085 HBase的二级索引,以及phoenix的安装(需再做一次)
一:问题由来
1.举例
有A列与B列,分别是年龄与姓名。
如果想通过年龄查询姓名。
正常的检索是通过rowkey进行检索。
根据年龄查询rowkey,然后根据rowkey进行查找姓名。
这样的效率不高,因为要两次scan。
2.建议有一张索引表。
二:HBase的二级索引
1.讲解
rowkey是uid+ts
11111_20161126111111:
这个rowkey方便查询某一uid的某一个时间段内的数据
问题:
查询某一时间段内所有用户的数据:按照时间
索引表
rowkey:ts+uid 20161126111111—111111
其他列:info:uid
值是uid+ts,因为这个是原表的rowkey。
检索流程:
从索引表中根据时间段来查询源表rowkey
根据rowkey来查询源表
2.还有的问题
如何保持索引表与原表的同步问题。
好的方式是:编写协处理器,将客户端实现的逻辑代码放到服务端。
同时,可以使用其他的框架,主要有solr,phoenix。elassearch。
3.协处理器
observer处理器:观察者,类似于触发器
endpoint类:终端类,类似于储存过程。
4.hbase自带的协处理器
这个在hbase:meta中
可以通过desc 'hbase:meta'进行查看
是coprocessor$1。
三:phoenix的安装
1.上传源码包
因为对应的hbase0.98.6没有对应的phoenix,所以需要自己进行编译。

2.解压到modules文件夹下
tar -zxvf phoenix-4.2.2-src.tar.gz -C /etc/opt/modules/
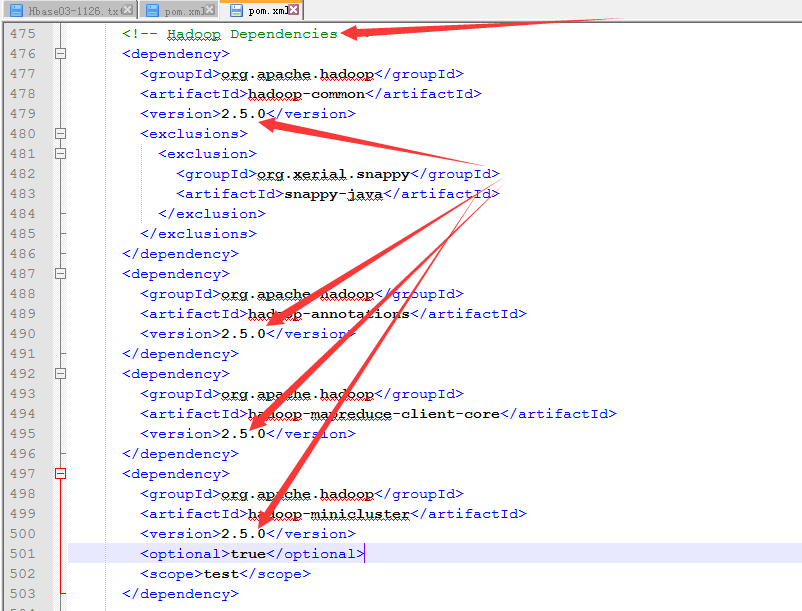
3.修改pom.xml文件
有一个问题,将所有的hadoop-two.version 变量都换成2.5.0
<hbase.version>0.98.6-hadoop2</hbase.version>
<hadoop-two.version>2.5.0</hadoop-two.version>
4.进入主目录
5.编译
mvn clean package -DskipTests
----------------------------------------------------(以下需要重新编译,重新做)------------------------------------------------------------
6.查找编译好的包
Phoenix_home/Phoenix-assembly/target/phoenix-4.2.2.tar.gz
7.安装phoenix
启动的时候,后面跟的是zookeeper地址。

8.phoenix映射原有的表
执行的语句,在phoenix中。
hbase对于大小写敏感,然后需要将phoenix中的语句进行双引号引起来。

9.看效果
可以在phoenix中查询映射的表。
select * from "s1";
将会发现,这里的数据与hbase中的数据相同。
085 HBase的二级索引,以及phoenix的安装(需再做一次)的更多相关文章
- HBase的二级索引,以及phoenix的安装(需再做一次)
一:HBase的二级索引 1.讲解 uid+ts 11111_20161126111111:查询某一uid的某一个时间段内的数据 查询某一时间段内所有用户的数据:按照时间 索引表 rowkey:ts+ ...
- HBase建立二级索引的一些解决方式
HBase的一级索引就是rowkey,我们仅仅能通过rowkey进行检索. 假设我们相对hbase里面列族的列列进行一些组合查询.就须要採用HBase的二级索引方案来进行多条件的查询. 常见的二级索引 ...
- HBase之八--(2):HBase二级索引之Phoenix
1. 介绍 Phoenix 是 Salesforce.com 开源的一个 Java 中间件,可以让开发者在Apache HBase 上执行 SQL 查询.Phoenix完全使用Java编写,代码位于 ...
- 利用Phoenix为HBase创建二级索引
为什么需要Secondary Index 对于Hbase而言,如果想精确地定位到某行记录,唯一的办法是通过rowkey来查询.如果不通过rowkey来查找数据,就必须逐行地比较每一列的值,即全表扫瞄. ...
- hbase构建二级索引解决方案
关注公众号:大数据技术派,回复"资料",领取1024G资料. 1 为什么需要二级索引 HBase的一级索引就是rowkey,我们仅仅能通过rowkey进行检索.假设我们相对Hbas ...
- 基于Solr实现HBase的二级索引
文章来源:http://www.open-open.com/lib/view/open1421501717312.html 实现目的: 由于hbase基于行健有序存储,在查询时使用行健十分高效,然后想 ...
- hbase coprocessor 二级索引
Coprocessor方式二级索引 1. Coprocessor提供了一种机制可以让开发者直接在RegionServer上运行自定义代码来管理数据.通常我们使用get或者scan来从Hbase中获取数 ...
- [How to] MapReduce on HBase ----- 简单二级索引的实现
1.简介 MapReduce计算框架是二代hadoop的YARN一部分,能够提供大数据量的平行批处理.MR只提供了基本的计算方法,之所以能够使用在不用的数据格式上包括HBase表上是因为特定格式上的数 ...
- HBase的二级索引
使用HBase存储中国好声音数据的案例,业务描述如下: 为了能高效的查询到我们需要的数据,我们在RowKey的设计上下了不少功夫,因为过滤RowKey或者根据RowKey查询数据的效率是最高的,我们的 ...
随机推荐
- asp.net mvc4 Json问题
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.We ...
- POJ 1811 Prime Test (Rabin-Miller强伪素数测试 和Pollard-rho 因数分解)
题目链接 Description Given a big integer number, you are required to find out whether it's a prime numbe ...
- 5、利用两个栈实现队列,完成push和pop操作
题目描述 用两个栈来实现一个队列,完成队列的Push和Pop操作. 队列中的元素为int类型. 思路: 1.一个栈用来做push 2.另一个栈用来做pop 3.将push操作的栈的元素放入另一个栈中, ...
- mysql 原理 ~ 常规锁
一 模式 RR模式二 mysql锁相关场景 1 有间隙的地方就可能有间隙锁,并非只有辅助索引的场景下才会存在gap lock,典型场景 id主键的范围查询 2 varchar的范围锁定原理和int ...
- Java并发编程(1)-Java内存模型
本文主要是学习Java内存模型的笔记以及加上自己的一些案例分享,如有错误之处请指出. 一 Java内存模型的基础 1.并发编程模型的两个问题 在并发编程中,需要了解并会处理这两个关键问题: 1.1.线 ...
- sql 中的null值
1.包含null的表达式都为空 select salary*12+nvl(bonus,0) nvl是虑空函数 2. null值永远!=null select * from emp where bo ...
- Linux搜索查找类指令
⒈find [搜索范围] [选项] find指令将从指定目录下递归的遍历其各个子目录,将满足条件的文件或者目录显示在终端 选项说明: 选项 功能 -name<查询方式> 按照指定的文件名查 ...
- MR室内室外用户区分
mro_view_details_year中v3字段 1:室外用户 0:室内用户 主小区是室内站 主小区信号>-90dBm ==> 室内 主小区信号>-100dBm &&am ...
- SharePoint 2010:搜索服务当前处于脱机状态
错误 搜索服务当前处于脱机状态.请访问 SharePoint 管理中心中的"服务器上的服务"页,以验证是否启用了该服务.这也可能是由于正在移动索引器所致. 正在配置网站集搜索关 ...
- centos7.2环境中kettle环境搭建及任务推送配置详解
目标:将mysql5.5中testdb1的ehr_user表推送到tdoa的ehr_user表中,为避免不必要的麻烦,两张表结构.编码,包括数据库编码保持一致 操作系统:centos7.2 kettl ...