机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩
第二种类型的 无监督学习问题,称为 降维。有几个不同的的原因使你可能想要做降维。一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快我们的学习算法。
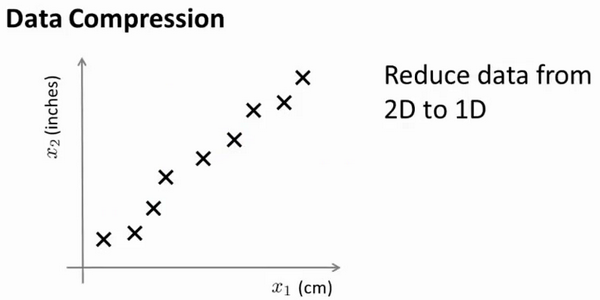
但首先,让我们谈论 降维是什么。作为一种生动的例子,我们收集的数据集,有许多,许多特征,我绘制两个在这里。
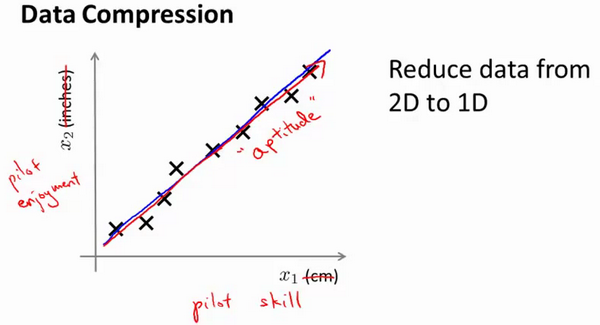
将数据从二维降一维:

将数据从三维降至二维: 这个例子中我们要将一个三维的特征向量降至一个二维的特征向量。过程是与上面类似的,我们将三维向量投射到一个二维的平面上,强迫使得所有的数据都在同一个平面上,降至二维的特征向量。
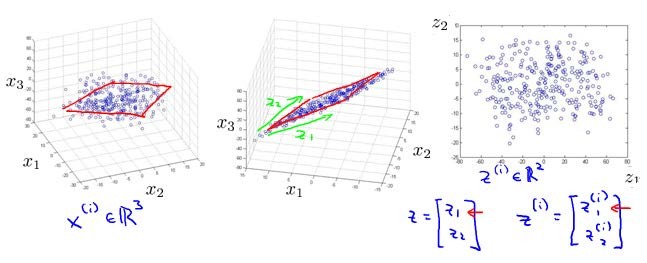
这样的处理过程可以被用于把任何维度的数据降到任何想要的维度,例如将1000维的特征降至100维。
2. 动机二:数据可视化
在许多及其学习问题中,如果我们能将数据可视化,我们便能寻找到一个更好的解决方案,降维可以帮助我们。
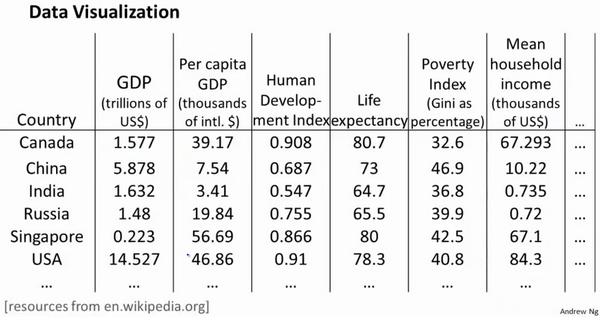
假使我们有有关于许多不同国家的数据,每一个特征向量都有50个特征(如GDP,人均GDP,平均寿命等)。
如果要将这个50维的数据可视化是不可能的。使用降维的方法将其降至2维,我们便可以将其可视化了。
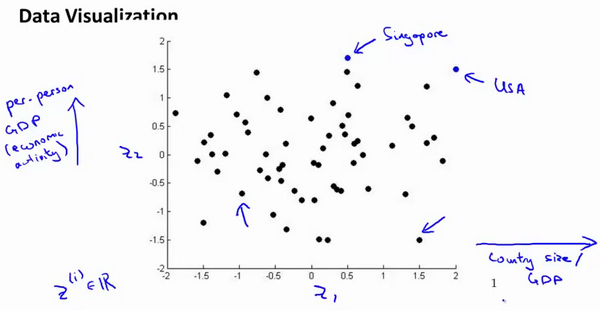
这样做的问题在于,降维的算法只负责减少维数,新产生的特征的意义就必须由我们自己去发现了。
3. 主成分分析问题
主成分分析(PCA)是最常见的降维算法。
在PCA中,我们要做的是找到一个方向向量(Vector direction),当我们把所有的数据都投射到该向量上时,我们希望 投射平均均方误差 能尽可能地小。
方向向量:是一个经过原点的向量,而 投射误差 是 从特征向量 向该方向向量作垂线的长度。
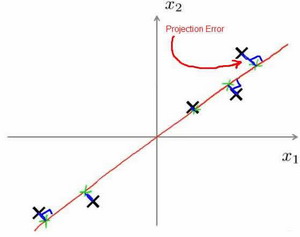
下面给出主成分分析问题的描述:
问题:将n维数据降至k维,目标是找到向量 $u^{(1)},u^{(2)},...,u^{(k)}$ 使得 总的投射误差最小。主成分分析与线性回顾的比较:
主成分分析与线性回归是两种不同的算法。主成分分析最小化的是 投射误差(Projected Error),而线性回归尝试的是最小化:预测误差。线性回归的目的是 预测结果,而主成分分析 不作任何预测。
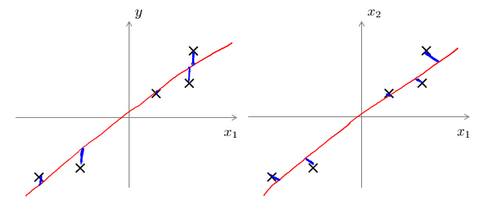
上图中,左边的是线性回归的误差(垂直于横轴投影),右边则是主要成分分析的误差(垂直于红线投影)。
PCA:将n个特征降维到k个,可以用来进行数据压缩,如果100维的向量最后可以用10维来表示,那么压缩率为90%。同样图像处理领域的KL变换使用PCA做图像压缩。但PCA 要保证降维后,还要保证数据的特性损失最小。
PCA技术好处:是对数据进行降维的处理。我们可以对新求出的“主元”向量的重要性进行排序,根据需要取前面最重要的部分,将后面的维数省去,可以达到降维从而简化模型或是对数据进行压缩的效果。同时最大程度的保持了原有数据的信息。
PCA技术优点:它是完全无参数限制的。在PCA的计算过程中完全不需要人为的设定参数 或是 根据任何经验模型对计算进行干预,最后的 结果只与数据相关,与用户是独立的。
但是,这一点同时也可以看作是缺点。如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果,效率也不高。
4. 主成分分析算法
第一步:均值归一化。
- 我们需要计算出所有特征的均值,然后令 $x_j= x_j-μ_j$。如果特征是在不同的数量级上,我们还需要将其除以 标准差 $σ^2$。
第二步:计算 协方差矩阵(covariance matrix)Σ:
- $\sum=\dfrac {1}{m}\sum^{n}_{i=1}\left( x^{(i)}\right) \left( x^{(i)}\right) ^{T}$
第三步:计算 协方差矩阵Σ 的 特征向量(eigenvectors):
在 Matlab 里我们可以利用 奇异值分解(singular value decomposition)来求解,[U, S, V]= svd(sigma) 。


机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)的更多相关文章
- Stanford机器学习笔记-10. 降维(Dimensionality Reduction)
10. Dimensionality Reduction Content 10. Dimensionality Reduction 10.1 Motivation 10.1.1 Motivation ...
- 机器学习(十)-------- 降维(Dimensionality Reduction)
降维(Dimensionality Reduction) 降维的目的:1 数据压缩 这个是二维降一维 三维降二维就是落在一个平面上. 2 数据可视化 降维的算法只负责减少维数,新产生的特征的意义就必须 ...
- 数据降维(Dimensionality reduction)
数据降维(Dimensionality reduction) 应用范围 无监督学习 图片压缩(需要的时候在还原回来) 数据压缩 数据可视化 数据压缩(Data Compression) 将高维的数据转 ...
- [C9] 降维(Dimensionality Reduction)
降维(Dimensionality Reduction) 动机一:数据压缩(Motivation I : Data Compression) 数据压缩允许我们压缩数据,从而使用较少的计算机内存或磁盘空 ...
- 海量数据挖掘MMDS week4: 推荐系统之数据降维Dimensionality Reduction
http://blog.csdn.net/pipisorry/article/details/49231919 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 斯坦福第十四课:降维(Dimensionality Reduction)
14.1 动机一:数据压缩 14.2 动机二:数据可视化 14.3 主成分分析问题 14.4 主成分分析算法 14.5 选择主成分的数量 14.6 重建的压缩表示 14.7 主成分分析法 ...
- 机器学习课程-第8周-聚类(Clustering)—K-Mean算法
1. 聚类(Clustering) 1.1 无监督学习: 简介 在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签 ...
- 机器学习课程-第7周-支持向量机(Support Vector Machines)
1. 优化目标 在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法A还是学习算法B,而更重要的是,应用这些算法时,所创建的大量数据在应用这些算法时,表现情况通常依赖于你的 ...
- Ng第十四课:降维(Dimensionality Reduction)
14.1 动机一:数据压缩 14.2 动机二:数据可视化 14.3 主成分分析问题 14.4 主成分分析算法 14.5 选择主成分的数量 14.6 重建的压缩表示 14.7 主成分分析法 ...
随机推荐
- Red Hat 5.8 CentOS 6.5 共用 输入法
pick up from http://jingyan.baidu.com/article/20b68a885a3607796cec622c.html
- Web接口测试-HttpClient
要实现Web接口测试的自动化有许多方式,比如利用Jmeter.Loadrunner等测试工具都能够实现接口的自动化测试,我们也可以利用一些开源的框架来实现接口的自动化测试,比如我们现在要说的这个Htt ...
- session存入redis
Session信息入Redis Session简介 session,中文经常翻译为会话,其本来的含义是 指有始有终的一系列动作/消息,比如打电话时从拿起电话拨号到挂断电话这中间的一系列过程可以称之为一 ...
- idea for mac 最全快捷键整理
一.Mac键盘符号和修饰键说明 ⌘ Command ⇧Shift ⌥ Option ⌃ Control ↩︎ Return/Enter ⌫ Delete ⌦ 向前删除键(Fn+Delete) ↑ 上箭 ...
- js語句
js語句就是告訴瀏覽器要做什麼: js代碼就是js語句序列: js代碼塊就是{}包括的,函數就是一個代碼塊的典型例子: js注釋:單行注釋://,多行注釋:/**/ js對大小寫敏感: js語句可以不 ...
- python之hasattr、getattr和setattr函数
hasattr函数使用方法 # hasattr函数使用方法 # hasattr(object,attr) # 判断一个对象里是否有某个属性或方法,返回布尔值,有为True,否则False class ...
- Nginx CONTENT阶段 static模块
L63-65 alias指令 syntax: alias path;# 静态文件路径 alias不会将请求路径后的路径添加到 path中 context : location; root指令 sy ...
- 信息安全与Linux系统
相信很多小伙伴都看过黑客帝国里面的那些由代码组成的神奇界面,也有很多人也向往着有一天能做一个黑客,当然不是为了做坏事,只是想和电影里面的黑客一样拉风,我就是这么其中一个(假如有一天能实现这个愿望我想我 ...
- String在内存中如何存储(Java)
JDK1.8中JVM把String常量池移入了堆中,同时取消了“永久代”,改用元空间代替(Metaspace)java中对String对象特殊对待,所以在heap区域分成了两块,一块是字符串常量池(S ...
- BZOJ2135 刷题计划(贪心+二分)
相邻数作差后容易转化成将这些数最多再切m刀能获得的最小偏差值.大胆猜想化一波式子可以发现将一个数平均分是最优的.并且划分次数越多能获得的偏差值增量越小.那么就可以贪心了:将所有差扔进堆里,每次取出增量 ...