分布式数据库主键id生成策略
分布式数据库部署主要分为两种,一种是读写分离。这个需要弄主从数据库。主要是写的时候写主数据库,读的时候读从数据库。分散读取压力,对于读多写少的系统有利于
提高其性能。还有一种是分布式存储,这种主要是将一张表拆分成多张分表部署到各个服务器中,主要针对写操作频繁的系统,如微博,淘宝的订单系统。
这两种方案都会遇到主键类型及生成方式的问题,还有主从数据库不同步和主键冲突问题。
主键类型主要有GUID和数字类型,这里我们不讨论GUID;
数字主键主要存在唯一性、可同步性两个方面的不足
可同步性:可以不使用主键自增方案。
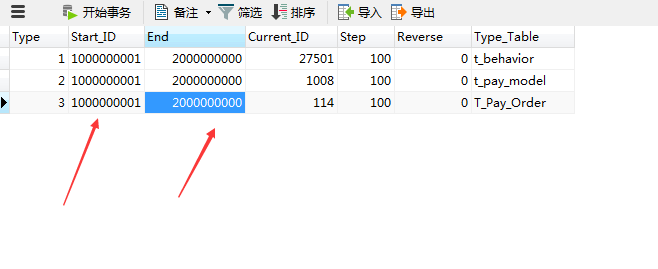
唯一性:可以单独使用存储过程生成ID,设置主键ID的初始值步长和最大值,及所对应的表,当然主从数据库的主表和分表初始值和最大值是不一样的,一样的话会造成主键重复。
存储过程:
-- ----------------------------
-- Procedure structure for getId
-- ----------------------------
DROP PROCEDURE IF EXISTS `getId`;
DELIMITER ;;
CREATE DEFINER=`sawyer`@`%` PROCEDURE `getId`(OUT aId INT, OUT aIdEnd INT, aType TINYINT)
BEGIN
DECLARE id,eid,iStep INT;
DECLARE rev TINYINT;
SELECT Current_ID,END,Step,REVERSE INTO id,eid,iStep,rev FROM t_id WHERE TYPE=aType;
IF id<eid THEN
SET aId = id;
IF id+iStep >= eid THEN
SET aIdEnd = eid;
IF rev = 1 THEN
UPDATE t_id SET Current_ID=Start_ID WHERE TYPE=aType;
ELSE
UPDATE t_id SET Current_ID=eid WHERE TYPE=aType;
END IF;
ELSE
SET aIdEnd = id+iStep;
UPDATE t_id SET Current_ID=aIdEnd WHERE TYPE=aType;
END IF;
ELSE
SET aId = 0, aIdEnd = 0;
END IF;
END
;;
DELIMITER ;
主表
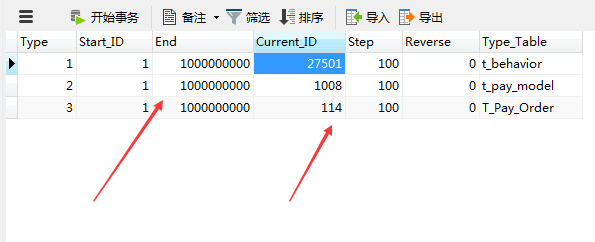
从表
写一个java类去调用这个存储过程生成主键。
/* */ package btir.dao.jdbc;
/* */
/* */ import btir.BtirException;
/* */ import btir.dao.ha.DBMgr;
/* */ import btir.dao.ha.PooledStmt;
/* */ import btir.utils.MiscUtil;
/* */ import org.apache.commons.logging.Log;
/* */ import org.apache.commons.logging.LogFactory;
/* */
/* */
/* */
/* */
/* */
/* */
/* */
/* */ public class IdHolder
/* */ {
/* */ public static final int NO_ID_AVAILABLE = 0;
/* 19 */ private static final Log log = LogFactory.getLog(IdHolder.class);
/* */
/* */
/* */
/* */ private int current;
/* */
/* */
/* */ private int end;
/* */
/* */
/* */
/* */ public synchronized int getId(byte type, int stmtId)
/* */ {
/* 32 */ if (end <= current)
/* */ {
/* */ try
/* */ {
/* 36 */ PooledStmt stmt = DBMgr.borrowSingleStmt(stmtId);
/* */
/* */
/* 39 */ stmt.setByte(3, type);
/* 40 */ stmt.executeUpdate();
/* 41 */ current = stmt.getInt(1);
/* 42 */ end = stmt.getInt(2);
/* 43 */ stmt.returnMe();
/* */ } catch (BtirException e) {
/* 45 */ current = (end = 0);
/* 46 */ log.error("can't get id for type=" + type);
/* 47 */ log.error(MiscUtil.traceInfo(e));
/* 48 */ return 0;
/* */ }
/* 50 */ if (end <= current)
/* 51 */ return 0;
/* */ }
/* 53 */ return current++;
/* */ }
/* */
/* */ public synchronized int getId(byte type, PooledStmt stmt) {
/* 57 */ if (end <= current) {
/* */ try {
/* 59 */ stmt.setByte(3, type);
/* 60 */ stmt.executeUpdate();
/* 61 */ current = stmt.getInt(1);
/* 62 */ end = stmt.getInt(2);
/* */ } catch (BtirException e) {
/* 64 */ current = (end = 0);
/* 65 */ return 0;
/* */ }
/* 67 */ if (end <= current)
/* 68 */ return 0;
/* */ }
/* 70 */ return current++;
/* */ }
/* */ }
上面这段代码主要是调用存储过程,对应配置的表的ID自增。。。
分布式数据库主键id生成策略的更多相关文章
- 数据库主键ID生成策略
前言: 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,下面介绍一些常见的ID生成策略. Sequence ID UUID GUID COMB Snowflake 最开始的自增ID为了实现分库 ...
- 数据库分库分表(一)常见分布式主键ID生成策略
主键生成策略 系统唯一ID是我们在设计一个系统的时候常常会遇见的问题,下面介绍一些常见的ID生成策略. Sequence ID UUID GUID COMB Snowflake 最开始的自增ID为了实 ...
- mybatis 针对SQL Server 的 主键id生成策略
SQL Server中命令: select newId() ,可以得到SQL server数据库原生的UUID值,因此我们可以将这条指令写到 Mybatis的主键生成策略配置selectKey中. ...
- Hibernate系列之ID生成策略
一.概述 hibernate中使用两种方式实现主键生成策略,分别是XML生成id和注解方式(@GeneratedValue),下面逐一进行总结. 二.XML配置方法 这种方式是在XX.hbm.xml文 ...
- JPA ID生成策略(转---)
尊重原创:http://tendyming.iteye.com/blog/2024985 JPA ID生成策略 @Table Table用来定义entity主表的name,catalog,schema ...
- 分库分表的 9种分布式主键ID 生成方案,挺全乎的
<sharding-jdbc 分库分表的 4种分片策略> 中我们介绍了 sharding-jdbc 4种分片策略的使用场景,可以满足基础的分片功能开发,这篇我们来看看分库分表后,应该如何为 ...
- hibernate(四)ID生成策略
一.ID生成策略配置 1.ID生成方式在xml中配置方式: <?xml version="1.0"?> <!DOCTYPE hibernate-mapping P ...
- 业务ID 生成策略
业务ID 生成策略,从技术上说,基本要借助一个集中式的引擎来帮忙实现. 为了扩大业务ID生成策略的并发问题,还有更为技巧性的提升. 先来介绍普遍的分布式ID生成策略: 1. 利用DB的自增主键 这里又 ...
- Rhythmk 学习 Hibernate 03 - Hibernate 之 延时加载 以及 ID 生成策略
Hibernate 加载数据 有get,跟Load 1.懒加载: 使用session.load(type,id)获取对象,并不读取数据库,只有在使用返回对象值才正真去查询数据库. @Test publ ...
随机推荐
- android onSaveInstance方法
为什么需要用到Activity状态保存, 如何用 ? 1)我们希望当前的Activity中的信息不会因为Activity状态的改变,而丢失.比如横竖屏的切换,突然来了个电话. 2) 借助Activit ...
- cs108 04 oop design
oop design 分为以下几个方面: - encapsulation and modularity(封装和模块化) - API/Client interface design(API 接口给调用类 ...
- Geometric deep learning on graphs and manifolds using mixture model CNNs
Monti, Federico, et al. "Geometric deep learning on graphs and manifolds using mixture model CN ...
- tensorflow函数解析:Session.run和Tensor.eval的区别
tensorflow函数解析:Session.run和Tensor.eval 翻译 2017年04月20日 15:05:50 标签: tensorflow / 机器学习 / 深度学习 / python ...
- Spring零散所得
Spring容器中bean的id或name,都可以有多个,且第一个为标识符(Qualifier),其余皆为别名(Alias).所以都可以通过applicationContext.getBean(&qu ...
- C++ 类 & 对象
C++ 类 & 对象C++ 在 C 语言的基础上增加了面向对象编程,C++ 支持面向对象程序设计.类是 C++ 的核心特性,通常被称为用户定义的类型. 类用于指定对象的形式,它包含了数据表示法 ...
- jquery中判断选择器,找没找到元素用$().size()==0
jquery中判断选择器,找没找到元素用$().size()==0
- MathType中公式不对齐怎么办
MathType是一款专门用来编辑数学公式的数学公式编辑器,利用它可以在文档中快速编辑公式,与文字完美结合,可以编辑出各种各样的数学符号与公式,省下你不少的时间. 一.对齐上标与下标 MathType ...
- Java中的各种加密算法
Java中为我们提供了丰富的加密技术,可以基本的分为单向加密和非对称加密 1.单向加密算法 单向加密算法主要用来验证数据传输的过程中,是否被篡改过. BASE64 严格地说,属于编码格式,而非加密算法 ...
- [转]ASP.NET MVC 5 - 创建连接字符串(Connection String)并使用SQL Server LocalDB
您创建的MovieDBContext类负责处理连接到数据库,并将Movie对象映射到数据库记录的任务中.你可能会问一个问题,如何指定它将连接到数据库? 实际上,确实没有指定要使用的数据库,Entity ...