week07 13.2 NewsPipeline之 二 News Fetcher - Xpath
我们使用Xpath来专门做一个scrapter
我们专门弄个文件夹 里面全部是 各个新闻源(CNN BBC等)的scraper来抓取网站的text内容


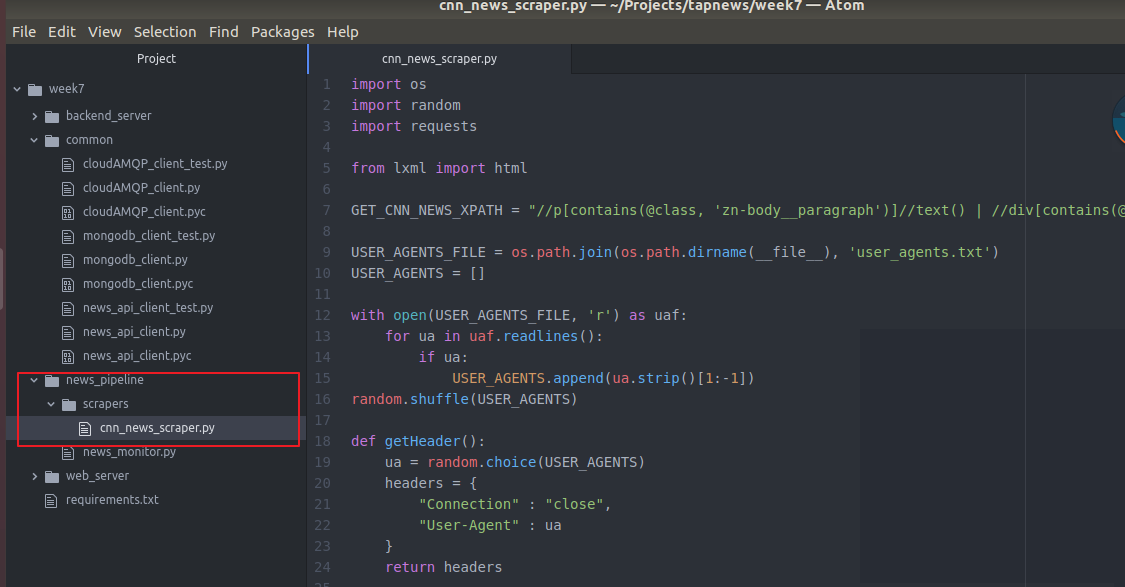
主要函数(就是传入text内容的那个url)然后进行抓取内容 返回 news 一会写具体内容

这个函数主要做3件事
首先 download 这个url 获取html
然后 parse html 成 tree
组合 extract information(提取信息 用Xpath或者后边自动爬内容的 第三方库 newspaper) 这里我们现用Xpath 后边再优化

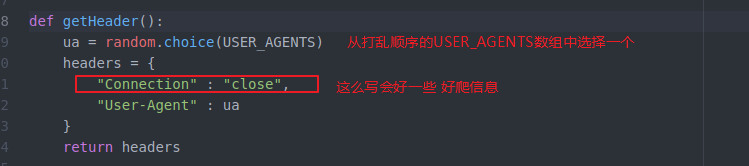
进行2次伪装

下一步就是伪装header

这里需要一个 我们自己准备一个useragent的list表 每次随机从里面选一个 作为我们的useragend header
有了表 我们就要用这个表



最后再用random重新洗牌

然后 通过上面伪装的2个 去请求目标url 返回目标url的内容text 用response接收

网站获得我们的请求 查看我们的session和header就会
认为我们是正常的用户 不是机器人就会返回我们要的text 我们 就可以一直爬信息 不然就会被认为是机器人 而被拒绝或者封ip
我们获得了目标url的html
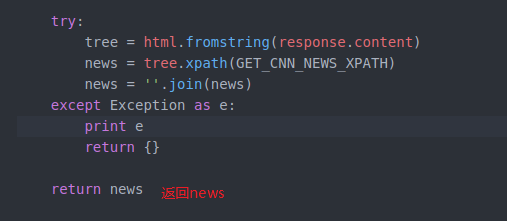
就开始做第二步了 解析这个html
我们把他放在try里面 即使失误了 也可以跳过执行后边的程序 不至于导致不work

这个包安装一下


写入文件
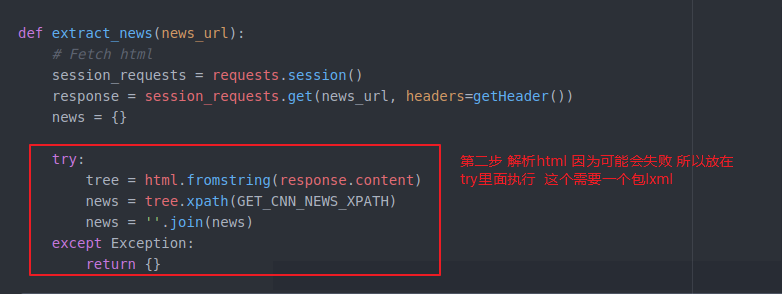
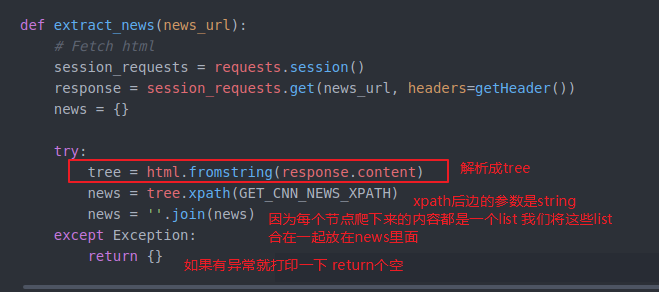
GET_CNN_NEWS_XPATH = "//p[contains(@class, 'zn-body__paragraph')]//text() | //div[contains(@class, 'zn-body__paragraph')]//text()"
GET_CNN_NEWS_XPATH
里面//就是不管结构 就是对所有的节点都有效 p就是p标签 contains就是包含 (cnn网站的内容) // text()获得text | 组合(加上)后边根据条件获得div快内的text()内容拼接
这个string内容(绿色)是咋来的呢?其实是我们自己弄来的 根据cnn这个具体新闻页面(找到我们要的text内容的部分,不过几千行不好找),我们从第一个Q里面获得我们news monotor抓的新闻摘要,从里面找到我们将来要爬的url

http://us.cnn.com/2018/09/06/politics/the-25th-amendment-requires-political-apocalypse/index.html
打开看看
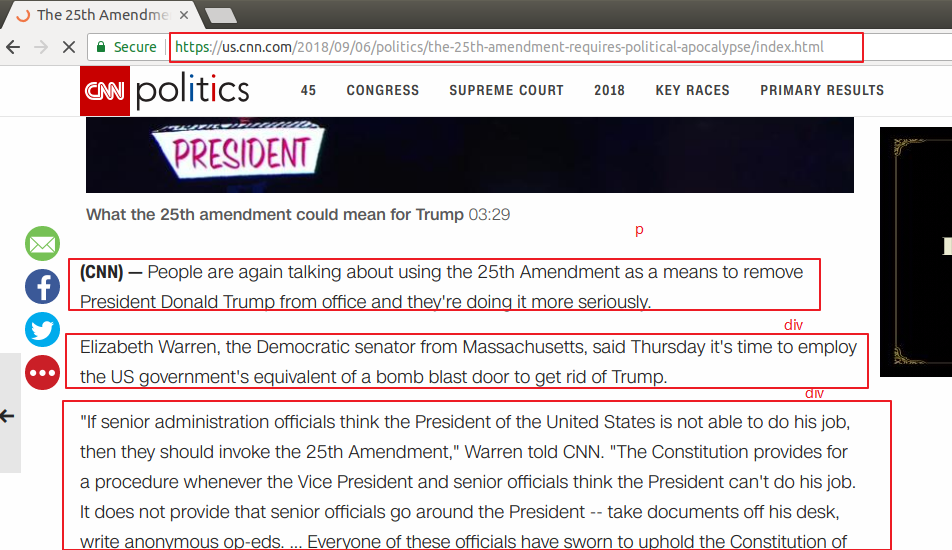
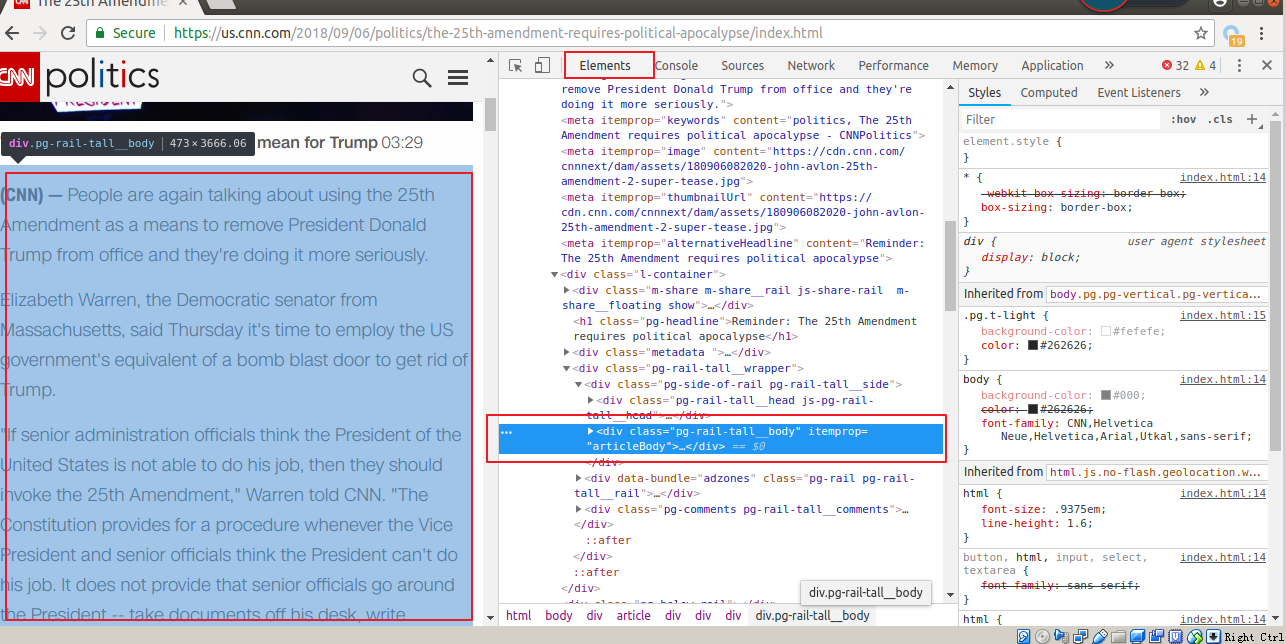
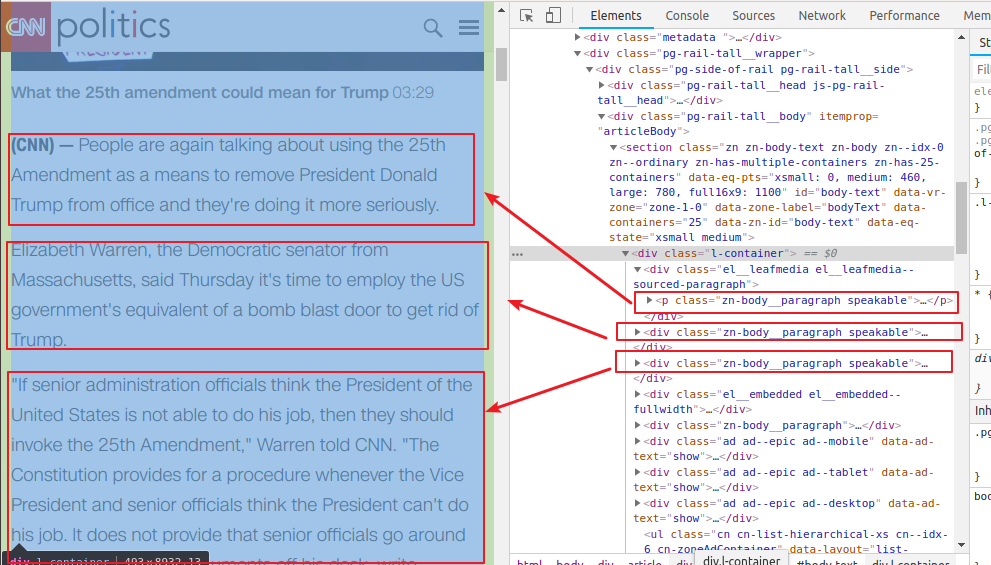
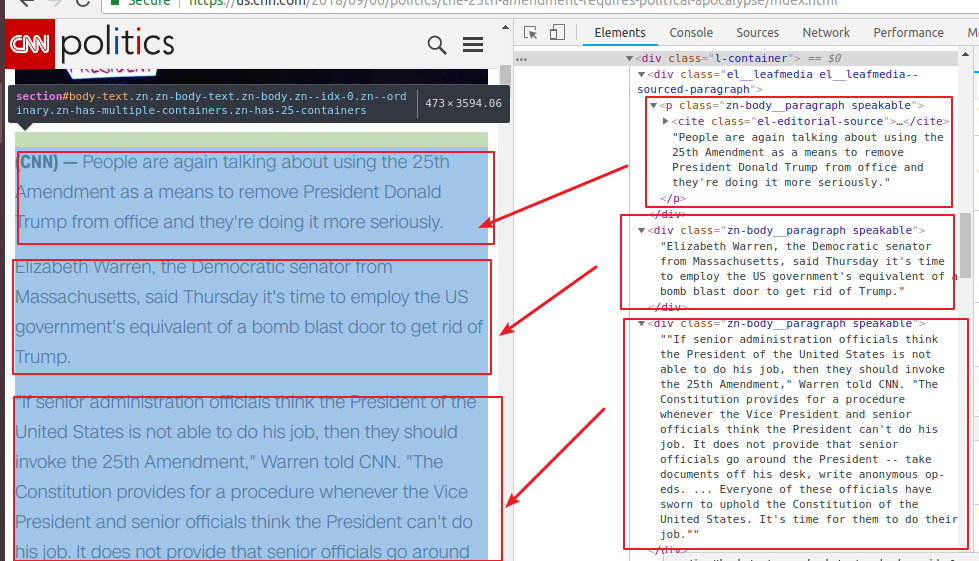
虽然这样也可以找到但是总归是要自己进去一层层找还是比较麻烦的
所以我们用解析工具(获取绿字内容)他的用法也很简单

安装这个插件

使用方法
https://chrome.google.com/webstore/detail/xpath-helper/hgimnogjllphhhkhlmebbmlgjoejdpjl
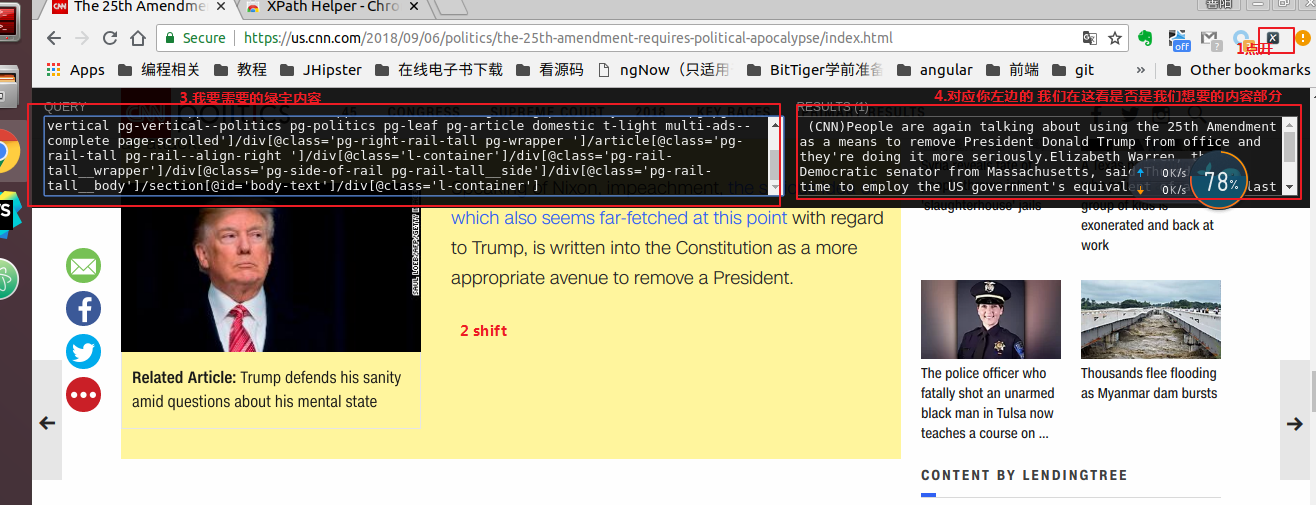
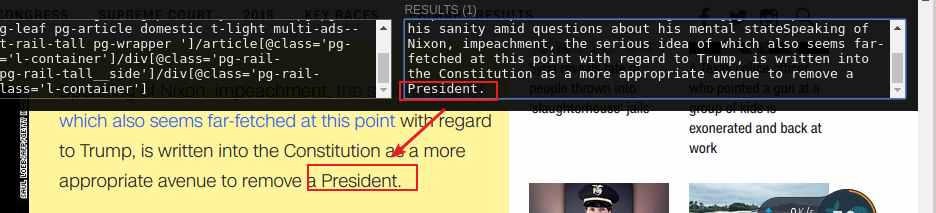
还是很方便的
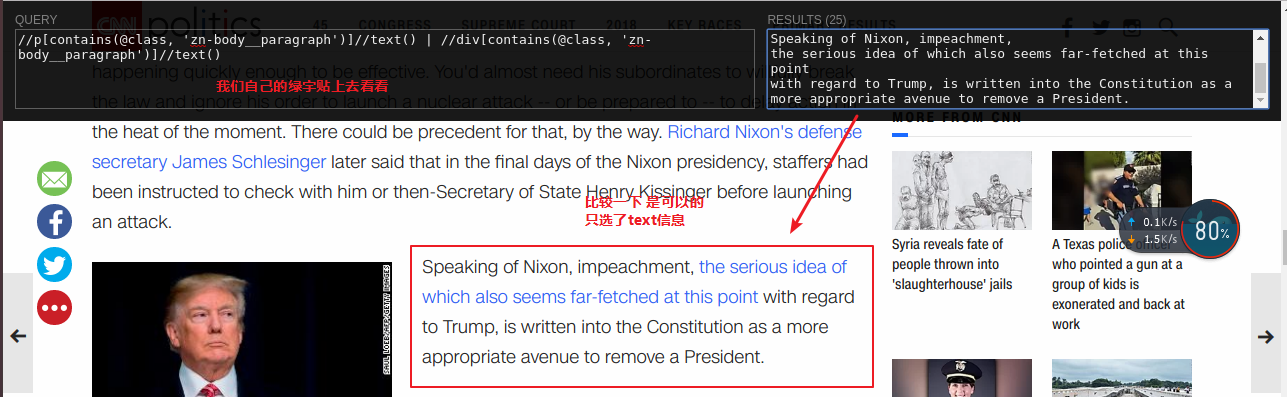
我们就是通过这样获取的XPATH
下面我们还是测试一下我的news scraper

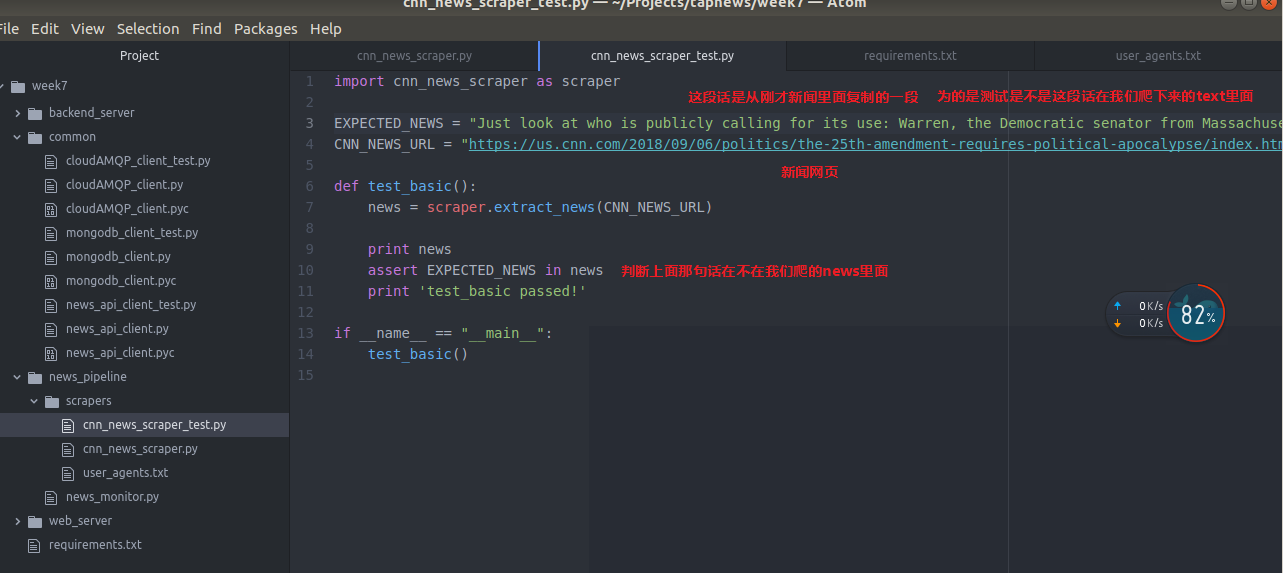
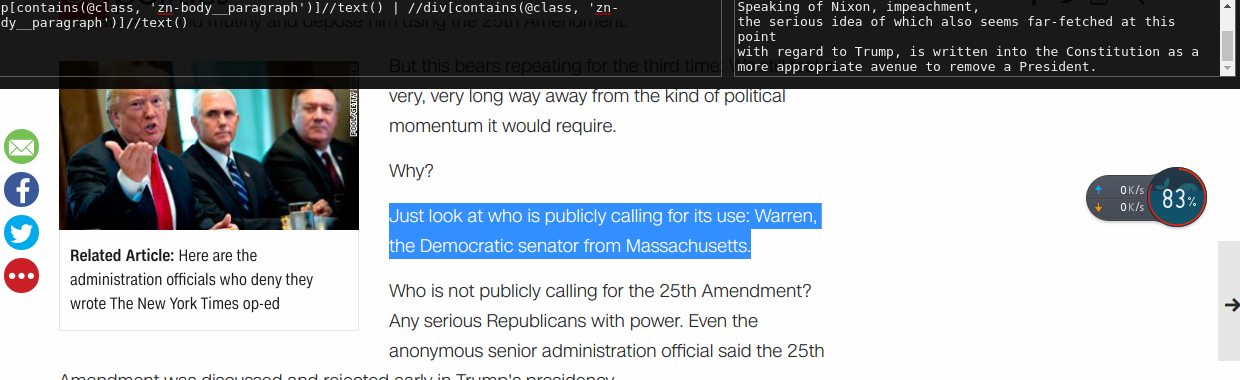
下面跑一跑
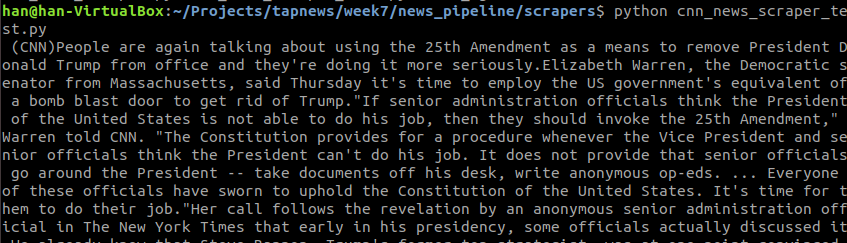

我们发现 过程很复杂 而且每个网站都不一样
你要每一个source都要写一个对应的scraper
因为结构不同嘛
XPATH不同 当然
你也可以写一个scraper 运行不同XPATH
上面我们只是抓取到了新闻text
和Q相关的操作我们还没做
下面是 news fetcher 其实和news monitor 差不多
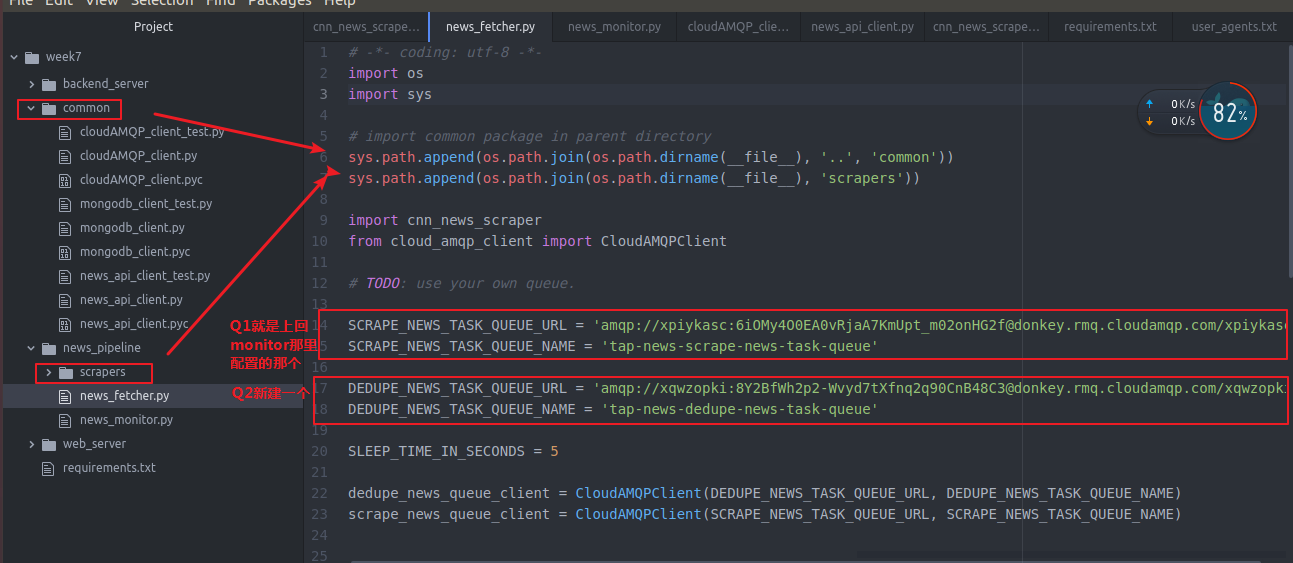

新建一个新的Q2和上次创建q一模一样
week7_demo_second_queue
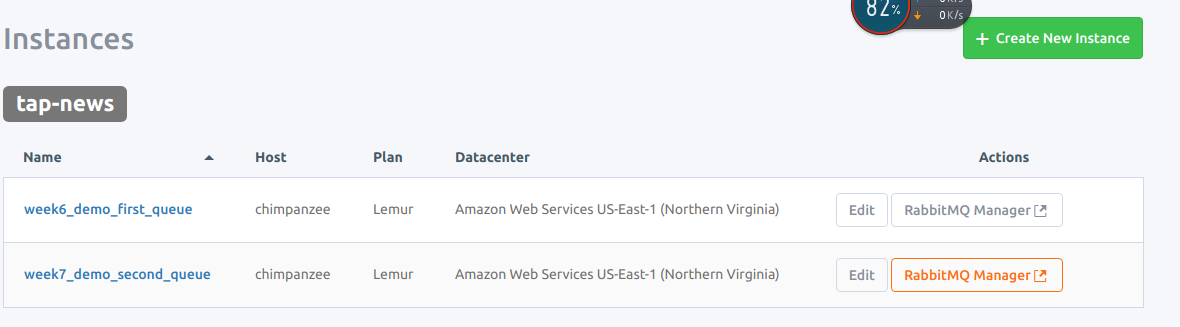
干脆名字对应吧
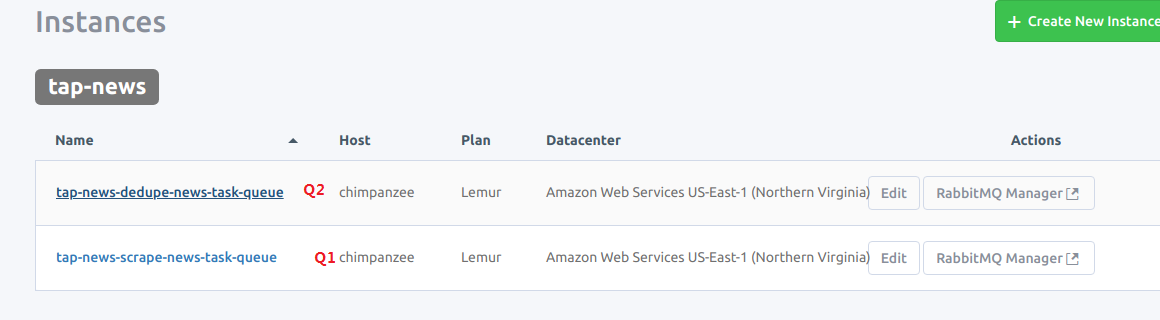




我们去看看

所以 我们判断一下源是 cnn我们在进行下面操作



我们来试试


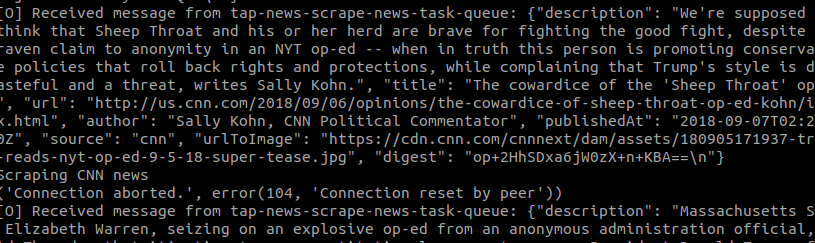
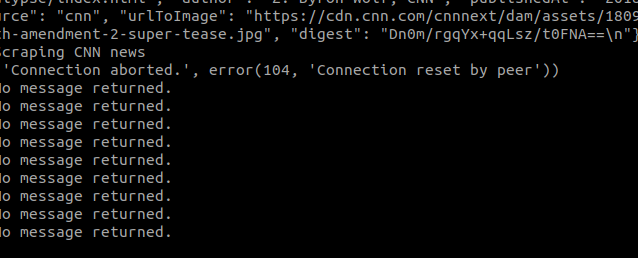
OK
week07 13.2 NewsPipeline之 二 News Fetcher - Xpath的更多相关文章
- week07 13.4 NewsPipeline之 三 News Deduper
还是循环将Q2中的东西拿出来 然后查重(去mongodb里面把一天之内的新闻都拿出来,然后把拿到的新的新闻和mongodb里一天内的新闻组一个 tf-idf的对比)可看13.3 相似度检查 如果超过一 ...
- week07 13.1 NewsPipeline之 一 NewsMonitor
我们要重构一下代码 因为我们之前写了utils 我们的NewsPipeline部分也要用到 所以我们把他们单独独立得拿出来 删掉原来的 将requirements.txt也拿出去 现在我们搬家完成 我 ...
- week07 13.3 NewsPipeline之 三News Deduper之 tf_idf 查重
我们运行看结果 安装包sklearn 安装numpy 安装scipy 终于可以啦 我们把安装的包都写在文件里面吧 4行4列 轴对称 只需要看一半就可以 横着看 竖着看都行 数值越接近1 表示越相似 我 ...
- Linux就这个范儿 第13章 打通任督二脉
Linux就这个范儿 第13章 打通任督二脉 0111010110……你有没有想过,数据从看得见或看不见的线缆上飞来飞去,是怎么实现的呢?数据传输业务的未来又在哪里?在前面两章中我们学习了Linux网 ...
- Python for Infomatics 第13章 网页服务二(译)
注:文章原文为Dr. Charles Severance 的 <Python for Informatics>.文中代码用3.4版改写,并在本机测试通过. 13.4 JavaScript ...
- HDU 4819 Mosaic(13年长春现场 二维线段树)
HDU 4819 Mosaic 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4819 题意:给定一个n*n的矩阵,每次给定一个子矩阵区域(x,y,l) ...
- 13.python基础试题(二)
借鉴:https://www.cnblogs.com/shengyang17/p/8543712.html https://www.cnblogs.com/you-wei1/p/9693254.htm ...
- cocos2dx基础篇(13) 编辑框之二CCEditBox
[3.x] (1)去掉"CC" (2)设置虚拟键盘的编辑类型 > EditBoxInputMode 变为强枚举 EditBox::EditBoxInputMode // SI ...
- 爬取伯乐在线文章(二)通过xpath提取源文件中需要的内容
爬取说明 以单个页面为例,如:http://blog.jobbole.com/110287/ 我们可以提取标题.日期.多少个评论.正文内容等 Xpath介绍 1. xpath简介 (1) xpath使 ...
随机推荐
- Windows10 64位安装TensorFlow-GPU
TensorFlow有GPU版和CPU版. GPU版需要CUDA和cuDNN支持,到链接:https://developer.nvidia.com/cuda-gpus 确认自己的显卡是否支持CUDA. ...
- python 前端 html
web 服务本质: 浏览器发出请求--HTTP协议--服务端接收信息----服务端返回响应---服务端把HTML文件发给浏览器--浏览器渲染页面. HTML: 超文本标记语言是一种用于创建网页的标记语 ...
- OpenCV中图像的格式Mat 图像深度
opencv中图像的格式Mat 有图像的定义,图像深度.类型格式等,其中Mat的参数depth为深度,深度反应出图像颜色像素值: 关于数据的储存:(转) Mat_<uchar>对应的是CV ...
- 深入学习Motan系列(五)—— 序列化与编码协议
一.序列化 1.什么是序列化和反序列化? 序列化:将对象变成有序的字节流,里面保存了对象的状态和相关描述信息. 反序列化:将有序的字节流恢复成对象. 一句话来说,就是对象的保存与恢复. 为什么需要这个 ...
- SQL Server 幻读 的真实案例
数据库中有表[01_SubjectiveScoreInfo],要实现表中的数据只被查出一次,此表数据量较大,有三四百万数据.表结构也确实不是很合理,无法修改表结构,即使是新增一个字段也会有相当大的修改 ...
- PythonStudy——Python 注释规范
注释规范: 什么是注释? 注释:不会被python解释器解释执行,是提供给开发者阅读代码的提示 单行注释: # 开头的语句 多行注释:出现在文件最上方,用''' '''包裹的语句 Pycha ...
- 5G投资逻辑
5G投资逻辑 关注光模块生产厂商. 通信射频滤波器,功率放大器生产厂商. 光无源器件的需求增多
- Unix/Linux进程间通信
一,Linux下进程间通信的几种主要手段简介: 1,管道(Pipe)及有名管道(named pipe) 管道可用于具有亲缘关系进程间的通信 有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功 ...
- Win10下JDK环境变量的设置
1.找到jdk正确的安装路径 2.打开环境变量设置 打开"资管管理器"后,右击"此电脑",点击"属性" 然后点击"高级系统设置&q ...
- PHP 从数组中删除指定元素
<?php $arr1 = array(1,3, 5,7,8); $key = array_search(3, $arr1); if ($key !== false){ array_splice ...