起复制。
- 从节点内部的定时任务发现有主节点的信息,开始使用 socket 连接主节点。
- 连接建立成功后,发送 ping 命令,希望得到 pong 命令响应,否则会进行重连。
- 如果主节点设置了权限,那么就需要进行权限验证,如果验证失败,复制终止。
- 权限验证通过后,进行数据同步,这是耗时最长的操作,主节点将把所有的数据全部发送给从节点。
- 当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来,主节点就会持续的把写命令发送给从节点,保证主从数据一致性。
2.数据间的同步
上面说的复制过程,其中有一个步骤是“同步数据集”,这个就是现在讲的“数据间的同步”。
redis 同步有 2 个命令:sync 和 psync,前者是 redis 2.8 之前的同步命令,后者是 redis 2.8 为了优化 sync 新设计的命令。我们会重点关注 2.8 的 psync 命令。
psync 命令需要 3 个组件支持:
- 主从节点各自复制偏移量
- 主节点复制积压缓冲区
- 主节点运行 ID
主从节点各自复制偏移量:
- 参与复制的主从节点都会维护自身的复制偏移量。
- 主节点在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在 info replication 中的 masterreploffset 指标中。
- 从节点每秒钟上报自身的的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量。
- 从节点在接收到主节点发送的命令后,也会累加自身的偏移量,统计信息在 info replication 中。
- 通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
主节点复制积压缓冲区:
- 复制积压缓冲区是一个保存在主节点的一个固定长度的先进先出的队列,默认大小 1MB。
- 这个队列在 slave 连接是创建。这时主节点响应写命令时,不但会把命令发送给从节点,也会写入复制缓冲区。
- 他的作用就是用于部分复制和复制命令丢失的数据补救。通过 info replication 可以看到相关信息。
主节点运行 ID:
- 每个 redis 启动的时候,都会生成一个 40 位的运行 ID。
- 运行 ID 的主要作用是用来识别 Redis 节点。如果使用 ip+port 的方式,那么如果主节点重启修改了 RDB/AOF 数据,从节点再基于偏移量进行复制将是不安全的。所以,当运行 id 变化后,从节点将进行全量复制。也就是说,redis 重启后,默认从节点会进行全量复制。
如果在重启时不改变运行 ID 呢?
- 可以通过 debug reload 命令重新加载 RDB 并保持运行 ID 不变,从而有效的避免不必要的全量复制。
- 缺点是:debug reload 命令会阻塞当前 Redis 节点主线程,因此对于大数据量的主节点或者无法容忍阻塞的节点,需要谨慎使用。一般通过故障转移机制可以解决这个问题。
psync 命令的使用方式:
命令格式为 psync{runId}{offset}
runId:从节点所复制主节点的运行 id
offset:当前从节点已复制的数据偏移量
psync 执行流程:
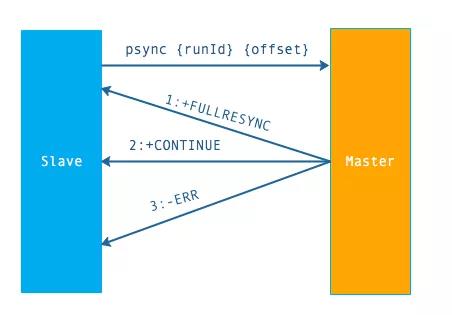
流程说明:
从节点发送 psync 命令给主节点,runId 就是目标主节点的 ID,如果没有默认为 -1,offset 是从节点保存的复制偏移量,如果是第一次复制则为 -1.
主节点会根据 runid 和 offset 决定返回结果:
- 如果回复 +FULLRESYNC {runId} {offset} ,那么从节点将触发全量复制流程。
- 如果回复 +CONTINUE,从节点将触发部分复制。
- 如果回复 +ERR,说明主节点不支持 2.8 的 psync 命令,将使用 sync 执行全量复制。
到这里,数据之间的同步就讲的差不多了,篇幅还是比较长的。主要是针对 psync 命令相关之间的介绍。
3.全量复制
全量复制是 Redis 最早支持的复制方式,也是主从第一次建立复制时必须经历的的阶段。触发全量复制的命令是 sync 和 psync。之前说过,这两个命令的分水岭版本是 2.8,redis 2.8 之前使用 sync 只能执行全量不同,2.8 之后同时支持全量同步和部分同步。
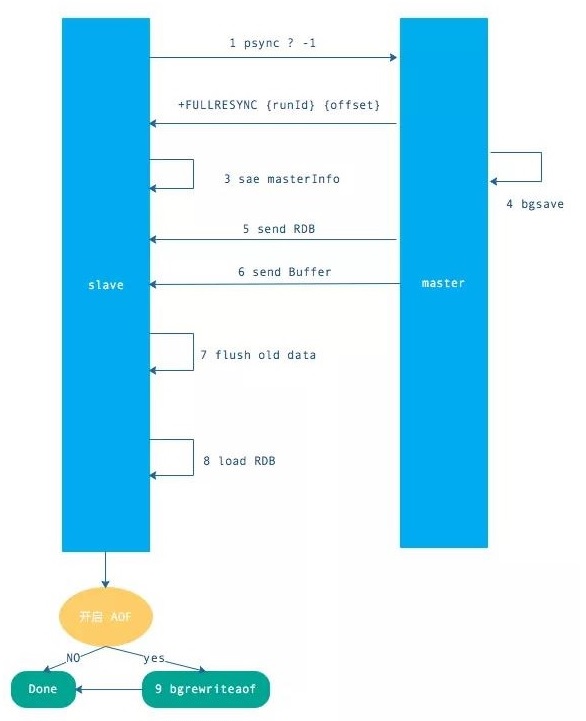
流程如下:
- 发送 psync 命令(spync ? -1)
- 主节点根据命令返回 FULLRESYNC
- 从节点记录主节点 ID 和 offset
- 主节点 bgsave 并保存 RDB 到本地
- 主节点发送 RBD 文件到从节点
- 从节点收到 RDB 文件并加载到内存中
- 主节点在从节点接受数据的期间,将新数据保存到“复制客户端缓冲区”,当从节点加载 RDB 完毕,再发送过去。(如果从节点花费时间过长,将导致缓冲区溢出,最后全量同步失败)
- 从节点清空数据后加载 RDB 文件,如果 RDB 文件很大,这一步操作仍然耗时,如果此时客户端访问,将导致数据不一致,可以使用配置slave-server-stale-data 关闭.
- 从节点成功加载完 RBD 后,如果开启了 AOF,会立刻做 bgrewriteaof。
以上加粗的部分是整个全量同步耗时的地方。
注意:
- 如过 RDB 文件大于 6GB,并且是千兆网卡,Redis 的默认超时机制(60 秒),会导致全量复制失败。可以通过调大 repl-timeout 参数来解决此问题。
- Redis 虽然支持无盘复制,即直接通过网络发送给从节点,但功能不是很完善,生产环境慎用。
4.部分复制
当从节点正在复制主节点时,如果出现网络闪断和其他异常,从节点会让主节点补发丢失的命令数据,主节点只需要将复制缓冲区的数据发送到从节点就能够保证数据的一致性,相比较全量复制,成本小很多。
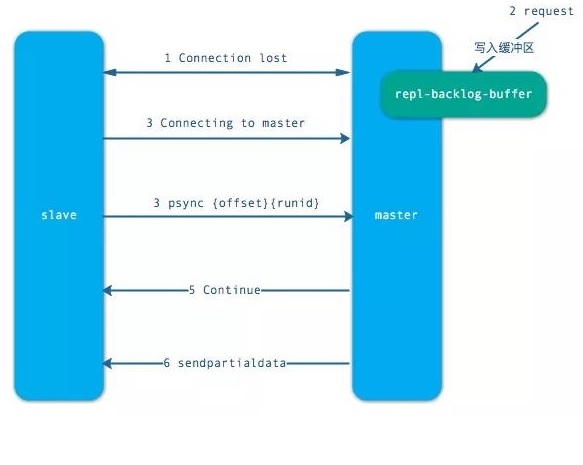
- 当从节点出现网络中断,超过了 repl-timeout 时间,主节点就会中断复制连接。
- 主节点会将请求的数据写入到“复制积压缓冲区”,默认 1MB。
- 当从节点恢复,重新连接上主节点,从节点会将 offset 和主节点 id 发送到主节点。
- 主节点校验后,如果偏移量的数后的数据在缓冲区中,就发送 cuntinue 响应 —— 表示可以进行部分复制。
- 主节点将缓冲区的数据发送到从节点,保证主从复制进行正常状态。
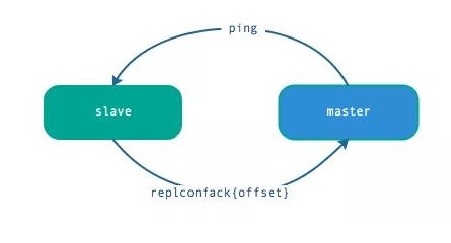
5.心跳
主从节点在建立复制后,他们之间维护着长连接并彼此发送心跳命令。
心跳的关键机制如下:
- 中从都有心跳检测机制,各自模拟成对方的客户端进行通信,通过 client list 命令查看复制相关客户端信息,主节点的连接状态为 flags = M,从节点的连接状态是 flags = S。
- 主节点默认每隔 10 秒对从节点发送 ping 命令,可修改配置 repl-ping-slave-period 控制发送频率。
- 从节点在主线程每隔一秒发送 replconf ack{offset} 命令,给主节点上报自身当前的复制偏移量。
- 主节点收到 replconf 信息后,判断从节点超时时间,如果超过 repl-timeout 60 秒,则判断节点下线。
注意:
为了降低主从延迟,一般把 redis 主从节点部署在相同的机房/同城机房,避免网络延迟带来的网络分区造成的心跳中断等情况。
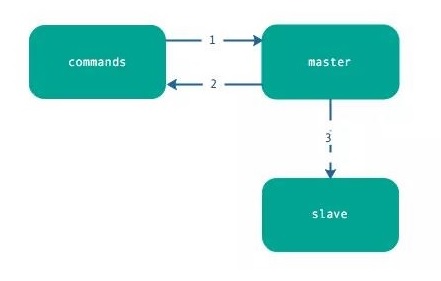
6.异步复制
主节点不但负责数据读写,还负责把写命令同步给从节点,写命令的发送过程是异步完成,也就是说主节点处理完写命令后立即返回客户度,并不等待从节点复制完成。
异步复制的步骤很简单,如下:
- 主节点接受处理命令。
- 主节点处理完后返回响应结果 。
- 对于修改命令,异步发送给从节点,从节点在主线程中执行复制的命令。
总结
本文主要分析了 Redis 的复制原理,包括复制过程,数据之间的同步,全量复制的流程,部分复制的流程,心跳设计,异步复制流程。其中,可以看出,RDB 数据之间的同步非常耗时。所以,Redis 在 2.8 版本退出了类似增量复制的 psync 命令,当 Redis 主从直接发生了网络中断,不会进行全量复制,而是将数据放到缓冲区(默认 1MB)里,在通过主从之间各自维护复制 offset 来判断缓存区的数据是否溢出,如果没有溢出,只需要发送缓冲区数据即可,成本很小,反之,则要进行全量复制,因此,控制缓冲区大小非常的重要。
深入Redis 主从复制原理的更多相关文章
- Redis 主从复制原理及雪崩 穿透问题
定义: Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,并提供多种语言的API.从2010年3月15日起,Redis的开发工作由VMw ...
- Redis主从复制原理总结
和Mysql主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况.为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构,Redi ...
- Redis面试篇 -- Redis主从复制原理
Redis一般是用来支撑读高并发的,为了分担读压力,Redis支持主从复制.架构是主从架构,一主多从, 主负责写,并且将数据复制到其它的 slave 节点,从节点负责读. 所有的读请求全部走从 ...
- 彻底搞懂Redis主从复制原理及实战
欢迎关注公众号:「码农富哥」,致力于分享后端技术 (高并发架构,分布式集群系统,消息队列中间件,网络,微服务,Linux, TCP/IP, HTTP, MySQL, Redis), Python 等 ...
- 都在讲Redis主从复制原理,我来讲实践总结
摘要:本文将演示主从复制如何配置.实现以及实现原理,Redis主从复制三大策略,全量复制.部分复制和立即复制. 本文分享自华为云社区<Redis主从复制实践总结>,原文作者:A梦多啦A . ...
- 太全了!Redis主从复制原理以及常见问题总结
相信很多小伙伴都已经配置过主从复制,但是对于redis主从复制的工作流程和常见问题很多都没有深入的了解.这次给大家整理一份redis主从复制的全部知识点. 下方可视频观看,效果更佳 Redis实战精讲 ...
- 详解Redis主从复制原理
文章首发于公众号 "蘑菇睡不着" 前言 Redis 的主从复制和 MySQL 差不多,主要起着 数据备份,读写分离等作用.所以说主从复制对 Redis 来说非常重要,而无论是面试还 ...
- Redis主从复制原理
前言: 和MySQL主从复制的原因一样,Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况.为了分担读压力,Redis支持主从复制,Redis的主从结构可以采用一主多从或者级联结构, ...
- redis 深入理解redis 主从复制原理
redis 主从复制 master 节点提供数据,也就是写.slave 节点负责读. 不是说master 分支不能读数据,也能只是我们希望将读写进行分离. slave 是不能写数据的,只能处理读请求 ...
随机推荐
- Linux系统之路——如何在服务器用U盘安装CentOS7.2(一)
终于将CentOS7装上服务器(thinkserver250,不得不说联想的太烂了)了,过程无比艰辛,因为我发现网上大家提到的所有U盘安装CentOS7时碰到的问题几乎都被我碰到了,像什么: 1.刻录 ...
- c++ 派生类的构造函数次序
#include <iostream> using namespace std; class CFatherSum //父类Sum { public: CFatherSum(int iRe ...
- mysql 聚集和非聚集索引 解析
一.聚集索引(聚簇索引) 1. 什么是聚集索引? 比如要查找'hello',则直接找内容为hello的行,我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”. 聚集索引的叶子节点 ...
- Discuz!在线中文分词服务
Discuz!在线中文分词服务是基于API返回分词结果的.在项目中,我们只需要一个函数即可方便地进行分词.关键词提取.以下是根据Discuz!在线分词服务API写的函数,测试可正常运行: 代码代码如下 ...
- 【[USACO08JAN]haybale猜测Haybale Guessing】
抄题解.jpg 完全完全不会啊,这道题简直太神了 不过抄题解可真开心 首先这道题目保证了每一个位置上的数都是不同的,那么就能得到第一种判断不合法的方式 如果两个区间的最小值一样,但是两个区间的交集为空 ...
- classlist和array.prototype.slice.call
1.classlist document.getElementById("myDIV").classList.add("mystyle"); classList ...
- WEB测试—兼容测试
现在的操作系统,浏览器越来越多样性,导致软件兼容性测试在目前软件测试领域占有很重要的地位,我在测试项目经历中,以浏览器的兼容测试为主,平台.分辨率为辅. (我的经验前提:我测试过3类的不同行业的web ...
- nginx发布antd-pro项目(别人发的,未测试)
server { listen ; server_name localhost; #charset koi8-r; charset utf-; #access_log logs/host.access ...
- Luogu[P1108] 低价购买
\(Link\) \(\mathcal{\color{red}{Description}}\) 请你求出一个数列的最长下降子序列长度,并为此求出其方案数. \[1 \leq N \leq 5000\] ...
- HttpWebRequest类,及如何使用Cookie(转载)
HttpWebRequest类与HttpRequest类的区别.HttpRequest类的对象用于服务器端,获取客户端传来的请求的信息,包括HTTP报文传送过来的所有信息.而HttpWebReques ...