4 使用Selenium模拟登录csdn,取出cookie信息,再用requests.session访问个人中心(保持登录状态)
代码:
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 13 16:13:52 2018 @author: a
""" from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
import urllib.request
import urllib.parse
from urllib.error import URLError
from urllib.error import HTTPError
import requests chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')#无界面模式
#下面的代码是错误的使用方式
#browser = webdriver.Chrome(chrome_options=chrome_options,executable_path = "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe")
#下面的代码是使用无界面模式
browser = webdriver.Chrome(chrome_options=chrome_options)
#browser = webdriver.Chrome()
print("xiaojie")
url="https://passport.csdn.net/account/login"
try:
browser.get(url)
data=browser.page_source
print (len(data)) target=browser.find_element_by_xpath('/html/body/div[3]/div/div/div[2]/div/h3/a')
print("target:",target)
target.click() locator=(By.ID,'username')
WebDriverWait(browser, 20, 0.5).until(EC.presence_of_element_located(locator))
username=browser.find_element_by_id('username')
print ("username:",username)
time.sleep(3)
username.clear()
username.send_keys('183247166@qq.com') password=browser.find_element_by_id('password')
print ("password:",password)
password.clear()
password.send_keys('xxx') submit=browser.find_element_by_xpath('//*[@id="fm1"]/input[8]')
print ("submit:",submit)
submit.click()
#time.sleep(10)#不用等待页面刷新。这步操作是不需要的。 #保存cookie信息。
cookies=browser.get_cookies() except Exception as e:
print("driver出现异常")
print (e)
finally:
browser.close()
print("over")
None #将之前selenium登录获得的cookie信息保存到requests的会话当中。
s=requests.session()
c = requests.cookies.RequestsCookieJar()
for item in cookies:
c.set(item["name"],item["value"])
s.cookies.update(c)
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400"
}
url2="https://download.csdn.net/my"#这是从网页登录以后,才能进入的个人空间。
try:
print("开始爬网页")
response=s.get(url2,headers=headers)
data=response.text
print (len(data))
print (data)
fhandle=open("./验证cookie能使用的网页,断网打开.html","w",encoding='utf-8')
fhandle.write(data.encode('utf-8').decode())
fhandle.close()
print ("验证cookie能使用的网页,断网打开.html已经成功生成")
except Exception as e:
print(e)
这里面,取出cookie信息以后,浏览器就关闭了。然后用requests.session去访问个人中心页面,携带cookie信息,发现可以成功保持个人中心页面!
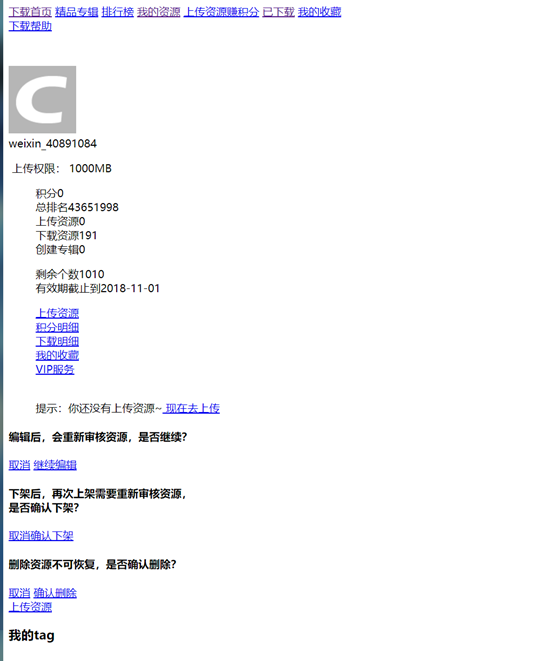
我做过其它方面的实验,就是,如下的代码:
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 13 16:13:52 2018 @author: a
""" from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
import urllib.request
import urllib.parse
from urllib.error import URLError
from urllib.error import HTTPError
import requests chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')#无界面模式
#下面的代码是错误的使用方式
#browser = webdriver.Chrome(chrome_options=chrome_options,executable_path = "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe")
#下面的代码是使用无界面模式
#browser = webdriver.Chrome(chrome_options=chrome_options)
browser = webdriver.Chrome()
print("xiaojie")
url="https://passport.csdn.net/account/login"
try:
browser.get(url)
data=browser.page_source
print (len(data))
curpage_url=browser.current_url
print (curpage_url) target=browser.find_element_by_xpath('/html/body/div[3]/div/div/div[2]/div/h3/a')
print("target:",target)
target.click() locator=(By.ID,'username')
WebDriverWait(browser, 20, 0.5).until(EC.presence_of_element_located(locator))
username=browser.find_element_by_id('username')
print ("username:",username)
time.sleep(3)
username.clear()
username.send_keys('183247166@qq.com') password=browser.find_element_by_id('password')
print ("password:",password)
password.clear()
password.send_keys('xxx') submit=browser.find_element_by_xpath('//*[@id="fm1"]/input[8]')
print ("submit:",submit)
submit.click()
curpage_url=browser.current_url
print (curpage_url)
#time.sleep(10)#不用等待页面刷新。这步操作是不需要的。 #保存cookie信息。
cookie =[item["name"] + ":" + item["value"] for item in browser.get_cookies()]
print (cookie)
cookiestr = ';'.join(item for item in cookie)
cook_map = {}
for item in cookie:
str = item.split(':')
cook_map[str[0]] = str[1]
print (cook_map)
cookies = requests.utils.cookiejar_from_dict(cook_map, cookiejar=None, overwrite=True)
s = requests.Session()
s.cookies = cookies
#使用urllib爬取网页
#下面的代码并不能成功执行。
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400")
opener=urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookies))
opener.addheaders=[headers]
url2="https://download.csdn.net/my"#这是从网页登录以后,才能进入的个人空间。 try:
urllib.request.install_opener(opener)
response=urllib.request.urlopen(url2)
print("开始爬网页")
fhandle=open("./验证cookie能使用的网页,断网打开.html","w",encoding='utf-8')
fhandle.write(data.encode('utf-8').decode())
fhandle.write(data)
fhandle.close()
print ("验证cookie能使用的网页,断网打开.html已经成功生成")
except HTTPError as e:
print("出现HTTP异常")
print(e.code)
print(e.reason)
except URLError as e:
print("出现URL异常")
print(e.reason)
except Exception as e:
print("driver出现异常")
print (e)
finally:
browser.close()
print("over")
None
我写的上面的代码是有问题的。打开保存的网页是:说明没有保持登录状态。
如果还使用urllib.request.urlopen,并且将selenium模拟登录之后的cookie转变为CookieJar的方式,会发现不能保持登录状态访问。而精通Python网络爬虫一书中是要先创建CookieJar对象,创建全局的opener,然后再登录,这样的话,cookie会保存到全局的opener中,之后就能保持登录状态,继续使用urllib。但是,我这里先用selenimu模拟登录,之后才是基于得到的cookie创建CookieJar,然后再使用urllib。为什么会不行呢,
参考如下博客:
https://blog.csdn.net/warrior_zhang/article/details/50198699
python 利用selenium模拟登录帐号验证网站并获取cookie
其中包含两步:
6.通过对象的方法获取当前访问网站的session cookie:
|
#get the session cookie cookie = [item["name"] + "=" + item["value"] for item in sel.get_cookies()] #print cookie cookiestr = ';'.join(item for item in cookie) print cookiestr |
7.得到cookie之后,就可以通过urllib2访问相应的网站,并可实现网页爬取等工作:
|
import urllib2 print '%%%using the urllib2 !!' homeurl = sel.current_url print 'homeurl: %s' % homeurl headers = {'cookie':cookiestr} req = urllib2.Request(homeurl, headers = headers) try: response = urllib2.urlopen(req) text = response.read() fd = open('homepage', 'w') fd.write(text) fd.close() print '###get home page html success!!' except: print '### get home page html error!!' |
它是将cookie放在headers中,之后再使用urllib。我们测试一下:
编写代码:
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 13 16:13:52 2018 @author: a
""" from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
import urllib.request
import urllib.parse
from urllib.error import URLError
from urllib.error import HTTPError chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')#无界面模式
#下面的代码是错误的使用方式
#browser = webdriver.Chrome(chrome_options=chrome_options,executable_path = "C:\Program Files (x86)\Google\Chrome\Application\chrome.exe")
#下面的代码是使用无界面模式
browser = webdriver.Chrome(chrome_options=chrome_options)
#browser = webdriver.Chrome()
print("xiaojie")
url="https://passport.csdn.net/account/login"
try:
browser.get(url)
data=browser.page_source
print (len(data))
curpage_url=browser.current_url
print (curpage_url) target=browser.find_element_by_xpath('/html/body/div[3]/div/div/div[2]/div/h3/a')
print("target:",target)
target.click() locator=(By.ID,'username')
WebDriverWait(browser, 20, 0.5).until(EC.presence_of_element_located(locator))
username=browser.find_element_by_id('username')
print ("username:",username)
time.sleep(3)
username.clear()
username.send_keys('183247166@qq.com') password=browser.find_element_by_id('password')
print ("password:",password)
password.clear()
password.send_keys('xxx') submit=browser.find_element_by_xpath('//*[@id="fm1"]/input[8]')
print ("submit:",submit)
submit.click()
curpage_url=browser.current_url
print (curpage_url)
#time.sleep(10)#不用等待页面刷新。这步操作是不需要的。 #保存cookie信息。
cookie =[item["name"] + ":" + item["value"] for item in browser.get_cookies()]
print (cookie)
cookiestr = ';'.join(item for item in cookie) #使用urllib爬取网页
#下面的代码并不能成功执行。
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5193.400 QQBrowser/10.0.1066.400",
"cookie":cookiestr
}
url2="https://download.csdn.net/my"#这是从网页登录以后,才能进入的个人空间。 try:
req=urllib.request.Request(url2,headers=headers)
response=urllib.request.urlopen(req)
data=response.read()
print("开始爬网页")
fhandle=open("./验证cookie能使用的网页,断网打开.html","wb")
fhandle.write(data)
fhandle.close()
print ("验证cookie能使用的网页,断网打开.html已经成功生成")
except HTTPError as e:
print("出现HTTP异常")
print(e.code)
print(e.reason)
except URLError as e:
print("出现URL异常")
print(e.reason)
except Exception as e:
print("driver出现异常")
print (e)
finally:
browser.close()
print("over")
None
结果还是不行。具体原因有待研究。
4 使用Selenium模拟登录csdn,取出cookie信息,再用requests.session访问个人中心(保持登录状态)的更多相关文章
- Andriod中WebView加载登录界面获取Cookie信息并同步保存,使第二次不用登录也可查看个人信息。
Android使用WebView加载登录的html界面,则通过登录成功获取Cookie并同步,可以是下一次不用登录也可以查看到个人信息,注:如果初始化加载登录,可通过缓存Cookie信息来验证是否要加 ...
- Python爬虫 —— 知乎之selenium模拟登陆获取cookies+requests.Session()访问+session序列化
代码如下: # coding:utf-8 from selenium import webdriver import requests import sys import time from lxml ...
- python使用selenium、PhantomJS获得网站cookie信息#windows
首先python安装selenium,命令行中输入 pip install selenium 在执行代码如下代码时出现错误 driver=webdriver.PhantomJS() 错误如下 sele ...
- Andriod的Http请求获取Cookie信息并同步保存,使第二次不用登录也可查看个人信息
Android使用Http请求登录,则通过登录成功获取Cookie信息并同步,可以是下一次不用登录也可以查看到个人信息, 注:如果初始化加载登录,可通过缓存Cookie信息来验证是否要加载登录界面.C ...
- Fiddler-005-获取 Cookie 信息
随着网络安全(例如:登录安全等)要求的不断提升,越来越多的登录应用在登录时添加了验证码登录,而验证码生成算法也在不断的进化,因而对含登录态的自动化测试脚本运行造成了一定程度的困扰,目前解决此种问题的方 ...
- 获取cookie信息
随着网络安全(例如:登录安全等)要求的不断提升,越来越多的登录应用在登录时添加了验证码登录,而验证码生成算法也在不断的进化,因而对含登录态的自动化测试脚本运行造成了一定程度的困扰,目前解决此种问题的方 ...
- fiddle-获取 Cookie 信息
随着网络安全(例如:登录安全等)要求的不断提升,越来越多的登录应用在登录时添加了验证码登录,而验证码生成算法也在不断的进化,因而对含登录态的自动化测试脚本运行造成了一定程度的困扰,目前解决此种问题的方 ...
- jmeter-登录获取cookie后参数化,或手动添加cookie, 再进行并发测试
以下情况其实并不适用于直接登录可以获取cookie情况,直接可以登录成功,直接添加cookie管理,cookie可以直接使用用于以下请求操作. 如果登录一次后,后续许多操作,可以将cookie管理器放 ...
- 用session实现的用户登陆,客户端是怎样获取到cookie信息的
大家都知道cookie是存在客户端,session存在服务器端.那么客户端具体是怎样获取cookie信息的呢? 更好的阅读体验可访问 这里. 实验环境 实验环境:xampp + Thinkphp5 + ...
随机推荐
- (转)【干货】MySQL 5.7 多实例(多进程)配置教程
原文:https://blog.csdn.net/zougen/article/details/79567744 https://klionsec.github.io/2017/09/20/mysql ...
- php array_flip() 删除数组重复元素
在PHP中,用于删除数组中重复元素有一个可用的函数,那就是 array_unique(), 但是它并不是一个最高效的方法,使用array_flip() 函数将比array_uniqure()在速度上高 ...
- PHP 判断字符串 是否 包含另一个字符串
1.stristr 忽略大小写 $string = 'Hello World!'; if(stristr($string, 'earth') === FALSE) { echo '"eart ...
- redis 远程 访问 安全配置
朋友总结很好,就转载了-> 站长博客 假设两台redis服务器,ip分别为:192.168.1.101和192.168.1.103,如果在101上通过redis-cli访问103上的redis呢 ...
- django notes 七:Using Forms
form 也没什么可说的,我只给一个例子大家就懂了 form model from django import forms class UserForm(forms.Form): username = ...
- 运维监控之zabbix(yum安装)
简介 zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案. zabbix能监视各种网络参数,保证服务器系统的安全运营:并提供灵活的通知机制以让系统管理员快速定位 ...
- 理解Python语言里的异常(Exception)
Exception is as a sort of structured "super go to".异常是一种结构化的"超级goto". 作为一个数十年如一日 ...
- Nginx教程(6) 动静分离架构
一.原理 Nginx 动静分离简单来说就是把动态跟静态请求分开,不能理解成只是单纯的把动态页面和静态页面物理分离.严格意义上说应该是动态请求跟静态请求分开,可以理解成使用Nginx 处理静态页面,To ...
- Spring----有关bean的配置
1.单例类的配置如果我们想创建一个单例类的bean,只能会通过静态工厂来创建.下图为一个单例类: Stage并没有提供公开的构造方法,构造方法都是私有的,必须通过getInstance()方法获得已经 ...
- MFC—— AfxMessageBox
AfxMessageBox 错误C2665: “AfxMessageBox”: 2 个重载中没有一个可以转换所有参数类型 1,楼主发表于:2007-01-01 03:56:34同样的语句, ...