spark-sql执行流程分析
spark-sql 架构

图1
图1是sparksql的执行架构,主要包括逻辑计划和物理计划几个阶段,下面对流程详细分析。
sql执行流程
总体流程
- parser;基于antlr框架对 sql解析,生成抽象语法树
- 变量替换,通过正则表达式找出符合规则的字符串,替换成系统缓存环境的变量
SQLConf中的`spark.sql.variable.substitute`,默认是可用的;参考` SparkSqlParser`
- parser;将antlr的tree转成spark catalyst的LogicPlan也就是unresolve logical plan;详细参考`AstBuild`, `ParseDriver`
- analyzer;通过分析器,结合catalog,把logical plan和实际的数据绑定起来,将unresolve logical plan生成 logical plan;详细参考`QureyExecution`
- 缓存替换,通过CacheManager,替换有相同结果的logical plan
- logical plan优化,基于规则的优化;优化规则参考Optimizer,优化执行器RuleExecutor
- 生成spark plan,也就是物理计划;参考`QueryPlanner`和`SparkStrategies`
- spark plan准备阶段
- 构造RDD执行,涉及spark的wholeStageCodegenExec机制,基于janino框架生成java代码并编译
其中`SessionState`类中维护了所有参与sql执行流程的实例对象,`QueryExecution`类则是实际处理SQL执行逻辑的类。需要注意的是,除了第1步,第2步和第3步是立即执行的,这是由于需要判断sql的合法性以及当前catalog环境下是否存在sql中的库表结构等,其他步骤都是在触发spark action的时候才被执行,也就是lazy加载。下面对整个流程的细节进行分析。
详细分析
变量替换
spark-sql通过正则匹配,将sql中的系统变量,环境变量等配置替换成真正的value,目前支持替换spark的配置和hive的配置
例如:
session.conf.set("spark.sql.test.key","1")
session.sql("select * from test where 1 =
${sparkconf:spark.sql.test.key}")
抽象语法树AST
先上一下wiki的解释,AST是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。说的可能有点抽象,翻译出来就是说把一个语言表达式的语法结构转换成树形结构,那这颗数就是抽象语法树。
举个例子,`1*2+3`这个表达式转成AST,如图2。
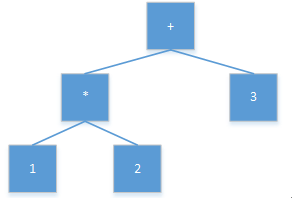
图2
SQL作为一种独立的语言,有自己的表达式,所以用AST作为对其语法进行分析是很灵活的。这里Spark选用的是anltr作为AST的构建框架,而不是hive用的calcite框架,antlr相比calcite更轻量,只涉及sql语法解析,这也便于spark自己在后续步骤做自己的sql执行定制化优化。
unresolve logical plan
spark通过visit antlr框架生成的AST,转换成unresolve LogicPlan,LogicPlan其实是spark定义的AST
分析器
spark所有的规则优化都是基于模式匹配来完成的。分析器这个步骤的主要工作是,基于catalog,完成对logical plan的resolve化。
是否resolved来源两个指标,1.
子节点是否resolved;2. 输入的数据类型是否满足要求,比如要求输入int类型,实际输入的string类型,那么就不满足要求。参考类`Expression`,`Analyzer`。
logical plan
常见的优化规则,下面列举部分:
移除group下的常量,对应`
RemoveLiteralFromGroupExpressions`
移除重复的group表达式,对应`
RemoveRepetitionFromGroupExpressions`
谓语下推,在进行其他操作之前,先进行Filter操作。当然这有很多条件限制,比如子查询中没有和父查询相同的条件字段,如果有那么下推会造成冲突
裁剪Filter操作,如果操作总是为True,那么移除,如果操作总是为False,那么用空替换
spark plan
结合LogicPlan和Strategy,将AST转换成实际执行的算子,参考`SparkPlanner`,内置了几个strategies。生成SparkPlan后,继续采用规则匹配的方式优化,其中就包括了著名的wholeStageCodegenExec机制,这个机制默认是开启的,`spark.sql.codegen.wholeStage`。
参考资料
https://www.jianshu.com/p/0aa4b1caac2e
spark-sql执行流程分析的更多相关文章
- Spark修炼之道(进阶篇)——Spark入门到精通:第九节 Spark SQL执行流程解析
1.总体执行流程 使用下列代码对SparkSQL流程进行分析.让大家明确LogicalPlan的几种状态,理解SparkSQL总体执行流程 // sc is an existing SparkCont ...
- Hive SQL执行流程分析
转自 http://www.tuicool.com/articles/qyUzQj 最近在研究Impala,还是先回顾下Hive的SQL执行流程吧. Hive有三种用户接口: cli (Command ...
- 深入浅出Mybatis系列(十)---SQL执行流程分析(源码篇)
最近太忙了,一直没时间继续更新博客,今天忙里偷闲继续我的Mybatis学习之旅.在前九篇中,介绍了mybatis的配置以及使用, 那么本篇将走进mybatis的源码,分析mybatis 的执行流程, ...
- Spark修炼之道(高级篇)——Spark源代码阅读:第十二节 Spark SQL 处理流程分析
作者:周志湖 以下的代码演示了通过Case Class进行表Schema定义的样例: // sc is an existing SparkContext. val sqlContext = new o ...
- 深入浅出Mybatis系列十-SQL执行流程分析(源码篇)
注:本文转载自南轲梦 注:博主 Chloneda:个人博客 | 博客园 | Github | Gitee | 知乎 最近太忙了,一直没时间继续更新博客,今天忙里偷闲继续我的Mybatis学习之旅.在前 ...
- 第一篇:Spark SQL源码分析之核心流程
/** Spark SQL源码分析系列文章*/ 自从去年Spark Submit 2013 Michael Armbrust分享了他的Catalyst,到至今1年多了,Spark SQL的贡献者从几人 ...
- 第十一篇:Spark SQL 源码分析之 External DataSource外部数据源
上周Spark1.2刚发布,周末在家没事,把这个特性给了解一下,顺便分析下源码,看一看这个特性是如何设计及实现的. /** Spark SQL源码分析系列文章*/ (Ps: External Data ...
- 第十篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 query
/** Spark SQL源码分析系列文章*/ 前面讲到了Spark SQL In-Memory Columnar Storage的存储结构是基于列存储的. 那么基于以上存储结构,我们查询cache在 ...
- 第九篇:Spark SQL 源码分析之 In-Memory Columnar Storage源码分析之 cache table
/** Spark SQL源码分析系列文章*/ Spark SQL 可以将数据缓存到内存中,我们可以见到的通过调用cache table tableName即可将一张表缓存到内存中,来极大的提高查询效 ...
随机推荐
- Unity3D笔记七 GUILayout
一.说到GUILayout就要提到GUI,二者的区别是什么 GUILayout是游戏界面的布局.GUI(界面)和GUILayout(界面布局)功能上面是相似的从命名中就可以看到这两个东西非常相像,但是 ...
- dubbo有什么作用
转自:http://blog.csdn.net/ichsonx/article/details/39008519 1. Dubbo是什么? Dubbo是一个分布式服务框架,致力于提供高性能和透明化的R ...
- Hive桶列BucketedTables
The CLUSTERED BY and SORTED BY creation commands do not affect how data is inserted into a table – o ...
- Linux系统下Nginx+PHP 环境安装配置
一.编译安装Nginx 官网:http://wiki.nginx.org/Install 下载:http://nginx.org/en/download.html # tar -zvxf nginx- ...
- request常用的方法
request方法综合:-- 返回请求方式:-request.getMethod()-----GET返回URI中的资源名称(位于URL中端口后的资源路径):-request.getRequestURI ...
- Java导出Excel表,POI 实现合并单元格以及列自适应宽度(转载)
POI是apache提供的一个读写Excel文档的开源组件,在操作excel时常要合并单元格,合并单元格的方法是: sheet.addMergedRegion(new CellRangeAddress ...
- opencv学习笔记——minMaxIdx函数的含义及用法
opencv中有时需要对Mat数据需要对其中的数据求取最大值和最小值.opencv提供了直接的函数 CV_EXPORTS_W void minMaxLoc(InputArray src, CV_OUT ...
- Python自动发布Image service的实现
使用Python自动发布地图服务已经在上一篇博客中讲到,使用Python创建.sd服务定义文件,实现脚本自动发布ArcGIS服务,下面是利用Python自动发布Image service的实现. -- ...
- windows 文件查找 大小:>250M
win7怎么快速查找大文件_百度经验 https://jingyan.baidu.com/article/acf728fd299ffff8e510a333.html
- uchome登录验证
Uchome采用cookie+数据库的方式来进行用户登录验证的 一.登录 1:登录表单由source/do_login.php 处理 2:然后验证用户名以及密码的正确性,不正确则跳转并提示登录失败 3 ...