在pycharm中使用scrapy爬虫
目标在Win7上建立一个Scrapy爬虫项目,以及对其进行基本操作。运行环境:电脑上已经安装了python(环境变量path已经设置好),
以及scrapy模块,IDE为Pycharm 。操作如下:
一、建立Scrapy模板。进入自己的工作目录,shift + 鼠标右键进入命令行模式,在命令行模式下,
输入scrapy startproject 项目名 ,如下:

看到以上的代码说明项目已经在工作目录中建好了。
二、在Pycharm中scrapy的导入。在Pycharm中打开工作目录中的TestDemo,点击File-> Settings->Project: TestDemo->Project Interpreter。
法一: 如图,
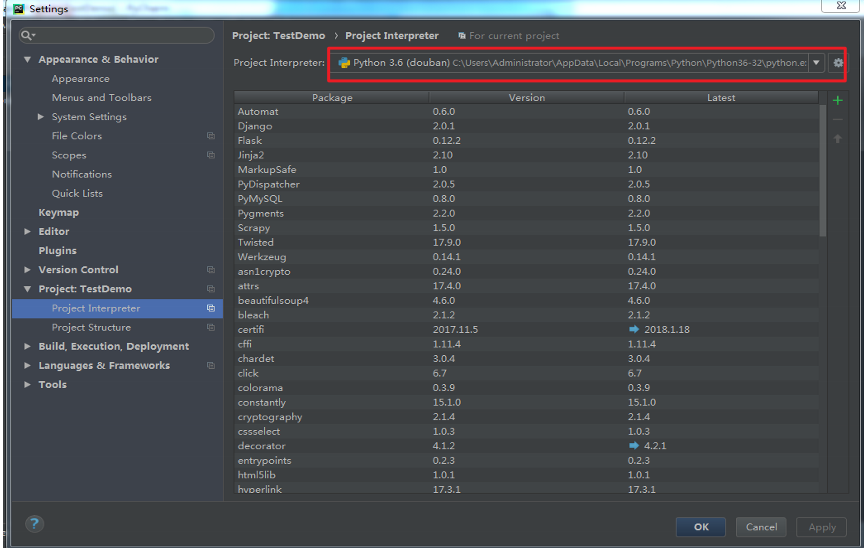
选择红框中右边的下拉菜单点击Show All, 如图:
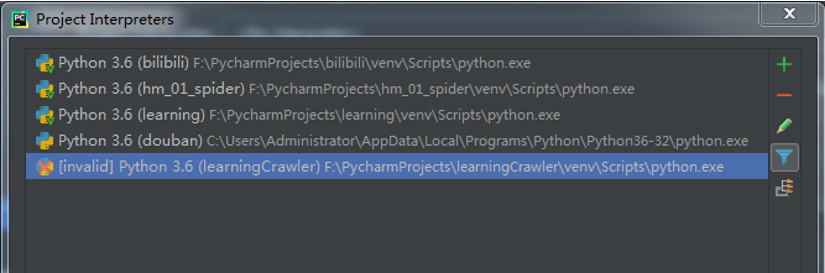
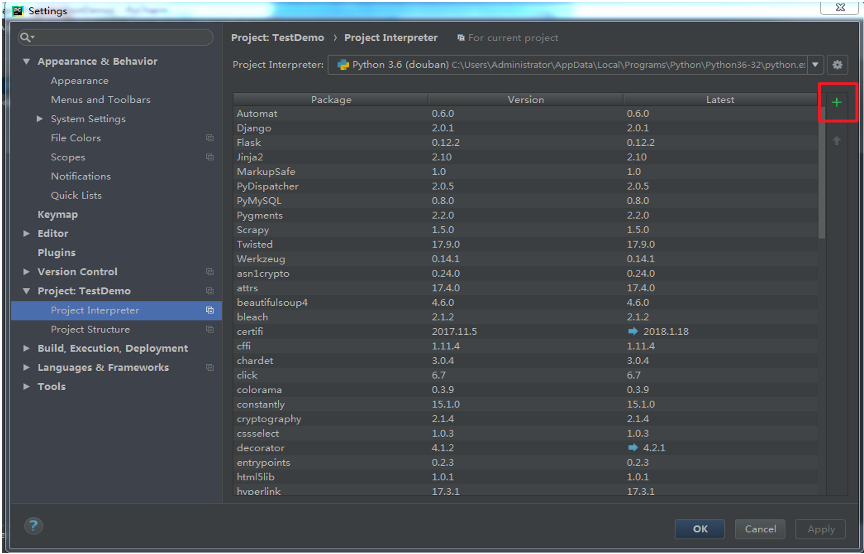
点击右上角加号,如图:
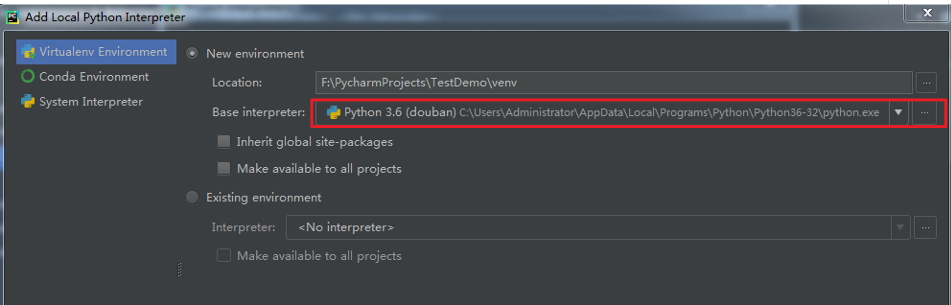
在红色框体内找到电脑里已经安装的python,比如我的是:
C:\Users\Administrator\AppData\Local\Programs\Python\Python36-32\python.exe , 导入即可。
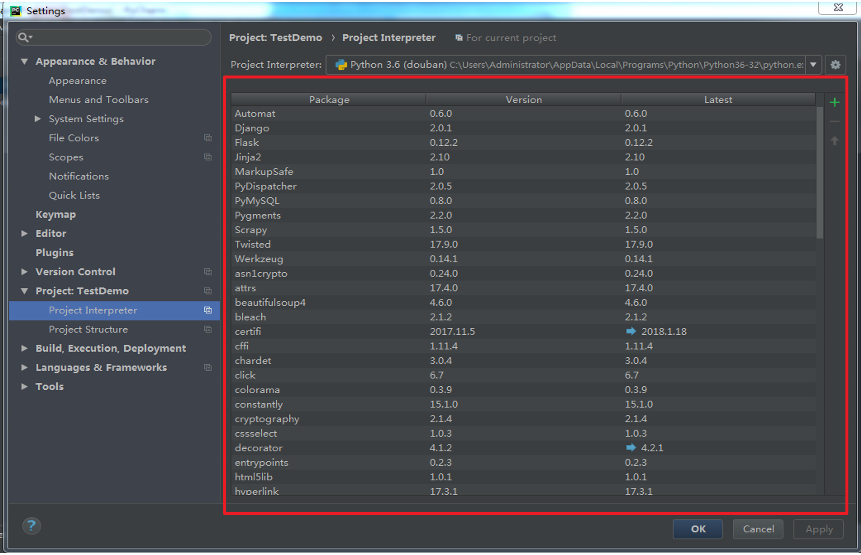
之后,pycharm会自动导入你已经在电脑上安装的scrapy等模块。如图,即红色框体中显示的。
法二:一个不那么麻烦的方法。如图:
点击红色框体,在弹出的框体内另安装一个scrapy, 如图:

需要安装的模块,如图:

模块自下而上进行安装,其中可能出现twisted包不能成功安装,出现
Failed building wheel for Twisted
Microsoft Visual C++ 14.0 is required...
的现象,那就搜一解决方案,这里不多说了。
三、Pycharm中scrapy的运行设置。
Tips:在创建爬虫时使用模板更加方便一些,如:
scrapy genspider [-t template] <name> <domain> 即:scrapy genspider testDemoSpider baidu.com
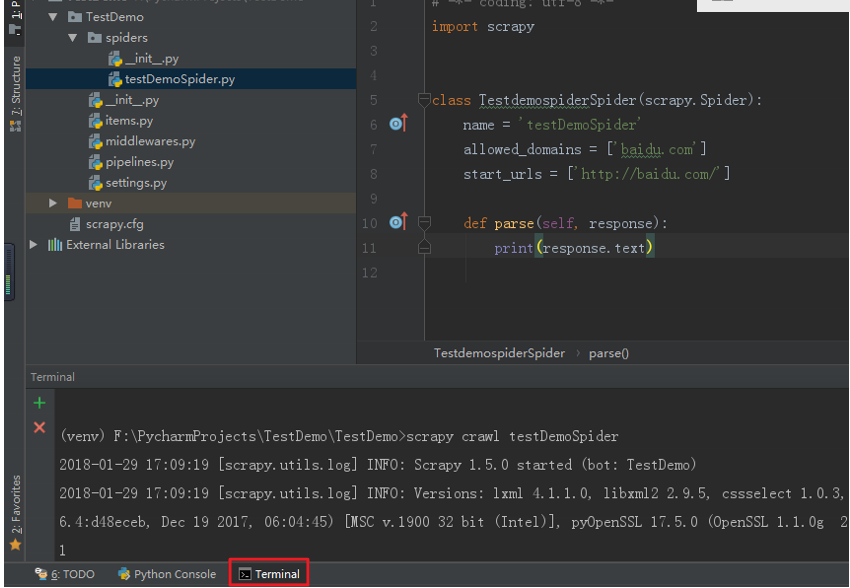
运行爬虫:
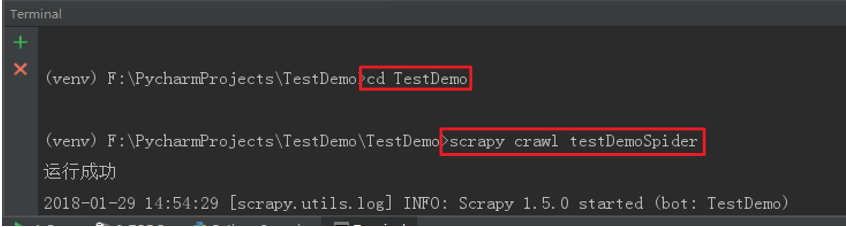
法一:Scrapy爬虫的运行需要到命令行下运行,在pychram中左下角有个Terminal,点开就可以在Pycharm下进入命令行,默认
是在项目目录下的,要运行项目,需要进入下一层目录,使用cd TestDemo 进入下一层目录,然后用scrapy crawl 爬虫名 , 即可运行爬虫。
如图:
法二:在TestDemoSpider目录和scrapy.cfg同级目录下面,新建一个entrypoint.py文件,如图:
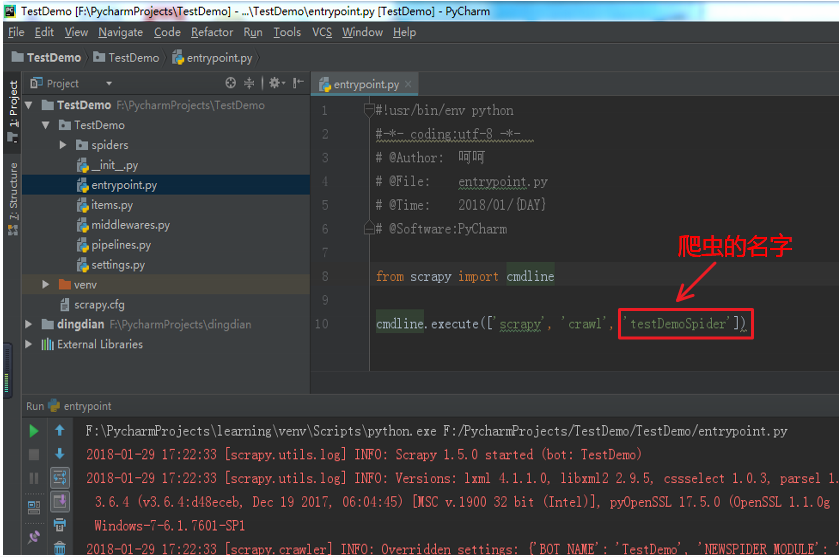
其中只需把红色框体内的内容改成相应的爬虫的名字就可以在不同的爬虫项目中使用了,直接运行该文件就能使得Scrapy爬虫运行
在pycharm中使用scrapy爬虫的更多相关文章
- 在Pycharm中运行Scrapy爬虫项目的基本操作
目标在Win7上建立一个Scrapy爬虫项目,以及对其进行基本操作.运行环境:电脑上已经安装了python(环境变量path已经设置好), 以及scrapy模块,IDE为Pycharm .操作如下: ...
- win10在Pycharm中安装scrapy
查看官网说明 发现推荐是安装Anaconda 或 Miniconda,这东西有点大而全,感觉目前用不上.所以没这样做. 直接安装scrapy 如果直接装会报错的,参考文章就可以解决. 这里记一下组件下 ...
- Pycharm中的scrapy安装教程
在利用pycharm安装scrapy包是遇到了挺多的问题.在折腾了差不多折腾了两个小时之后总算是安装好了.期间各种谷歌和百度,发现所有的教程都是利用命令行窗口安装的.发现安装scrapy需要的包真是多 ...
- 用Scrapy爬虫下载图片(豆瓣电影图片)
用Scrapy爬虫的安装和入门教程,这里有,这篇链接的博客也是我这篇博客的基础. 其实我完全可以直接在上面那篇博客中的代码中直接加入我要下载图片的部分代码的,但是由于上述博客中的代码已运行,已爬到快九 ...
- #0 scrapy爬虫学习中遇到的坑记录
python 基础学习中对于scrapy的使用遇到了一些问题. 首先进行的是对Amazon.cn的检索结果页进行爬取,很顺利,无碍. 下一个目标是对baidu的搜索结果进行爬取 1,反爬虫 1.1 我 ...
- 如何在vscode中调试python scrapy爬虫
本文环境为 Win10 64bit+VS Code+Python3.6,步骤简单罗列下,此方法可以不用单独建一个Py入口来调用命令行 安装Python,从官网下载,过程略,这里主要注意将python目 ...
- Scrapy爬虫框架中的两个流程
下面对比了Scrapy爬虫框架中的两个流程—— ① Scrapy框架的基本运作流程:② Spider或其子类的几个方法的执行流程. 这两个流程是互相联系的,可对比学习. 1 ● Scrapy框架的基本 ...
- scrapy爬虫,cmd中执行日志中显示了爬取的内容,但是运行时隐藏日志后(运行命令后添加--nolog),就没有输出结果了
cmd下执行scrapy爬虫程序,不报错也没有输出,解决方案 想要执行parse能够在cmd看到parse函数的执行结果: 解决方法: settings.py 中设置 ROBOTSTXT_OBEY ...
- 【Python】在Pycharm中安装爬虫库requests , BeautifulSoup , lxml 的解决方法
BeautifulSoup在学习Python过程中可能需要用到一些爬虫库 例如:requests BeautifulSoup和lxml库 前面的两个库,用Pychram都可以通过 File--> ...
随机推荐
- MySQL数据库实验:任务二 表数据的插入、修改及删除
目录 任务二 表数据的插入.修改及删除 一.利用界面工具插入数据 二.数据更新 (一)利用MySQL命令行窗口更新数据 (二)利用Navicat for MySQL客户端工具更新数据 三.数据库的备份 ...
- 定时任务crond服务
crond 什么是? crond 是linux系统中用于定期执行命令或指定程序任务的服务.一般情况下,安装完系统操作之后,默认会启动任务调度服务. linux调度任务的工作可以分为两类: 系统自身执行 ...
- 推荐一个学习Flex chart的好网站
推荐一个学习Flex chart的好网站 2013-03-04 14:16:56| 分类: Flex | 标签: |字号大中小 订阅 推荐一个学习Flex chart的好网站 最近在做一个 ...
- 与Linux的第一次遭遇
我的与linux首次遭遇战 虚拟机安装 安装虚拟机我遇到的问题个数可以缩减到1--我几乎没遇到安装虚拟机的问题!我严格按照老师给的链接去下载那个VirtualBox,尽管那个网页是全英文的,但是我像看 ...
- css首行缩进2个字符
css设置: p{ text-indent:2em; }
- 从原理到代码:大牛教你如何用 TensorFlow 亲手搭建一套图像识别模块 | AI 研习社
从原理到代码:大牛教你如何用 TensorFlow 亲手搭建一套图像识别模块 | AI 研习社 PPT链接: https://pan.baidu.com/s/1i5Jrr1N 视频链接: https: ...
- cogs696 longest prefix
cogs696 longest prefix 原题链接 IOI1996原题? 其实这题我不会. map+string+手动氧气大法好 //就是这么皮(滑稽 Code // It is made by ...
- C#是数据类型
C#又开始了 开始数据类型 用的软件是VS2017 E short 短整型 int 中等整型 long 长整形 string 字符串类型 bool 布尔类型(true/flase) 相当于数 ...
- 我们一起学习WCF 第五篇数据协定和消息协定
A:数据协定(“数据协定”是在服务与客户端之间达成的正式协议,用于以抽象方式描述要交换的数据. 也就是说,为了进行通信,客户端和服务不必共享相同的类型,而只需共享相同的数据协定. 数据协定为每个参数或 ...
- 学习HTML 第四节.插入图像
学习HTML 第四节.插入图像 全是文字的网页太枯燥了吧,我们来搞个图片上去! <!DOCTYPE html><html><head><meta charse ...