1、Hibernate之生成SessionFactory源码追踪
Hibernate的所有session都是由sessionFactory来生成的,那么,sessionFactory是怎么得来的呢?它与我们配置的xxx.cfg.xml文件以及xxx.hbm.xml文件之间又有着怎么样的联系呢?
先看一小段生成sessionFactory的代码:
code_1:
public class HibernateTest {
@Test
public void test() {
System.out.println("test...");
//1. 创建一个 SessionFactory 对象
SessionFactory sessionFactory = null;
//1). 创建 Configuration 对象: 对应 hibernate 的基本配置信息和 对象关系映射信息
Configuration configuration = new Configuration().configure();
//4.0 之前这样创建
//sessionFactory = configuration.buildSessionFactory();
//2). 创建一个 ServiceRegistry 对象: hibernate 4.x 新添加的对象
//hibernate 的任何配置和服务都需要在该对象中注册后才能有效.
ServiceRegistry serviceRegistry =
new ServiceRegistryBuilder().applySettings(configuration.getProperties())
.buildServiceRegistry();
//3). 利用serviceRegistry来创建sessionFactory实例
sessionFactory = configuration.buildSessionFactory(serviceRegistry);
//2. 创建一个 Session 对象
Session session = sessionFactory.openSession();
//3. 开启事务
Transaction transaction = session.beginTransaction();
//4. 执行保存操作
News news = new News("Java12345", "ATGUIGU", new Date(new java.util.Date().getTime()));
session.save(news);
//5. 提交事务
transaction.commit();
//6. 关闭 Session
session.close();
//7. 关闭 SessionFactory 对象
sessionFactory.close();
}
}
从上面的代码很清晰的可以看见,这一切的源头都在 Configuration configuration = new Configuration().configure() 这条语句上:创建ServiceRegistry 需要用到configuration,生成sessionFactory同样需要用到configuration。
Configuration的生成过程
从源代码中可以看到,Configuration的configure()方法共有5中重载方式:
code_2:
public Configuration configure(); //无参
public Configuration configure(String resource)
public Configuration configure(URL url)
public Configuration configure(File configFile)
public Configuration configure(org.w3c.dom.Document document)
现在从无参的configure()方法开始分析,它代表了一种默认的行为,默认读取类路径下的hibernate.cfg.xml文件作为hibernate的配置文件:
code_3:
public Configuration configure() throws HibernateException {
configure( "/hibernate.cfg.xml" ); //默认读取classpath路径下的hibernate.cfg.xml文件
return this;
}
继续追踪configure( "/hibernate.cfg.xml" )方法:
code_4:
public Configuration configure(String resource) throws HibernateException {
InputStream stream = getConfigurationInputStream( resource ); //通过传入的资源路径获取一个输入流
return doConfigure( stream, resource ); //这个方法会完成解析的第一步:将输入流转换成Document对象
}
继续追踪 return doConfigure( stream, resource ) 语句,可以发现底层会通过SAX解析工具将输入流转换成Document对象。然后调用然后调用doConfigure(Document doc)来继续解析这个文档:
code_5:
protected Configuration doConfigure(InputStream stream, String resourceName) throws HibernateException {
ErrorLogger errorLogger = new ErrorLogger( resourceName ); //将输入流转换成Document对象
Document document = xmlHelper.createSAXReader( errorLogger, entityResolver )
.read( new InputSource( stream ) );
//具体解析document树,并将结果以键值对的形式存放到properties中
doConfigure( document );
return this;
}
doConfigure(Document doc)是实际解析文档的方法,前面configure()的5种重载方法最后都要调用这个方法来完成实际的解析。我们看看它的解析思路:
code_6:
protected Configuration doConfigure(Document doc) throws HibernateException {
Element sfNode = doc.getRootElement().element( "session-factory" );
String name = sfNode.attributeValue( "name" );
if ( name != null ) { //session-factory根节点是可以有name属性值的
properties.setProperty( Environment.SESSION_FACTORY_NAME, name );
}
//遍历文档中所有的property节点,读取器name属性值以及节点的文本,
//以name-value的形式放入到properties中
addProperties( sfNode );
//解析除了property之外的节点:mapping、class-cache、collection-cache
parseSessionFactory( sfNode, name );
Element secNode = doc.getRootElement().element( "security" );
if ( secNode != null ) {
parseSecurity( secNode );
}
LOG.configuredSessionFactory( name );
LOG.debugf( "Properties: %s", properties );
return this;
}
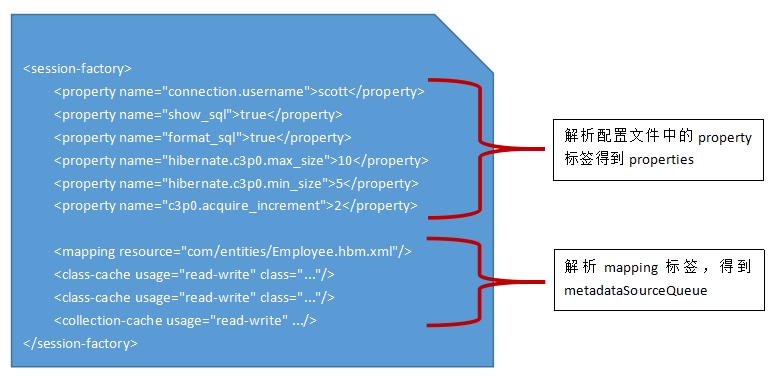
doConfigure(Document doc)方法中对Document的解析主要分为两个步骤进行:①解析xxx.cfg.xml配置文档中所有的property节点;②解析xxx.cfg.xml配置文档中除了property节点之外的其它5种节点。
先来看看第①步,它在addProperties(...)方法中完成(code_6代码段的第9行)思路很清晰,用一个迭代器来遍历文档中所有的property节点,并将name-value存放到Configuration的properties属性中:
code_7:
private void addProperties(Element parent) {
//指定,只会遍历property节点
Iterator itr = parent.elementIterator( "property" );
while ( itr.hasNext() ) {//循环遍历
Element node = (Element) itr.next();
//读取节点的name属性值
String name = node.attributeValue( "name" );
//读取节点的文本值
String value = node.getText().trim();
LOG.debugf( "%s=%s", name, value );
//将name-value值存放如properties中
properties.setProperty( name, value );
//待研究...
if ( !name.startsWith( "hibernate" ) ) {
properties.setProperty( "hibernate." + name, value );
}
}
Environment.verifyProperties( properties );
}
再来看看第②步,它在parseSessionFactory( ...)方法中进行(code_6代码段的第10行),它主要解析3类标签:mapping、class-cache、collection-cache:
code_8:
private void parseSessionFactory(Element sfNode, String name) {
Iterator elements = sfNode.elementIterator();
while ( elements.hasNext() ) {
Element subelement = (Element) elements.next();
String subelementName = subelement.getName();
//解析mapping节点,mapping可以指定hibernate的映射文件位置
if ( "mapping".equals( subelementName ) ) {
//具体解析mapping节点
parseMappingElement( subelement, name );
}
//下面两个是和hibernate的二级缓存相关的配置,不做深入探讨
else if ( "class-cache".equals( subelementName ) ) {
String className = subelement.attributeValue( "class" );
Attribute regionNode = subelement.attribute( "region" );
final String region = ( regionNode == null ) ? className : regionNode.getValue();
boolean includeLazy = !"non-lazy".equals( subelement.attributeValue( "include" ) );
setCacheConcurrencyStrategy( className, subelement.attributeValue( "usage" ), region, includeLazy );
}
else if ( "collection-cache".equals( subelementName ) ) {
String role = subelement.attributeValue( "collection" );
Attribute regionNode = subelement.attribute( "region" );
final String region = ( regionNode == null ) ? role : regionNode.getValue();
setCollectionCacheConcurrencyStrategy( role, subelement.attributeValue( "usage" ), region );
}
}
}
后面两个标签class-cache和collection-cache是和hibernate的二级缓存相关,不作深入探讨。主要看看解析mapping的方法:
code_9:
private void parseMappingElement(Element mappingElement, String name) {
//从源代码可以看出,mapping节点支持的属性值有5个
final Attribute resourceAttribute = mappingElement.attribute( "resource" );
final Attribute fileAttribute = mappingElement.attribute( "file" );
final Attribute jarAttribute = mappingElement.attribute( "jar" );
final Attribute packageAttribute = mappingElement.attribute( "package" );
final Attribute classAttribute = mappingElement.attribute( "class" );
if ( resourceAttribute != null ) {
final String resourceName = resourceAttribute.getValue();
LOG.debugf( "Session-factory config [%s] named resource [%s] for mapping", name, resourceName );
//将hibernate的映射文件作进一步的解析
addResource( resourceName );
}
else if ( fileAttribute != null ) {
final String fileName = fileAttribute.getValue();
LOG.debugf( "Session-factory config [%s] named file [%s] for mapping", name, fileName );
addFile( fileName );
}
else if ( jarAttribute != null ) {
final String jarFileName = jarAttribute.getValue();
LOG.debugf( "Session-factory config [%s] named jar file [%s] for mapping", name, jarFileName );
addJar( new File( jarFileName ) );
}
else if ( packageAttribute != null ) {
final String packageName = packageAttribute.getValue();
LOG.debugf( "Session-factory config [%s] named package [%s] for mapping", name, packageName );
addPackage( packageName );
}
else if ( classAttribute != null ) {
final String className = classAttribute.getValue();
LOG.debugf( "Session-factory config [%s] named class [%s] for mapping", name, className );
try {
addAnnotatedClass( ReflectHelper.classForName( className ) );
}
catch ( Exception e ) {
throw new MappingException(
"Unable to load class [ " + className + "] declared in Hibernate configuration <mapping/> entry",
e
);
}
}
else {
throw new MappingException( "<mapping> element in configuration specifies no known attributes" );
}
}
addResource( resourceName )是如何解析的呢?那么它是如何工作的呢?这里不再一步一步追踪源代码,因为嵌套太深,直接给出一个感性的认识即可:
在Configuration中定义了一个名为MetadataSourceQueue的内部内,同时Configuration中还有一个该队列的属性值:metadataSourceQueue。
addResource( resourceName )方法嵌套到最后会调用metadataSourceQueue.add(...)方法来将映射的元数据存储到metadataSourceQueue队列中。要使用的时候,从该队列中取就可以了。
metadataSourceQueue的底层存储是一个Map类型...
到现在为止,Configuration对象就得到了,总结一下,其重要的几个点:
1、configure()方法默认读取/hibernate.cfg.xml作为hibernate的配置文件。当然,configure()方法还有其它重载形式可用。
2、doConfigure(Document document)方法会调用两个重要的方法:addProperties( sfNode )和parseSessionFactory( sfNode, name );
3、addProperties( sfNode )方法会解析配置文件中的property节点,并将解析到的name-value放入到properties中
4、parseSessionFactory( sfNode, name )方法会解析配置文件中除了property节点外的其它3个类型的节点(4.2版本):mapping、class-cache和collection-cache
5、mapping配置是和映射相关的,class-cache和collection-cache是与二级缓存相关的。
6、mapping解析的结果会存放到metadataSourceQueue对象中。
7、所以,整个过程得到Configuration中两个重要的属性值:properties和metadataSourceQueue。
1、Hibernate之生成SessionFactory源码追踪的更多相关文章
- Hibernate 5.x 生成 SessionFactory 源码跟踪分析
我们要使用 Hibernate 的功能,首先需要读取 Hibernate 的配置文件,根据配置启动 Hibernate ,然后创建 SessionFactory. 创建 SessionFactory ...
- 源码追踪,解决Could not locate executable null\bin\winutils.exe in the Hadoop binaries.问题
在windows系统本地运行spark的wordcount程序,会出现一个异常,但不影响现有程序运行. >>提君博客原创 http://www.cnblogs.com/tijun/ & ...
- Saiku登录源码追踪.(十三)
Saiku登录源码追踪呀~ >>首先我们需要debug跟踪saiku登录执行的源码信息 saiku源码的debug方式上一篇博客已有说明,这里简单介绍一下 在saiku启动脚本中添加如下命 ...
- Spring Boot 注解之ObjectProvider源码追踪
最近依旧在学习阅读Spring Boot的源代码,在此过程中涉及到很多在日常项目中比较少见的功能特性,对此深入研究一下,也挺有意思,这也是阅读源码的魅力之一.这里写成文章,分享给大家. 自动配置中的O ...
- Google Protocol Buffers 快速入门(带生成C#源码的方法)
Google Protocol Buffers是google出品的一个协议生成工具,特点就是跨平台,效率高,速度快,对我们自己的程序定义和使用私有协议很有帮助. Protocol Buffers入门: ...
- 身份证号码查询与生成(C#源码)
项目要用到这个功能,就写了一个,完整类也就二百来行,很简单.可以在项目中用,也可以作为学习. 源码下载 http://yunpan.cn/cmQCSWkhDnZLJ 访问密码 0227 核心代码如下 ...
- 2018-09-13 代码翻译尝试-使用Roaster解析和生成Java源码
此文是前文使用现有在线翻译服务进行代码翻译的体验的编程语言方面第二点的一个尝试. 参考Which framework to generate source code ? - Cleancode and ...
- corefx 源码追踪:找到引起 SqlDataReader.ReadAsync 执行延迟的那行代码
最近遇到一个非常诡异的问题,在一个 ASP.NET Core 2.2 项目中,从 SQL Server 数据库查询 100 条数据记录,会出现 16-22s 左右的延迟.延迟出现在执行 SqlData ...
- iOS雪花动画、音频图、新闻界面框架、2048游戏、二维码条形码扫码生成等源码
iOS精选源码 粒子雪花与烟花的动画 iOS 2048游戏 JHSoundWaveView - 简单地声波图.音波图 一个可快速集成的新闻详情界面框架,类似今日头条,腾讯新闻 二维码/条形码扫描及扫描 ...
随机推荐
- [转载]ubuntu下如何更改mysql数据存放路径
http://www.gaojinbo.com/ubuntu%E4%B8%8B%E5%A6%82%E4%BD%95%E6%9B%B4%E6%94%B9mysql%E6%95%B0%E6%8D%AE%E ...
- Yandex.Algorithm 2011 Round 1 D. Sum of Medians 线段树
题目链接: Sum of Medians Time Limit:3000MSMemory Limit:262144KB 问题描述 In one well-known algorithm of find ...
- 【转载】Sencha Touch 提高篇 组件选择器
免责声明: 本文转自网络文章,转载此文章仅为个人收藏,分享知识,如有侵权,请联系博主进行删除. 原文作者:威老 原文地址:http://www.cnblogs.com/weil ...
- 01.Hibernate入门
前言:本文用一个简单的Hibernate应用程序例子来引领初学者入门,让初学者对Hibernate的使用有一个大致的认识.本文例子使用了MySQL数据库.Maven管理工具.Eclipse开发工具,创 ...
- poj 1273 Drainage Ditches 最大流入门题
题目链接:http://poj.org/problem?id=1273 Every time it rains on Farmer John's fields, a pond forms over B ...
- 【BZOJ】【1449】【JSOI2009】球队收益
网络流/费用流/二分图最小权匹配 题解:http://blog.csdn.net/huzecong/article/details/9119741 太神了!由于一赢一输不好建图,就先假设全部都输,再将 ...
- 一个包的net到gs流程
再来看看一个包走共享内存的流程 先来看看net进程这块如何处理的 {//用shareData这种类型封装刚才从无锁队列中取到的包 shareData sd; sd.channel_id = pkt.c ...
- 小试牛刀MVC简单网页
上次我们创建了第一个MVC的网站,没用下,这次就简单来运行下,首先大家要去理解下MVC模式到底什么关系.在这里我就不多说,直接创建一个网页,用来显示一些数据,数据库的话我就先简单用这样创建先,为了方便 ...
- WSDL
WSDL 彻底理解webservice SOAP WSDL WSDL 详解 http://www.cnblogs.com/hujian/p/3494064.html http://www.cnblog ...
- hadoop-ha QJM架构应用故障总结
部署hadoop-ha QJM架构过程我就不说了,参考 我的博客:hadoop-ha QJM架构部署故障一: namenode 报错日志如下: WARN org.apache.hadoop.hd ...