[No0000154]详解为什么32位系统只能用4G内存.
既然是详解, 就从最基础的讲起了.
或者1来存储数据的, 所以Bit实际上可以看成存放1个二进制数字的1个位置.
也就是说bit只有2种值, 0 或者 1, 所以1个bit能存放1个布尔类型的值(boolean,是或者否).
如果一个布尔类型被存放在1个bit中, 自然这个变量就占用1个bit了, 无论这个值是1或者0, 它都占用1个bit...
个文件占多少KB, MB... 1个硬盘占多少GB.. 等后面的这个B, 指的就是字节Byte, 而不是上面的Bit, 而且1个Byte = 8Bit, 这个怎么理解呢?
其实1个Byte 可以看成是有8个物理上连续的Bit组成的, 如下图:

上面说了, 1个Bit 只能表示两种值0 or 1, 其实就是2^1(2的1次方)种值啦.
那么1个Byte能表示多少种值呢, 很简单就是2^8 = 256种啦
逻辑上就是因为1个Byte 是由8个bit组成的, 每1个bit可以有两种值(0 or 1), 那么8个bit根据概率组合论就有2^8 = 256种了.
它们分别是:
二进制: 0000 0000 0000 0001 0000 0010 0000 0011 ... 0000 1111 0001 0000 ... 1111 1111
十进制: 0 1 2 3 ... 15 16 ... 255
十六进制: 0 0 1 2 3 ... 0 F 1 0 ... F F
可以看出如下几点:
a. 这256个值分别是0~255 所以1个字节能表示最大的值就是255, 所以很多时候我们见到有255最大的限制(例如ip地址)就是这个原因啊。
b. 二进制1个字节是由8个位组成的,而每4个位可以看成1组,由1个十六进制数字来表示。也就是说十六进制的0-F分别表示二进制的0000 - 1111, 所以用16进制和2进制的转化其实是很方便的。
3. 内存是计算机系统的主存储器
介绍上面两个存储单位后就介绍下内存了。
个存储数据的存在,有1个很重要的特性,就是内存里的数据能被cpu直接访问。
cpu能不能直接访问硬盘的数据呢,不能。只能通过把硬盘的数据先放到内存里,然后再从内存里访问硬盘的数据。我们平时玩游戏碰上读图loading 进度条的这个过程,就是把数据从硬盘读到内存的过程啊。读完条后地图的数据就在内存中了。
所以内存才是计算机系统的主存储器,而硬盘是被分到跟光盘..u盘一类都是外部存储器。
4. 内存的基本结构
或者1这两个二进制数字啊,所以内存里实际上有海量的小格子,每1个格子是1个个数字(0或者1),那么数值255需要几个格子来放呢?就是8个格子啊, 1个字节byte啊。
但是问题来了,我刚说了内存里的格子数量非常巨大,如果cpu要读出某个指定的数据,怎么去找呢?
1个1个格子去遍历吗,其实稍微接触过数据结构的都知道,遍历虽然实现简单,但是在海量数据面前简直是自杀行为。
所以实际上内存是把8个8个bit排成1组,每1组成为1个单位,大小是1个byte,而不能单独去访问具体的1个小格子(bit). 1个byte字节就是内存的最小的IO单位.
也就是说内存是由8个 8个小格(bit)组成的1个字节单位(byte)排列组成的。如下图:
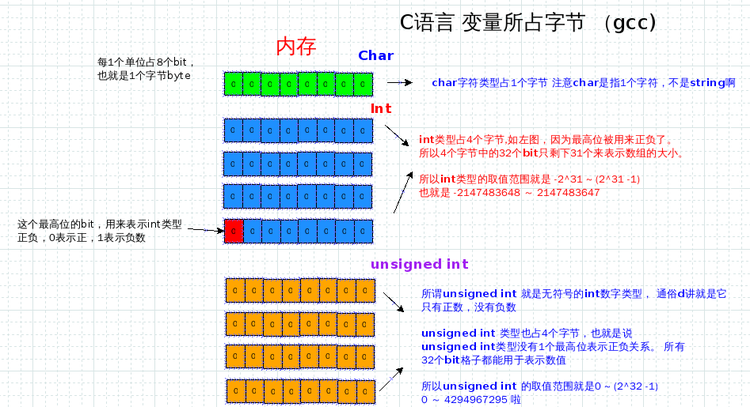
个字节, int类型和unsigned int类型占4个字节byte.
5. 引入内存地址概念。
即使我们把内存分成了以字节为单位的结构,但是实际上内存里还是有非常多的字节的,例如64MB内存就有 64 × 1024 × 1024 个字节啊!
如果cpu要查找1个变量,还是要1个个字节去找到话...还是1个很浪费时间的行为,所以为了避免去遍历内存,计算机系统就引入了内存地址这个概念。
举个例子, 内存就是一栋大楼, 而内存里每1个字节就是大楼的每个房间, 而内存地址就是房间的门牌号码了. 如果没有门牌号码,我们去访问某个住在大楼的人是十分苦难的, 只能从1楼开始每个房间去敲门.. 如果那个人住在顶楼你就悲剧了. 而如果你知道那个人的门牌号码, 就可以直接上去敲他的门查他水表了, 实在是方便很多啊.
内存也一样, 个内存地址, cpu只需要知道某个数据类型的地址, 就可以直接去到读影的内存位置去提取数据了.
6. 直接寻址技术.
个逆天的技术,就是直接寻址了.
什么意思呢, 还是用上面的例子说明, 假如你知道你要找的人住在那栋大楼的17楼 1702, 但是你还是需要从1楼走到17楼去找他, 这个过程还是需要时间成本的.
但是如果你具有了直接寻址技术, 就能直接跳到17楼 1702门前, 如果你找的下1个人在2楼, 又能从17楼直接跳到2楼, 逆天啊.
而直接寻址技术已经成为当代计算机软硬件的标准技术之一了, 也就是说只要cpu知道要访问数据的内存地址, 就能直接到内存的对应位置去访问数据!
7. 内存地址的表示方式
个2进制数字来表示的. 每1个地址对应内存里的1个byte字节, 如果地址的值加1, 那么这个地址就对应下1个字节了.
那么内存地址的长度是多少呢? 这个就是这篇文章标题所涉及的. 在32位操作系统中, 位的2进制数位系统的某个内存地址是:
0000 1111 1111 0000 1111 0000 1111 0000
那么它可以用十六进制表示成: 0 F F 0 F 0 F 0
也就是
个二进制的数字啊. 不过计算机里面所有的东西都是二进制了..
8. 内存地址的数量决定cpu能访问的内存大小.
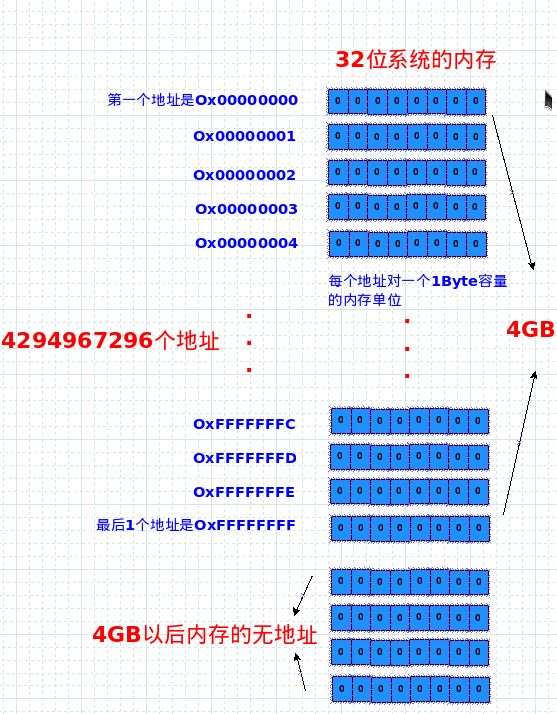
位系统里内存地址长度是32位的. 所以32位的地址范围就是从 0000 0000 0000 0000 0000 0000 0000 0000 到 1111 1111 1111 1111 1111 1111 1111 1111 啦(Ox00000000 ~ OxFFFFFFFF),这里有几个地址呢?明显是有 2^32 个啦.
那么2^32到底是多少个? 2^32 = 4 * 1024(G) * 1024(M) * 1024(K) = 4294967296 , 就是个地址对应1个1个字节,容量就是1byte,所以2^32个地址就总共能对应应4G位的系统配上了8GB的内存,操作系统最多也只能给其中4GB 分配地址,其余 4GB 是没有地址,因为地址不够用啊,所以32位系统最多支持4GB内存就是这样来的。
那么64位系统呢,对应地, 64位系统的内存地址是64位的二进制数啊, 0000 ...64个0 ~ 1111 ...64个1, 用十六进表示就是从Ox0000000000000000 ~ OxFFFFFFFFFFFFFFFF , 每个地址的长度比32位的长度多1倍!而64位系统总共有多少个地址?
2^64 = 2^34 * 2^10(G) * 2^10(M) * 2^10(K) 也就是 17179869184 G(4G × 4G)个地址,我艹这是神码概念,也就是说64位系统配上64位cpu理论上支持17多亿GB的内存,当然这个只是理论了,实际上现在的普通主版能上个16GB都不错了。
见下图:

9. 关于指针。
位系统来讲,内存地址是1个32位长度的2进制数,而每1个内存单位长度只有1byte = 8bit(位),所以1个指针就需要4byte的内存来存放该指针的内容(1个内存地址)啦。
个指针 int *p; 然后求sizeof(p) 是返回4的, 4字节嘛~
而对于64位系统来讲,内存地址是64位的2进制数,所以sizof(p)就返回8了,共需要8个内存单位去存放 64位系统的1个指针啊!
[No0000154]详解为什么32位系统只能用4G内存.的更多相关文章
- 详解为什么32位系统只能用4G内存.
本文转自:https://www.cnblogs.com/nvd11/archive/2013/04/02/2996784.html,感谢作者的干货 既然是详解, 就从最基础的讲起了. 1. Bit( ...
- 百杂讲堂之为什么32位系统只能操作4g内存
百杂讲堂之为什么32位系统只能操作4g内存 计算机内存中很多的单元,每一个单元就是一个字节,一个字节有8位.每一个单元有两种状态:0和1. 所以 两个单元就有4个组合: 3个单元就有8个组合: 依次类 ...
- 为什么32位系统最大支持4G内存??我自己悟出来了 终于 。。。。。
今天突然开窍了,想通了..... 以下是我的抽象想法: 32位系统 这个 多少位 指的是 硬件的 一次性发送过来的位数,一个字节 等于8位,内存的一个存储单元就是一个字节,即8位. 也可以这样来想这个 ...
- 32位系统下使用4GB内存
64位系统的驱动还有不少缺陷,果断重装回32位系统,但是4gb的内存,明显是浪费啊. 所以必须利用起来. 我没有采用不稳定的破解内核的做法,采用了虚拟硬盘的做法.因为个人觉得这样其实利用效率更高. 方 ...
- PL/SQL Developer安装详解(32位客户端免安装版)
PL/SQL Developer是一个集成开发环境,专门开发面向Oracle数据库的应用.PL/SQL也是一种程序语言,叫做过程化SQL语言(Procedural Language/SQL).PL/S ...
- sql2005性能优化(在32位系统上突破2G内存使用量的方法) .
转载自http://blog.csdn.net/soldierluo/article/details/6589743 服务器磁盘为(SAS)IBM组成RAID0+1,SQL2K5只识别4G内存,实际只 ...
- [笔记]--Oracle 10g在Windows 32位系统使用2G以上内存
1.修改c:\boot.ini文件 打开boot.ini文件,我的电脑->属性->高级->启动和恢复->编辑,设置在最后一行末尾添加/PAE选项后如下: [boot loade ...
- win7 PLSQL Developer 10/11/12 连接 Oracle 10/11/12 x64位数据库配置详解(与32位一样,只要注意对应Oracle Instant Client版本) tns 错误和 nls错误
环境win7 x64 PLSQL Developer 10 与 11 Oracle Instant Client 10 与 12 参考http://blog.csdn.net/chen_zw/arti ...
- 微软的操作系统中让 32 位支持大于 4GB 的内存。
先给一个参考文献:The RAM reported by the System Properties dialog box and the System Information tool is les ...
随机推荐
- swift常用第三方库
网络 Alamofire:http网络请求事件处理的框架. Moya:这是一个基于Alamofire的更高层网络请求封装抽象层. Reachability.swift:用来检查应用当前的网络连接状况. ...
- file命令与magic file【转】
Linux基础——file命令与magic file [日期:2013-06-03] 来源:Linux社区 作者:sin90lzc [字体:大 中 小] //本文基于CentOS6.3 dist ...
- C++中 线程函数为静态函数 及 类成员函数作为回调函数
线程函数为静态函数: 线程控制函数和是不是静态函数没关系,静态函数是在构造中分配的地址空间,只有在析构时才释放也就是全局的东西,不管线程是否运行,静态函数的地址是不变的,并不在线程堆栈中static只 ...
- OpenCV 学习笔记 05 人脸检测和识别 AttributeError: module 'cv2' has no attribute 'face'
1 环境设置: win10 python 3.6.8 opencv 4.0.1 2 尝试的方法 在学习人脸识别中,遇到了没有 cv2 中没有 face 属性.在网上找了几个方法,均没有成功解决掉该问题 ...
- [svc]gns3模拟器及探讨几个bgp问题
模拟器 链接:https://pan.baidu.com/s/1geMcmND 密码:7iir gns0.8.6的版本好用 思科的这个iso好用: c3660-js2-mz.124-21a.bin C ...
- spring boot user authorities类图
- Asp.Net AutoMapper用法
1.AutoMapper简介 用于两个对象映射,例如把Model的属性值赋值给View Model.传统写法会一个一个属性的映射很麻烦,使用AutoMapper两句代码搞定. 2.AutoMapper ...
- MXNET:监督学习
线性回归 给定一个数据点集合 X 和对应的目标值 y,线性模型的目标就是找到一条使用向量 w 和位移 b 描述的线,来尽可能地近似每个样本X[i] 和 y[i]. 数学公式表示为\(\hat{y}=X ...
- java框架篇---hibernate主键生成策略
Hibernate主键生成策略 1.自动增长identity 适用于MySQL.DB2.MS SQL Server,采用数据库生成的主键,用于为long.short.int类型生成唯一标识 使用SQL ...
- UML类图关系大全【转】
UML类图关系大全 1.关联 双向关联:C1-C2:指双方都知道对方的存在,都可以调用对方的公共属性和方法. 在GOF的设计模式书上是这样描述的:虽然在分析阶段这种关系是适用的,但我们觉得它对于描述设 ...