转:Scrapy安装、爬虫入门教程、爬虫实例(豆瓣电影爬虫)
Scrapy在window上的安装教程见下面的链接:Scrapy安装教程
上述安装教程已实践,可行。(本来打算在ubuntu上安装Scrapy的,但是Ubuntu 磁盘空间太少了,还没扩展磁盘空间,所以没有在Ubuntu上装,至于如何在Ubuntu上安装Scrapy,网上有挺多教程的)
Scrapy的入门教程见下面链接:Scrapy入门教程
上面的入门教程是很基础的,先跟着作者走一遍,要动起来哟,不要只是阅读上面的那篇入门教程。
下面我简单总结一下Scrapy爬虫过程:
1、在Item中定义自己要抓取的数据:
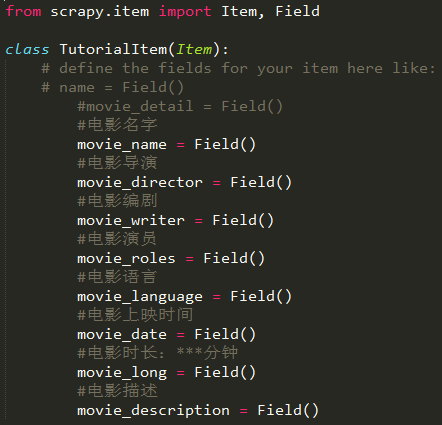
movie_name就像是字典中的“键”,爬到的数据就像似字典中的“值”。在继承了BaseSpider的类中会用到:
 第一行就是上面那个图中的TutorialItem这个类,红框圈出来的就是上图中的movie_name这个变量
第一行就是上面那个图中的TutorialItem这个类,红框圈出来的就是上图中的movie_name这个变量
2、然后在spiders目录下编辑Spider.py那个文件
按上面【入门教程】来写就行了,我这边给个例子,跟我上面的item是匹配的:
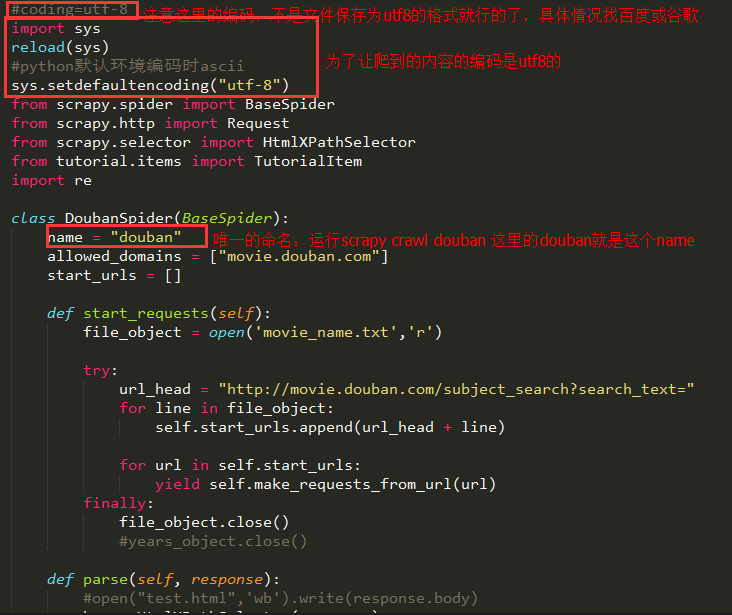
【入门教程】你没有给出start_requests这个方法,稍后我会讲到这个方法。另外这里的代码我都是截图,后面我会用代码面板显示我的代码,有需要的人可以复制下来玩玩。
3、编辑pipelines.py文件,可以通过它将保存在TutorialItem中的内容写入到数据库或者文件中
下面的代码示例是写到文件(如果要写到数据库中去,这里有个示例代码)中去:

对json模块的方法的注释:dump和dumps(从Python生成 JSON),load和loads(解析JSON成Python的数据类型);dump和dumps的唯一区别是dump会生成一个类文件对 象,dumps会生成字符串,同理load和loads分别解析类文件对象和字符串格式的JSON。(注释来于http://www.jb51.net/article/52224.htm )
4、爬虫开始
上述三个过程后就可以爬虫了,仅需上述三个过程哟,然后在dos中将目录切换到tutorial下输入scrapy crawl douban就可以爬啦:

上面几个过程只是先理清楚用Scrapy爬虫的思路,下面的重点戏是第二个过程,我会对这个过程进行较详细的解释,并提供代码。
douban_spider.py这个文件的代码如下:
douban_spider.py
代码有了,我来一步步讲解哈。
前言:我要爬的是豆瓣的数据,我有了很多电影的名字,但是我需要电影的详情,我用了一下豆瓣电影的网站,发现当我在搜索框里输入“Last Days in Vietnam”时url会变成http://movie.douban.com/subject_search?search_text=Last+Days+in+Vietnam&cat=1002 然后我就试着直接输入http://movie.douban.com/subject_search?search_text=Last+Days+in+Vietnam这个url,搜索结果是一样的,很显然这就是get方式,这样我们就找到了规律:http://movie.douban.com/subject_search?search_text=后面加上我们的电影名字并用加号分割就行了。
我们的电影名字(大量的电影名字)是存在movie_name.txt这个文件中里面的(一行一个电影名字):
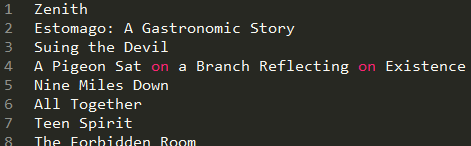
我们可以先用python脚本(shell脚本也行)将电影名之间的空格处理为+,也可以在爬虫中读取电影名后进行一次replace处理(我是先处理成+的)。爬 虫读取电影名字文件,然后构建url,然后就根据得到的网页找到搜索到的第一个电影的url(其实第一个电影未必一定是我们要的,但是这种情况是少数,我 们暂时不理会它),得到第一个电影的url后,再继续爬,这次爬到的页面就含有我们想要的电影信息,需要使用XPath来获得html文件中元素节点,最 后将获得的信息存到TutorialItem中,通过pipelines写入到data.dat文件中。
XPath的教程在这里:w3school的基础教程和scrapy官网上的Xpath 这些东西【入门教程】中都有说。
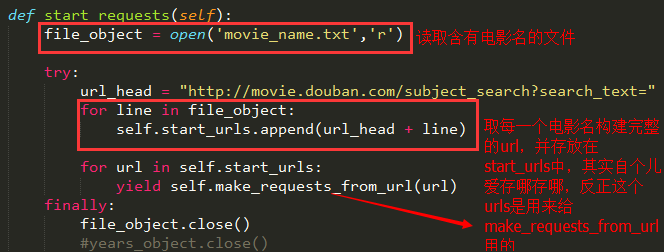
1、start_requests方法:
在【入门教程】那篇文章中没有用到这个方法,而是直接在start_urls中存入我们要爬虫的网页链接,但是如果我们要爬虫的链接很多,而且是有一定规律的,我们就需要重写这个方法了,首先我们看看start_requests这个方法是干嘛的:
 可见它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request,
可见它就是从start_urls中读取链接,然后使用make_requests_from_url生成Request,
start_requests官方解释在这里
那么这就意味我们可以在start_requests方法中根据我们自己的需求往start_urls中写入我们自定义的规律的链接:
2、parse方法:
生成了请求后,scrapy会帮我们处理Request请求,然后获得请求的url的网站的响应response,parse就可以用来处理response的内容。在我们继承的类中重写parse方法:

parse_item是我们自定义的方法,用来处理新连接的request后获得的response:
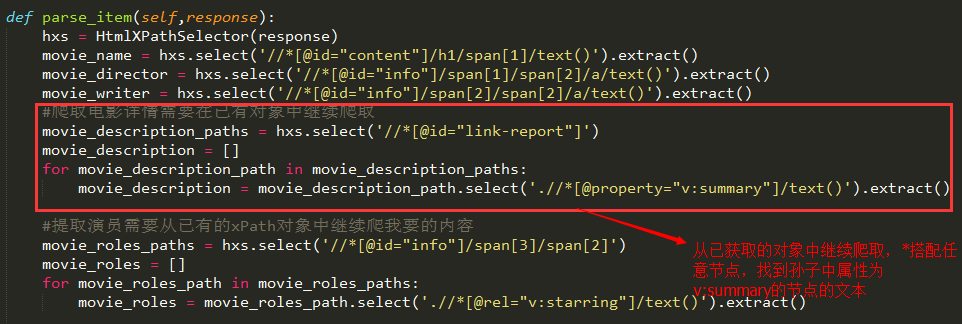
HtmlXPathSelector的解释在这里
为了获得我想要的数据我也是蛮拼的,由于豆瓣电影详情的节点是没太大规律了,我后面还用了正则表达式去获取我要的内容,具体看上面的代码中parse_item这个方法吧:
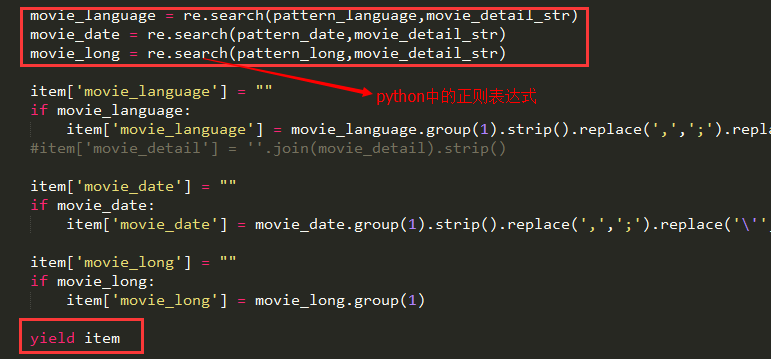
好了,结束了,这里还有一篇Scrapy的提高篇,有兴趣的去看看吧。
写写博客是为了记录一下自己实践的过程,也希望能对需要者有用吧!
转:Scrapy安装、爬虫入门教程、爬虫实例(豆瓣电影爬虫)的更多相关文章
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- Python爬虫入门教程 37-100 云沃客项目外包网数据爬虫 scrapy
爬前叨叨 2019年开始了,今年计划写一整年的博客呢~,第一篇博客写一下 一个外包网站的爬虫,万一你从这个外包网站弄点外快呢,呵呵哒 数据分析 官方网址为 https://www.clouderwor ...
- Python爬虫入门教程 36-100 酷安网全站应用爬虫 scrapy
爬前叨叨 2018年就要结束了,还有4天,就要开始写2019年的教程了,没啥感动的,一年就这么过去了,今天要爬取一个网站叫做酷安,是一个应用商店,大家可以尝试从手机APP爬取,不过爬取APP的博客,我 ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
- Python爬虫入门教程 48-100 使用mitmdump抓取手机惠农APP-手机APP爬虫部分
1. 爬取前的分析 mitmdump是mitmproxy的命令行接口,比Fiddler.Charles等工具方便的地方是它可以对接Python脚本. 有了它我们可以不用手动截获和分析HTTP请求和响应 ...
- scrapy安装及入门使用
scrapy安装及入门使用 安装 pip3.7 install Scrapy 输入scrapy命令查看是否安装成功 J-pro:myproject will$ scrapy Scrapy 2.1.0 ...
- Python 3.6.3 官网 下载 安装 测试 入门教程 (windows)
1. 官网下载 Python 3.6.3 访问 Python 官网 https://www.python.org/ 点击 Downloads => Python 3.6.3 下载 Python ...
- 《挑战30天C++入门极限》入门教程:实例详解C++友元
入门教程:实例详解C++友元 在说明什么是友元之前,我们先说明一下为什么需要友元与友元的缺点: 通常对于普通函数来说,要访问类的保护成员是不可能的,如果想这么做那么必须把类的成员都生命成为pu ...
- Java豆瓣电影爬虫——抓取电影详情和电影短评数据
一直想做个这样的爬虫:定制自己的种子,爬取想要的数据,做点力所能及的小分析.正好,这段时间宝宝出生,一边陪宝宝和宝妈,一边把自己做的这个豆瓣电影爬虫的数据采集部分跑起来.现在做一个概要的介绍和演示. ...
随机推荐
- javascript的词法分析
-.arguments的解释: 1.是一个对象,是一个长的很像数组的对象 二.arguments内容是什么? 1.arguments是函数运行时的实参列表 2.arguments收集的“所有”的实参, ...
- iOS开发 获取手机信息(UIDevice,NSBundle,NSlocale)
在开发中,需要获取当前设备的一些信息,可以通过UIDevice,NSbundle,NSlocale获取. UIDevice UIDevice 提供了多种属性,类函数及状态通知,可以检测手机电量,定位, ...
- Matrix_二维树状数组
Description Given an N*N matrix A, whose elements are either 0 or 1. A[i, j] means the number in the ...
- 第一个Sprint冲刺第四天
讨论成员:邵家文.李新.朱浩龙.陈俊金 讨论问题:掌握计时技术的知识 讨论地点:qq网络 进展:即将开始对计时技术代码的编写
- mac自带apache服务器开启
mac的os x操作系统自带的有apach服务器, 命令行: sudo apachectl -v 可查看自带apache版本信息 输入: sudo apachectl start 就开启了apa ...
- QMP ( qemu monitor protocol ) and Different ways of accessing it
The QEMU Monitor Protocol (QMP) is a JSON-based protocol which allows applications to communicate wi ...
- html5表单新特性
type=range 值区域范围 默认值(0-100) type=data 选择日期 type=color value='初始值' 颜色选择器控件 type=search 搜索框效果 type=im ...
- MySQL备份的shell脚本
经过测试该脚本可以远程备份,但需要配置远程登录用户的权限,经过测试啊,在把这个脚本添加到计划任务的时候是无法识别mysql命令的(即使是将mysql添加到环境变量也无法识别,是因为/etc/cront ...
- Codeforces Round #131 (Div. 2)
A. System of Equations \(a\)的范围在\(\sqrt n\)内,所以暴力枚举即可. B. Hometask 需要被2.5整除,所以末位必然为0,如果0没有出现,则直接返回-1 ...
- 2016 MIPT Pre-Finals Workshop Taiwan NTU Contest
2016弱校联盟十一专场10.5 传送门 A. As Easy As Possible 假设固定左端点,那么每次都是贪心的匹配\(easy\)这个单词. 从\(l\)开始匹配的单词,将\(y\)的位置 ...