Hadoop on Mac with IntelliJ IDEA - 10 陆喜恒. Hadoop实战(第2版)6.4.1(Shuffle和排序)Map端 内容整理
下午对着源码看陆喜恒. Hadoop实战(第2版)6.4.1 (Shuffle和排序)Map端,发现与Hadoop 1.2.1的源码有些出入。下面作个简单的记录,方便起见,引用自书本的语句都用斜体表示。
依书本,从MapTask.java开始。这个类有多个内部类:
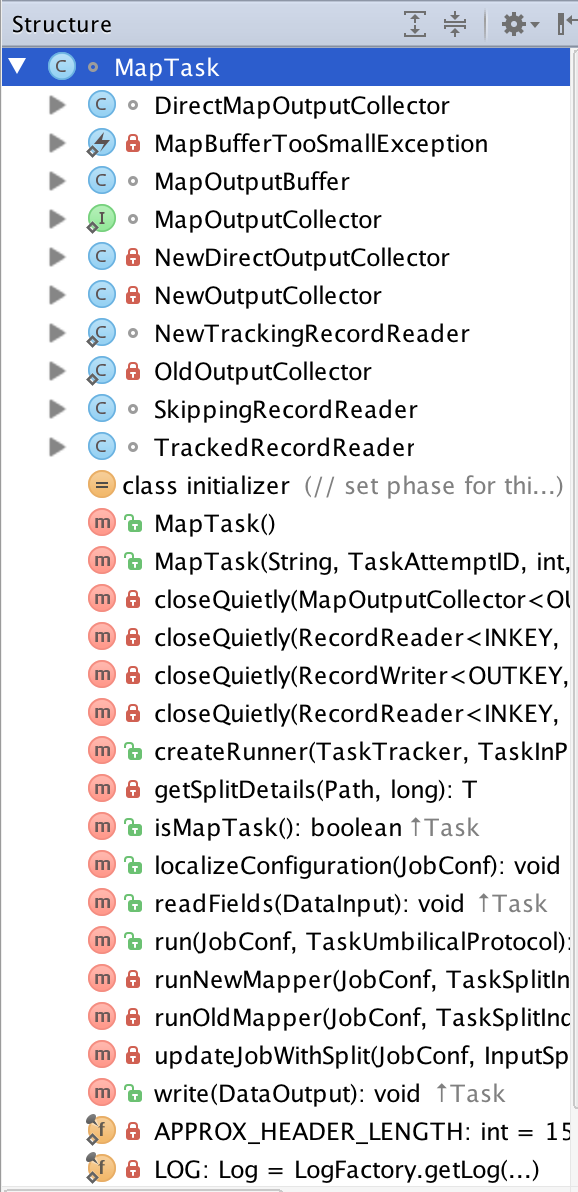
从书的描述可知,collect()并不在MapTask类,而在MapOutputBuffer类,其函数功能是
1、定义输出内存缓冲区为环形结构
2、定义输出内存缓冲区内容到磁盘的操作
在collect函数中将缓冲区的内容写出时会调用sortAndSpill函数。好了,从这里开始就糊涂了,因为collect()没调用这个函数,接触Hadoop也就几天时间,啥都不懂,晕了。
简单表示下当前的函数调用关系:
0 ---- MapOutputBuffer::collect()
达到写出阈值后,写了缓冲区内容,形成spill文件。即,调用了startSpill()。
0 ---- MapOutputBuffer::collect()
1 -------- startSpill()
startSpill()触发了条件:spillReady.signal()。字段spillReady在SpillThread类中用到,SpillThread为Thread的子类,其run方法有如下内容:
SpillThread::run()
// ...
spillReady.await();
// ...
MapOutputBuffer::sortAndSpill()
// ...
那么,这里第一次看到sortAndSpill方法被调用,接上了书本的描述。现在主要函数调用关系如下
| 线程1 | 线程2(MapOutputBuffer构造函数中启动) |
|
0 ---- MapOutputBuffer::collect() 1 -------- startSpill() 2 ------------ spillReady.signal() |
SpillThread::run() |
sortAndSpill内部使用了快排:
...
sorter = ReflectionUtils.newInstance(
job.getClass(
"map.sort.class",
QuickSort.class,
IndexedSorter.class),
job);
...
sorter.sort();
...
排序后,判断combinerRunner是否为空,为空直接写入spill,否则调用combinerRunner.combine方法,而不是combineAndSpill方法,Hadoop 1.2.1源码中没书上写的这句代码。combinerRunner在MapOutputBuffer的构造函数中定义
combinerRunner = CombinerRunner.create(job, getTaskID(),
combineInputCounter,
reporter, null);
sortAndSpill()另一个调用者是flush(),此函数是MapOutputBuffer成员。这段代码位于
MapTask::run()
runOldMapper()
collector = new MapOutputBuffer(umbilical, job, reporter);
...
collector.flush()
sortAndSpill()
mergeParts()
done(umbilical, reporter)
上述的调用关系才符合书第112页最后一段的描述。mergeParts()执行合并操作,这个操作的主要目的是将Map生成的众多spill文件中的数据按照划分重新组织,以便于Reduce处理。这里的划分,应该是partition之意。
待唯一的已分区且排序的Map输出文件写入最后一条记录后,Map端的shuffle阶段就结束了。从源码看,这步应该是执行done(umbilical, reporter)后才完成。
╮(╯_╰)╭ 我不是为了情怀,我就是认真。
Hadoop on Mac with IntelliJ IDEA - 10 陆喜恒. Hadoop实战(第2版)6.4.1(Shuffle和排序)Map端 内容整理的更多相关文章
- Hadoop on Mac with IntelliJ IDEA - 9 解决Type mismatch in value from map问题
修改陆喜恒. Hadoop实战(第2版)5.3排序的代码时遇到IO异常. 环境:Mac OS X 10.9.5, IntelliJ IDEA 13.1.5, Hadoop 1.2.1 异常具体信息如下 ...
- Hadoop on Mac with IntelliJ IDEA - 8 单表关联NullPointerException
简化陆喜恒. Hadoop实战(第2版)5.4单表关联的代码时遇到空指向异常,经分析是逻辑问题,在此做个记录. 环境:Mac OS X 10.9.5, IntelliJ IDEA 13.1.5, Ha ...
- Hadoop on Mac with IntelliJ IDEA - 7 解决failed to report status for 600 seconds. Killing!问题
本文讲述作业在Hadoop 1.2.1完成map后ruduce阶段遇到failed to report status for 600 seconds. Killing!问题的解决过程. 环境:Mac ...
- Hadoop on Mac with IntelliJ IDEA - 5 解决java heap space问题
本文讲述在CentOS 6.5中提交作业到hadoop 1.2.1于reduce阶段遇到Error: java heap space错误导致作业重新计算的解决过程.解决办法适用Linux.Mac OS ...
- Hadoop on Mac with IntelliJ IDEA - 1 解决input path does not exist问题
本文讲述使用IntelliJ IDEA时遇到Hadoop提示input path does not exist(输入路径不存在)的解决过程. 环境:Mac OS X 10.9.5, IntelliJ ...
- Hadoop on Mac with IntelliJ IDEA - 6 解决KeyValueTextInputFormat读取时只有key值问题
本文讲述使用KeyValueTextInputFormat在Hadoop 0.x正常工作.Hadoop 1.2.1失效的解决过程. 环境:Mac OS X 10.9.5, IntelliJ IDEA ...
- Hadoop on Mac with IntelliJ IDEA - 4 制作jar包
本文讲述使用IntelliJ IDEA打包Project的过程,即,打jar包. 环境:Mac OS X 10.9.5, IntelliJ IDEA 13.1.4, Hadoop 1.2.1 Hado ...
- Hadoop on Mac with IntelliJ IDEA - 3 解决MRUnit - No applicable class implementing Serialization问题
本文讲述在IntelliJ IDEA中使用MRUnit 1.0.0测试Mapper派生类时因MapDriver.withInput(final K1 key, final V1 val)的key参数被 ...
- Hadoop on Mac with IntelliJ IDEA - 2 解决URI错误导致Permission denied
本文讲述在IntelliJ IDEA中使用FileSystem.copyFromLocalFile操作Hadoop时因URI格式有误导致Permission denied的解决过程. 环境:Mac O ...
随机推荐
- K2 K2Blackpearl安装步骤详解(服务端)
转:http://www.cnblogs.com/dannyli/archive/2011/11/30/2269485.html 以下是K2 Blackpearl的安装步骤,本人亲测可用哦. 1.安装 ...
- iOS 开发者必不可少的 75 个工具,你都会了吗
如果你去到一位熟练的木匠的工作室,你总是能发现他/她有一堆工具来完成不同的任务. 软件开发同样如此.你可以从软件开发者如何使用工具中看出他水准如何.有经验的开发者精于使用工具.对你目前所使用的工具不断 ...
- 所有 HTTP 状态代码及其定义
所有 HTTP 状态代码及其定义. 代码 指示 2xx 成功 200 正常:请求已完成. 201 正常:紧接 POST 命令. 202 正常:已接受用于处理,但处理尚未完成. 20 ...
- Android 自定义dialogfragment
在用dialogfragment的时候我们可能会不喜欢系统自带的黑色边框,那怎么办呢? dialofragment提供可供修改样式的方法setStyle(style,R.style.MyTryUseD ...
- LruCache--远程图片获取与本地缓存
Class Overview A cache that holds strong references to a limited number of values. Each time a value ...
- VMware 命令行下安装以及导入Ubuntu系统
前提: 鉴于个人PC性能太弱,考虑是否可以将在PC上搭建好的环境移植到高性能服务器上.想到后就干呗. 下载完对应操作系统的安装包后按如下步骤操作: 安装包名称:VMware-Workstation-F ...
- 腾讯2015校招一面、二面、HR面
其实我目前的理想公司就是腾讯. 内推第三面跪了··· 现在校招. 已面完一面.二面.HR面··· 一面主要问我项目和Linux.网络··· 二面主要问我游戏服务器··· 然后是HR面··· 技术面我都 ...
- jetty8的多实例部署(LT项目开发参考)
LT项目使用的EIP是运行在JETTY上,此文供开发和实施参考 1.windows下 win下部署多个jetty8很简单,首先将jetty8复制多个文件夹,其次按分配的端口号修改[JETTY_HOME ...
- 32+激发灵感的HTML5/CSS3网页设计教程
HTML5是寄托在HTML4基础上取得了的广泛成就.这不仅意味着你不必完全放弃现有的一些标记,而是可以借鉴,以加强 它. CSS3也以同样的方式在互联网内容的安排下,提供了它的柔韧性.CSS3是开 ...
- 40个超酷的jQuery动画效果教程
自从出现,jQuery就在web领域就引起了轰动,现在它已经成为Web动画效果的最佳解决方案之一.jQuery提供了良好的交叉浏览器支持,并且轻便易用.现在,jQuery在定义和控制小型的Web动画诸 ...