机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩
第二种类型的 无监督学习问题,称为 降维。有几个不同的的原因使你可能想要做降维。一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快我们的学习算法。
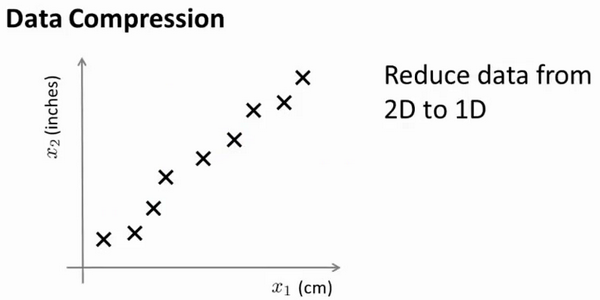
但首先,让我们谈论 降维是什么。作为一种生动的例子,我们收集的数据集,有许多,许多特征,我绘制两个在这里。
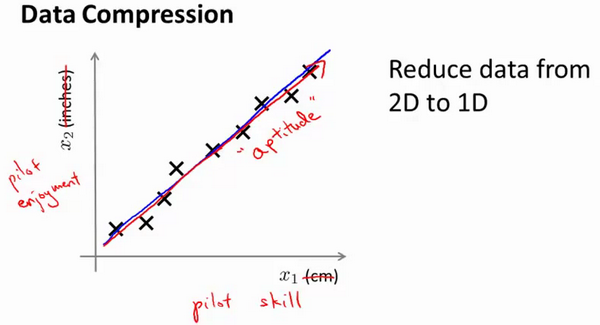
将数据从二维降一维:

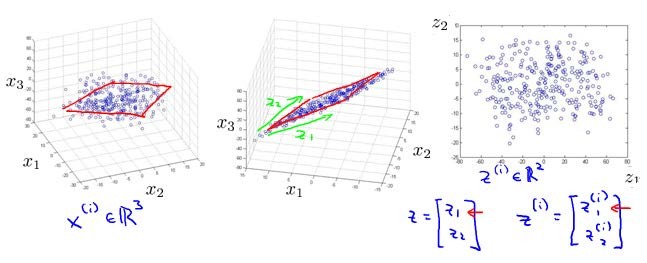
将数据从三维降至二维: 这个例子中我们要将一个三维的特征向量降至一个二维的特征向量。过程是与上面类似的,我们将三维向量投射到一个二维的平面上,强迫使得所有的数据都在同一个平面上,降至二维的特征向量。
这样的处理过程可以被用于把任何维度的数据降到任何想要的维度,例如将1000维的特征降至100维。
2. 动机二:数据可视化
在许多及其学习问题中,如果我们能将数据可视化,我们便能寻找到一个更好的解决方案,降维可以帮助我们。
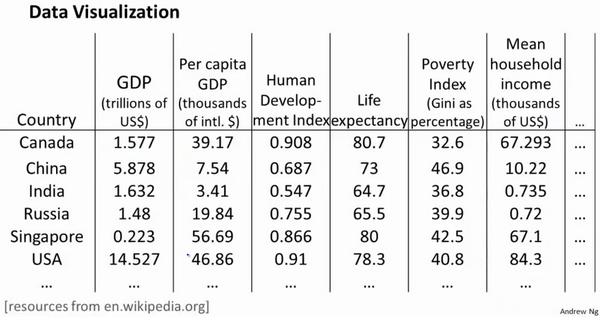
假使我们有有关于许多不同国家的数据,每一个特征向量都有50个特征(如GDP,人均GDP,平均寿命等)。
如果要将这个50维的数据可视化是不可能的。使用降维的方法将其降至2维,我们便可以将其可视化了。
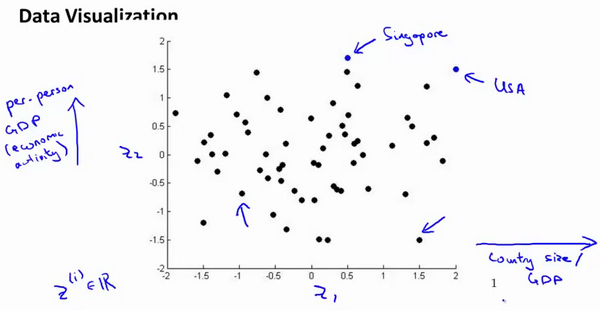
这样做的问题在于,降维的算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现了。
3. 主成分分析问题
主成分分析(PCA)是最常见的降维算法。
在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望 投射平均均方误差 能尽可能地小。
方向向量:是一个经过原点的向量,而 投射误差 是 从特征向量 向该方向向量作垂线的长度。
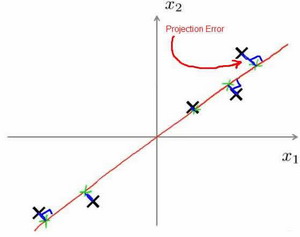
下面给出主成分分析问题的描述:
问题:将n维数据降至k维,目标是找到向量 $u^{(1)},u^{(2)},...,u^{(k)}$ 使得 总的投射误差最小。主成分分析与线性回顾的比较:
主成分分析与线性回归是两种不同的算法。主成分分析最小化的是 投射误差(Projected Error),而线性回归尝试的是最小化:预测误差。线性回归的目的是 预测结果,而主成分分析 不作任何预测。
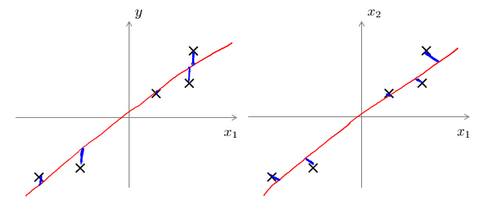
上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)。
PCA:将n个特征降维到k个,可以用来进行数据压缩,如果100维的向量最后可以用10维来表示,那么压缩率为90%。同样图像处理领域的KL变换使用PCA做图像压缩。但PCA 要保证降维后,还要保证数据的特性损失最小。
PCA技术好处:是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
PCA技术优点:它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数 或是 根据任何经验模型对计算进行干预,最后的 结果只与数据相关,与用户是独立的。
但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
4. 主成分分析算法
第一步:均值归一化。
- 我们需要计算出所有特征的均值,然后令 $x_j= x_j-μ_j$。如果特征是在不同的数量级上,我们还需要将其除以 标准差 $σ^2$。
第二步:计算 协方差矩阵(covariance matrix)Σ:
- $\sum=\dfrac {1}{m}\sum^{n}_{i=1}\left( x^{(i)}\right) \left( x^{(i)}\right) ^{T}$
第三步:计算 协方差矩阵Σ 的 特征向量(eigenvectors):
在 Matlab 里我们可以利用 奇异值分解(singular value decomposition)来求解,[U, S, V]= svd(sigma) 。


机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)的更多相关文章
- Stanford机器学习笔记-10. 降维(Dimensionality Reduction)
10. Dimensionality Reduction Content 10. Dimensionality Reduction 10.1 Motivation 10.1.1 Motivation ...
- 机器学习(十)-------- 降维(Dimensionality Reduction)
降维(Dimensionality Reduction) 降维的目的:1 数据压缩 这个是二维降一维 三维降二维就是落在一个平面上. 2 数据可视化 降维的算法只负责减少维数,新产生的特征的意义就必须 ...
- 数据降维(Dimensionality reduction)
数据降维(Dimensionality reduction) 应用范围 无监督学习 图片压缩(需要的时候在还原回来) 数据压缩 数据可视化 数据压缩(Data Compression) 将高维的数据转 ...
- [C9] 降维(Dimensionality Reduction)
降维(Dimensionality Reduction) 动机一:数据压缩(Motivation I : Data Compression) 数据压缩允许我们压缩数据,从而使用较少的计算机内存或磁盘空 ...
- 海量数据挖掘MMDS week4: 推荐系统之数据降维Dimensionality Reduction
http://blog.csdn.net/pipisorry/article/details/49231919 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 斯坦福第十四课:降维(Dimensionality Reduction)
14.1 动机一:数据压缩 14.2 动机二:数据可视化 14.3 主成分分析问题 14.4 主成分分析算法 14.5 选择主成分的数量 14.6 重建的压缩表示 14.7 主成分分析法 ...
- 机器学习课程-第8周-聚类(Clustering)—K-Mean算法
1. 聚类(Clustering) 1.1 无监督学习: 简介 在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签 ...
- 机器学习课程-第7周-支持向量机(Support Vector Machines)
1. 优化目标 在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法A还是学习算法B,而更重要的是,应用这些算法时,所创建的大量数据在应用这些算法时,表现情况通常依赖于你的 ...
- Ng第十四课:降维(Dimensionality Reduction)
14.1 动机一:数据压缩 14.2 动机二:数据可视化 14.3 主成分分析问题 14.4 主成分分析算法 14.5 选择主成分的数量 14.6 重建的压缩表示 14.7 主成分分析法 ...
随机推荐
- Windows samba history
https://blogs.technet.microsoft.com/josebda/2013/10/02/windows-server-2012-r2-which-version-of-the-s ...
- An internal error has occurred. Java heap space
http://stackoverflow.com/questions/11001252/running-out-of-heap-space issue: I am having a heap spac ...
- [转帖]龙芯下一代处理器微结构GS464E细节曝光
龙芯下一代处理器微结构GS464E细节曝光 [日期:2015-05-26] 来源:Linux公社 作者:Linux [字体:大 中 小] http://www.linuxidc.com/Linux/ ...
- 软件工程_4th weeks
本周要进行阿尔法版本的发布,因此我们做了一些代码和测试方面的工作.当然了下了课后第一件事还是巩固课上讲的知识,比如MVP.四象限.看了演讲<最后一课>等. 一.结对编程 本周的结对编程继续 ...
- day13 for内部机制详解,迭代器
迭代器定义: 可迭代协议:含有iter方法的都是可以迭代的 迭代器协议: 有.next 方法,和iter的都是迭代器 必须存在终结 特点: 节省空间 方便逐个取值,一个迭代器只能取一次 简单来说:满足 ...
- c# Point不能输入小数
换成用 PointF PointF p = new PointF(116.305671f, 39.966051f); //6位小数后面要加f 表示转float,否则报错
- Android 视频 教程 源码 电子书 网址
资源名称 资源地址 下载量 好评率8天快速掌握Android视频教程67集(附源码)http://down.51cto.com/zt/2197 32157Android开发入门之实战技巧和源码 htt ...
- 【BZOJ2001】[HNOI2010]城市建设(CDQ分治,线段树分治)
[BZOJ2001][HNOI2010]城市建设(CDQ分治,线段树分治) 题面 BZOJ 洛谷 题解 好神仙啊这题.原来想做一直不会做(然而YCB神仙早就切了),今天来怒写一发. 很明显这个玩意换种 ...
- 洛谷 P2158 [SDOI2008]仪仗队 解题报告
P2158 [SDOI2008]仪仗队 题目描述 作为体育委员,C君负责这次运动会仪仗队的训练.仪仗队是由学生组成的N * N的方阵,为了保证队伍在行进中整齐划一,C君会跟在仪仗队的左后方,根据其视线 ...
- 前端学习 -- Html&Css -- 条件Hack 和属性Hack
条件Hack 语法: <!--[if <keywords>? IE <version>?]> HTML代码块 <![endif]--> <keyw ...