PyCharm调试运行Scrapy教程
一、使用scrapy创建一个项目
这里使用scrapy官方第一个示例
scrapy startproject tutorial

使用PyCharm打开项目,在tutorial/tutorial/spiders目录下创建quotes_spider.py文件并写入,以下代码
import scrapy class QuotesSpider(scrapy.Spider):
name = "quotes" def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse) def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
二、复制cmdline.py到项目主目录
找到scrapy下的cmdline.py文件(比如我这里是D:\Language\Miniconda3\envs\default\Lib\site-packages\scrapy\cmdline.py)
复制一份到tutorial项目的根目录下(scrapy.cfg文件的同一目录下)

三、编缉文件调试运行配置
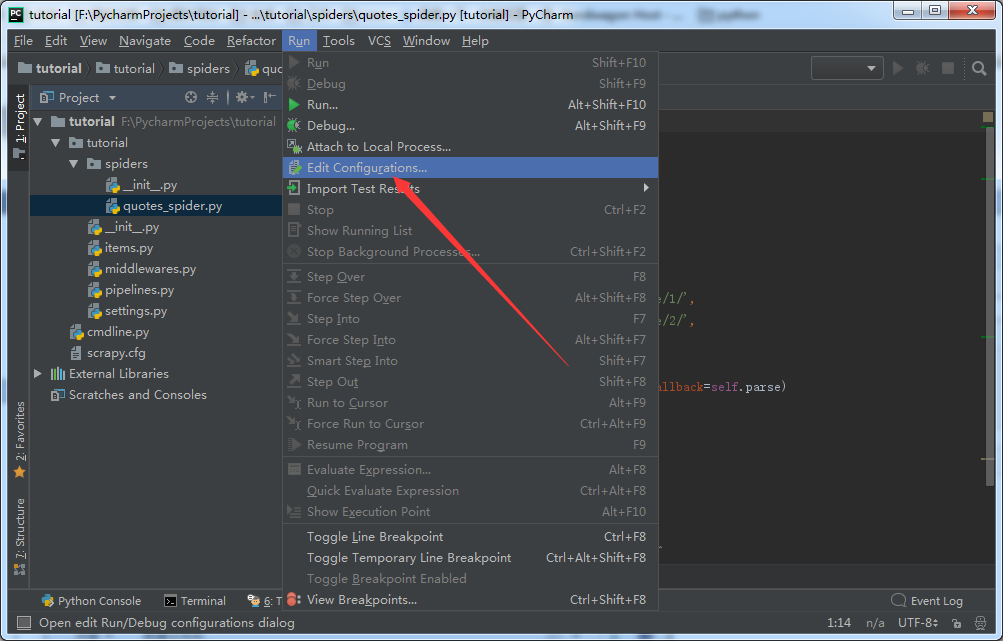

Name--和上边创建的spider文件相同,我这里叫quotes_spider
Script path--选择当前项目下的cmdline.py,我这里是F:\PycharmProjects\tutorial\cmdline.py
Parameters--crawl+要调试运行的spider名称,我这里是crawl quotes
Working directory--填项目所在主目录,我这里是F:\PycharmProjects\tutorial
最后要注意点“Apply”,不要直接点“OK”
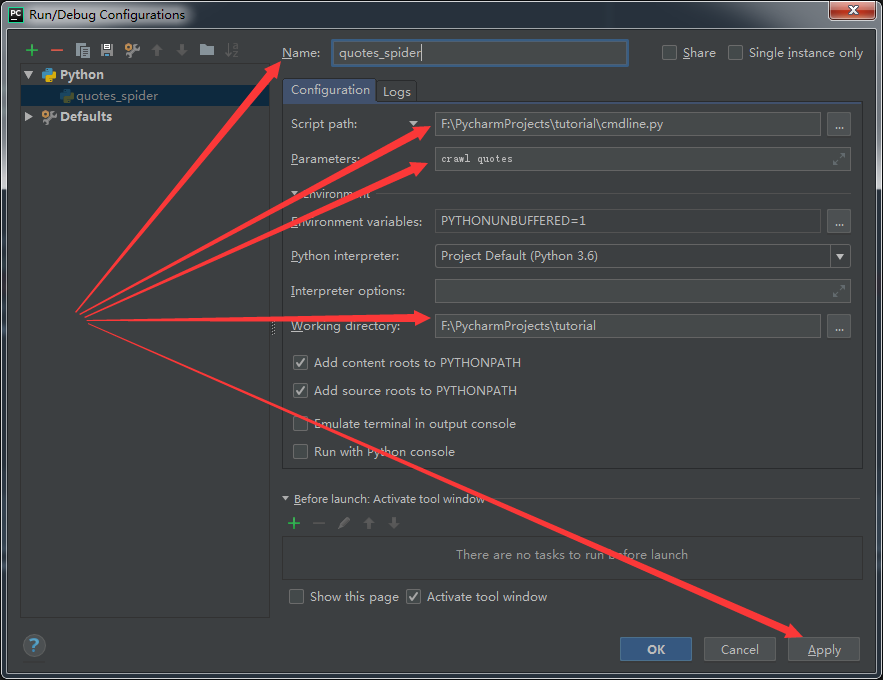
四、调示和运行演示
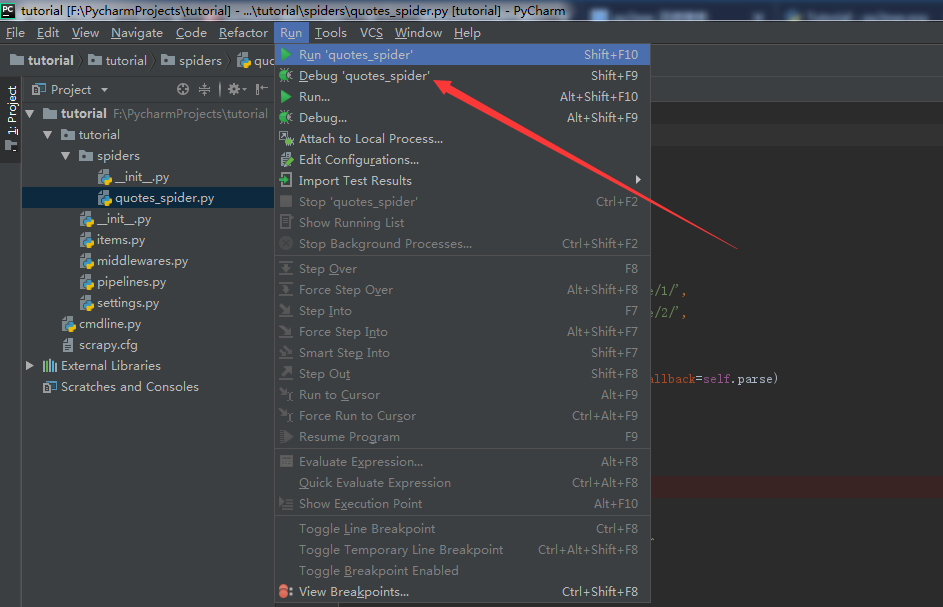
选择调试,程序成功停在断点处

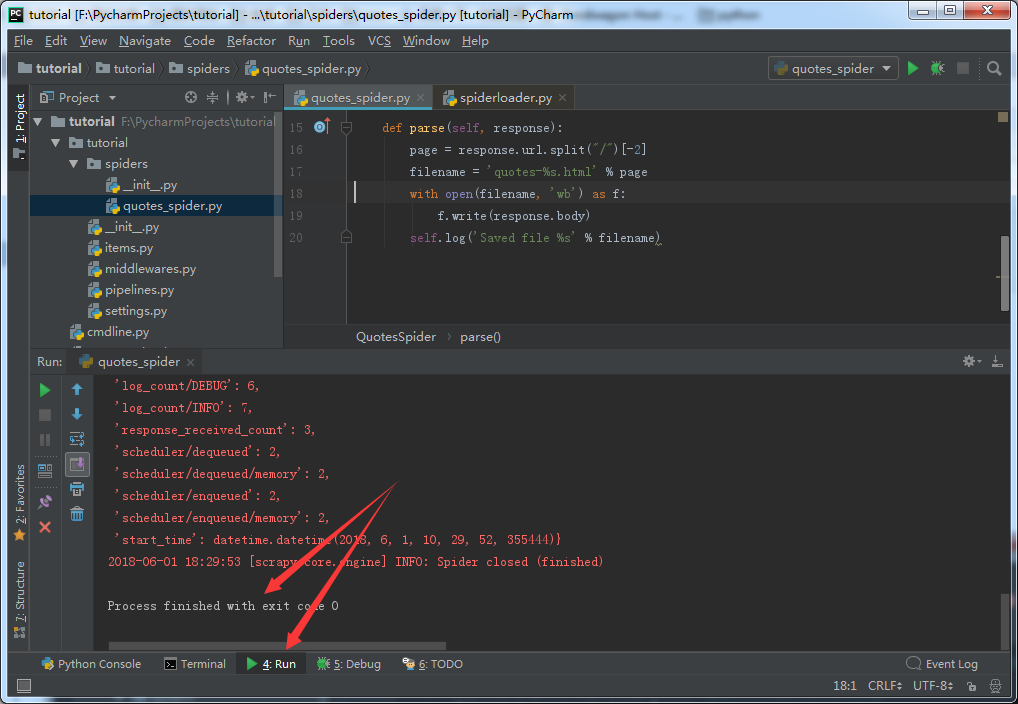
选择运行,程序也成功通行
PyCharm调试运行Scrapy教程的更多相关文章
- 在Pycharm中运行Scrapy爬虫项目的基本操作
目标在Win7上建立一个Scrapy爬虫项目,以及对其进行基本操作.运行环境:电脑上已经安装了python(环境变量path已经设置好), 以及scrapy模块,IDE为Pycharm .操作如下: ...
- Miniconda安装scrapy教程
一.背景说明 前两天想重新研究下Scrapy,当时的环境是PyCharm社区版+Python 3.7.使用pip安装一直报错 “distutils.errors.DistutilsPlatformEr ...
- 亲测——pycharm下运行第一个scrapy项目 ©seven_clear
最近在学习scrapy,就想着用pycharm调试,但不知道怎么弄,从网上搜了很多方法,这里总结一个我试成功了的. 首先当然是安装scrapy,安装教程什么的网上一大堆,这里推荐一个详细的:http: ...
- 最全Pycharm教程(11)——Pycharm调试器之断点篇
最全Pycharm教程(1)--定制外观 最全Pycharm教程(2)--代码风格 最全Pycharm教程(3)--代码的调试.执行 最全Pycharm教程(4)--有关Python解释器的相关配置 ...
- 如何用 PyCharm 调试 scrapy 项目
原理: 首先 scrapy 命令其实就是一个python脚本,你可以使用 which scrapy 查看该脚本的内容: from scrapy.cmdline import execute sys.a ...
- pycharm调试scrapy
pycharm调试scrapy 创建一个run.py文件作为调试入口 run.py中,name是要调试的爬虫的名字(注意,是爬虫类中的name,而不是爬虫类所在文件的名字) 拼接爬虫运行的命令,然后用 ...
- 9.scrapy pycharm调试小技巧,请求一次,下次直接调试,不必每次都启动整个爬虫,重新请求一整遍
pycharm调试技巧:调试时,请求一次,下次直接调试,不必每次都启动整个爬虫,重新请求一整遍 [用法]cmd命令运行:scrapy shell 网址 第一步,cmd进行一次请求: scrapy sh ...
- scrapy基础知识之 pycharm 调试小技巧:
在项目根目录下新建main.py文件,用于调试 from scrapy.cmdline import executeexecute(["scrapy","crawl&qu ...
- 【转载】Pycharm调试高效,还是pdb调试高效? (在服务端)
https://segmentfault.com/q/1010000005067119 Pycharm调试高效,还是pdb调试高效? (在服务端) python 3.9k 次浏览 问题对人有帮助, ...
随机推荐
- JsonKey小写
System.Text.RegularExpressions.MatchCollection ms = System.Text.RegularExpressions.Regex.Matches(eca ...
- 1.spring基础知识讲解
引言:以下记录一些自己在使用时pringle框架时的一些自己心得合成体会时,如有侵权,请联系本博主. 1. spring基本都使用 spring是一个开源的轻量级框架,其目的是用于简化企业级应用程序开 ...
- 随机--相关(Fisher_Yates算法)
Fisher_Yates算法 void ShuffleArray_Fisher_Yates(char* arr, int len) { int i = len, j; char t ...
- 力扣(LeetCode) 852. 山脉数组的峰顶索引
我们把符合下列属性的数组 A 称作山脉: A.length >= 3 存在 0 < i < A.length - 1 使得A[0] < A[1] < ... A[i-1] ...
- 使用VSCode如何从github拉取项目
转载自:https://blog.csdn.net/sunqy1995/article/details/81517159 1.开vscode使用CTRL+`或者点击查看到集成终端打开控制终端 2. 在 ...
- Dreamweaver 1 网页制作
1.站点 1.1 创建站点 点击菜单栏中站点进行站点创建,输入站点名称,路径 1.2 设置图像文件夹 1.3 站点管理 站点的编辑.复制.删除 2.页面属性栏 2.1 外观 1.设置页面整体的字体.大 ...
- python - argparse 模块学习
python - argparse 模块学习 设置一个解析器 使用argparse的第一步就是创建一个解析器对象,并告诉它将会有些什么参数.那么当你的程序运行时,该解析器就可以用于处理命令行参数. 解 ...
- Robot framework--内置库xml学习(一)
Using lxml By default this library uses Python's standard ElementTree module for parsing XML, but it ...
- 雷林鹏分享:C# 数组(Array)
C# 数组(Array) 数组是一个存储相同类型元素的固定大小的顺序集合.数组是用来存储数据的集合,通常认为数组是一个同一类型变量的集合. 声明数组变量并不是声明 number0.number1... ...
- 扩大了一个逻辑卷,resize2fs 保错:没有这个超级块
检查发现,文件系统类型是xfs,应该使用 xfs_growfs命令刷新文件系统