看到篇博文,用python pandas改写了下
看到篇博文,https://blog.csdn.net/young2415/article/details/82795688
需求是需要统计部门礼品数量,自己简单绘制了个表格,如下:
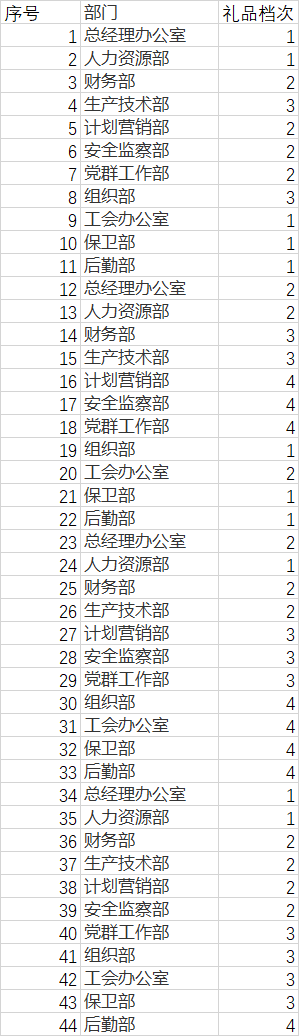

大意是,每个部门的员工发福利,有礼品档次(见表一),每个档次礼品对应不同礼品(见表二)
假设表一在test.xlsx的sheet1中,表二在test.xlsx的sheet2中,运算结果为同级目录下的result.xlsx,用python pandas改写代码如下:
import pandas as pd
df1 = pd.read_excel('test.xlsx', sheet_name=0, index_col='序号') # 读取表1
df2 = pd.read_excel('test.xlsx', sheet_name=1).fillna(method='pad') # 读取表2
df_result = pd.DataFrame(index=set(df1['部门']), columns=set(df2['产品'])).fillna(0) # 运算结果
for each_dept in set(df1['部门']): # 遍历每个部门
df_each_dept = df1[df1['部门'] == each_dept] # 在表1中取出每个部门的礼品情况
for each_dept_welfare in df_each_dept['礼品档次']: # 遍历每个部门的”礼品档次“:
for each_welfare in df2[df2['标准'] == each_dept_welfare]['产品']:
df_result.loc[each_dept, each_welfare] += 1 # 该部门对应的礼品数值+1
writer = pd.ExcelWriter('result.xlsx') # 保存结果
df_result.to_excel(writer, 'result')
writer.save()
改写后,不仅减少代码数量,而且无需事先建立礼品列表。
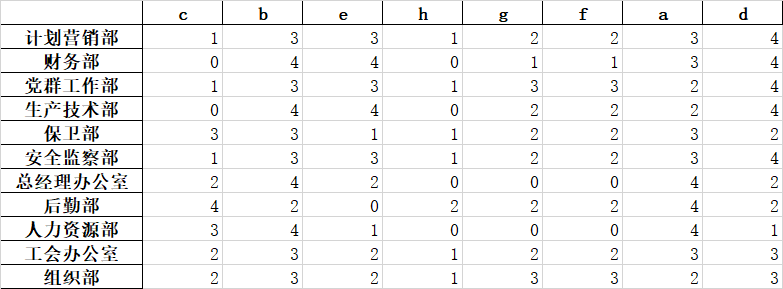
运算result.xlsx结果如下:
备注:遍历每个部门时,可以用groupby(),这样还可以少写一句代码,
import pandas as pd
df1 = pd.read_excel('test.xlsx', sheet_name=0, index_col='序号')
df2 = pd.read_excel('test.xlsx', sheet_name=1).fillna(method='pad')
df_result = pd.DataFrame(index=set(df1['部门']), columns=set(df2['产品'])).fillna(0)
for dept, df_dept in df1.groupby('部门'):
for dept_welfare in df_dept['礼品档次']:
for welfare in df2[df2['标准'] == dept_welfare]['产品']:
df_result.loc[dept, welfare] += 1
writer = pd.ExcelWriter('result.xlsx')
df_result.to_excel(writer, 'result')
writer.save()
看到篇博文,用python pandas改写了下的更多相关文章
- 我的第一篇博文,Python+scrapy框架安装。
自己用Python脚本写爬虫有一段时日了,也抓了不少网页,有的网页信息两多,一个脚本用exe跑了两个多月,数据还在进行中.但是总觉得这样抓效率有点低,问题也是多多的,很早就知道了这个框架好用,今天终于 ...
- 第一篇博文,整理一下关于Mac下安装本地LNMP环境的一些坑
安装的主要步骤是按照以下这篇文章进行的http://blog.csdn.net/w670328683/article/details/50628629,但是依然遇到了一些大大小小的坑(一个环境搞了一天 ...
- Python pandas & numpy 笔记
记性不好,多记录些常用的东西,真·持续更新中::先列出一些常用的网址: 参考了的 莫烦python pandas DOC numpy DOC matplotlib 常用 习惯上我们如此导入: impo ...
- python学习之【第十五篇】:Python中的常用模块之time模块
1.前言 在Python中,对时间的表示或操作通常要使用到time模块.本篇博文就来记录一下time模块中常用的几种时间表示转换方法. 2. 三种时间表示形式 2.1 时间戳 从1970年1月1日零点 ...
- 第一篇博客 Python开发环境配置
本文主要介绍Windows7环境下安装并配置Anaconda+VSCode作为Python开发环境. 目录 Anaconda与包管理配 Anaconda安装 添加环境变量 Anaconda安装错误及解 ...
- Python之路【第九篇】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Python之路[第九篇]:Python操作 RabbitMQ.Redis.Memcache.SQLAlchemy Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用 ...
- python & pandas链接mysql数据库
Python&pandas与mysql连接 1.python 与mysql 连接及操作,直接上代码,简单直接高效: import MySQLdb try: conn = MySQLdb.con ...
- Pyhton开发【第五篇】:Python基础之杂货铺
Python开发[第五篇]:Python基础之杂货铺 字符串格式化 Python的字符串格式化有两种方式: 百分号方式.format方式 百分号的方式相对来说比较老,而format方式则是比较先进 ...
- webIDE 第二篇博文
这是我做webIDE过程中的第二篇博文,之所以隔了这么长时间没更,因为确实是没有啥进度啊,没什么可写的,现在虽然依然没啥进度,但中途遇到很多坑,这些坑还是有记录下来的必要的. 因个人水平问题,可能有的 ...
随机推荐
- day 27 异常处理
一.异常 1.什么是异常? 异常指的是与正常情况不同在程序中 程序的正常执行过程 按照代码顺序 一行一行的执行 直到所有的代码都执行完如果在执行过程中出现了错误导致代码无法执行完毕 这就称之为异常异常 ...
- Git pull的时候遇到问题
转载:https://www.jianshu.com/p/7b1c58e0a9ef 使用git从远程pull代码时报错: error: The following untracked working ...
- 尚硅谷面试第一季-07Spring Bean的作用域之间有什么区别
目录结构: 关键性代码: beans.xml <!-- ★bean的作用域 可以通过scope属性来指定bean的作用域 -singleton:默认值.当IOC容器一创建就会创建bean的实例, ...
- 【Python025-字典】
一.字典 1.创建和访问字典(字典是大括号表示,字典是映射类型) 语法类型:键:key,值:value,用冒号隔开 --- >>> dict1 = {'李宁':'一切皆有可能','耐 ...
- iOS Xcode Error 集锦
一),'libxml/tree.h' file not found Solution: 1. 导入libxml2.dylib 包 2.设置Header Search Paths 为 /usr/inc ...
- springBoot 学习(总)
springBoot有个中文文档网址,应该是持续更新的. 别的资料 http://tengj.top/2017/02/26/springboot1/ http://412887952-qq-c ...
- Symbol在对象中的作用
Symbol的打印 我们先声明一个Symbol,然后我们在控制台输出一下. var g = Symbol('jspang'); console.log(g); console.log(g.toStri ...
- 转载:避免重复插入,更新的sql
本文章来给大家提供三种在mysql中避免重复插入记录方法,主要是讲到了ignore,Replace,ON DUPLICATE KEY UPDATE三种方法,各位同学可尝试参考. 案一:使用ignore ...
- 20165306 预备作业3 Linux安装及学习
查看了许多教程,VirtualBox和Ubuntu已安装完成.以下为学习Linux基础入门课程的实验报告.实验截图.尚未解决的问题及体会. 实验三 用户及文件权限管理 一.Linux用户管理 (一)查 ...
- vue--vuex
https://vuex.vuejs.org/ vuex是专为 vue.js 应用程序开发的 状态管理模式 采用集中式存储管理应用的所有组件状态 并以相应的规则保证状态以一种可预测的方式发生变化 vu ...