python基础知识点四
网络编程(socket)
软件开发的架构:
两个程序之间通讯的应用大致通过从用户层面可以分为两种:
1是C/S,即客户端与服务端,为应用类的,比如微信,网盘等需要安装桌面应用的
2是B/S,即浏览器与服务端,为web类的,不需要安装应用,直接在浏览器上使用;轻量级,成本比较低,
实际上,B/S 架构也是C/S架构的一种特殊的形式。
网络基础:
在同一台机器上要想使两个py程序通信,可以通过写文件,来传输。
但是在不同机器上的两个py程序之间想要通信,就必须依靠网络。
ip地址与ip协议:
规定网络地址的协议叫ip协议,它定义的地址称之为ip地址;就是在网络中通过知道ip地址就可以知道该电脑的位置。广泛的采用的是v4版本,即ipv4。四段十进制数,也就是4个点分 十进制。
范围: 0.0.0.0 - 255.255.255.255
127.0.0.1 本机;内网字段 192.168.****
v6 -----ipv6协议; 6个点分 十进制
范围: 0.0.0.0.0.0 - 255.255.255.255.255.255
mac地址:
每块网卡出厂时都被烧制上一个世界唯一的mac地址,长度为48位2进制,通常由12位16进制数表示
arp协议: 通过IP地址获取某一台机器的mac地址
子网掩码 :表示子网络特征的一个参数。它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0。
子网掩码 和 ip地址进行 按位 与 运算 (两个数位都为1,运算结果为1,否则为0)就能得出一个机器所在的网段。
# 子网掩码
# 子网掩码 和 ip地址进行 按位 与 运算 就能得出一个机器所在的网段
# 192.168.21.36 #128 64 32 16 8 4 2 1 (通过填位法,得到二进制的)
# 11000000.10101000.00010101.00100100
# 255.255.255.0 255.255.0.0
# 11111111.11111111.11111111.00000000
# 11000000.10101000.00010101.00000000
# 192.168.21.0 网段,若例外一个 ip地址也与子网掩码进行 按位 与 运算得到的结果是一样的话
#就说明两个ip地址在同一个网段,也就是在同一个局域网吧
网关地址 : 整个局域网中的机器能沟通过网关ip与外界通信
网段 : 子网掩码 和 ip地址进行 按位 与 运算。
端口 : 0-65535; 8000-酷狗音乐 22-ssh 3306-mysql;python 网络应用 8000;
ip地址+端口号 : 在全网找到唯一的一台机器+唯一的应用程序;
我们一般选择端口 : 8000之后。
要找的机器和你在同一个局域网内:
通过交换机
广播:和要找机器ip地址相同的服务器做出响应,将自己的ip地址返回给交换机
单播 : 把返回的信息再传递给要找机器的服务器(要找的机器和你不在同一个局域网内)
要找的机器和你不在同一个局域网内
先走交换机,交换机直接将消息传递给"网关ip"(可以与外界联系),通过ip找到对应机器所在的局域网
路由表 :网段 网关ip,通过对方局域网中的交换机进行广播把信息回传给交换机,
TCP协议:
全双工的通信协议,即一旦连接建立起来,那么连接两端的机器能够随意互相通信面向连接的通信方式
数据安全不容易丢失;是可靠的。
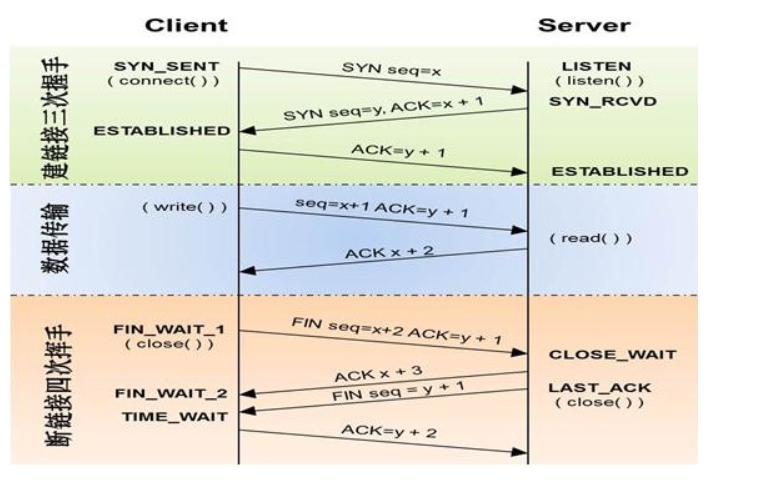
建立连接的 三次握手 ******
断开连接的 四次挥手 ******
*******为什么产生三次握手以及四次挥手的原因。
建立连接的三次握手,是在全双工通信协议下,建立了连接后,客户端接收信息以及向服务端传递信息可以同时发生。
断开连接四次挥手,是由于TCP的半关闭(从执行被动关闭一端到执行主动关闭一端流动数据是可能的
)所造成的。客户端首先调用close时,该段的TCP会发一个FIN分节(关闭的信号),表示数据发送完毕,服务端接收到这个FIN分节,服务端给客户端一个回应,客户端就执行被动的关闭了。一段时间后,服务端调用close,这导致服务端的TCP也发一个FIN分节给客户端了,客户端接收FIN后也同样给服务端一个回应,服务端也就关闭了。
UDP协议:
用户数据报协议,是一个简单的面向数据报的运输层协议。UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。由于UDP在传输数据报前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快。
而对于TCP来说,传输控制协议,提供的是面向连接、可靠的字节流服务。当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。TCP提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
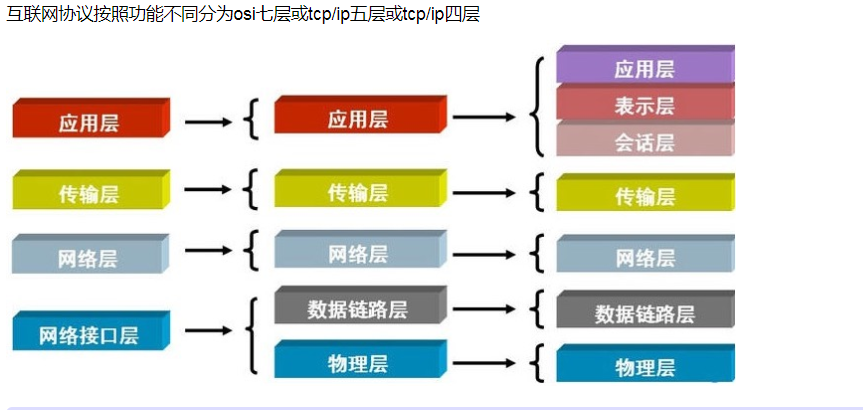
互联网协议与osi模型:
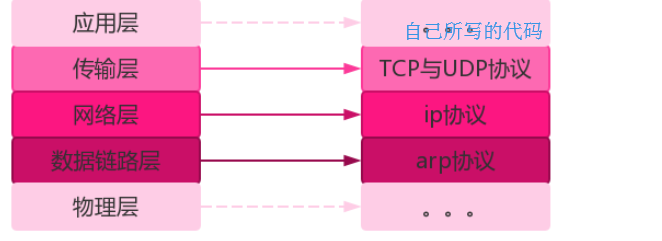
每层运行常见的协议:
socket概念
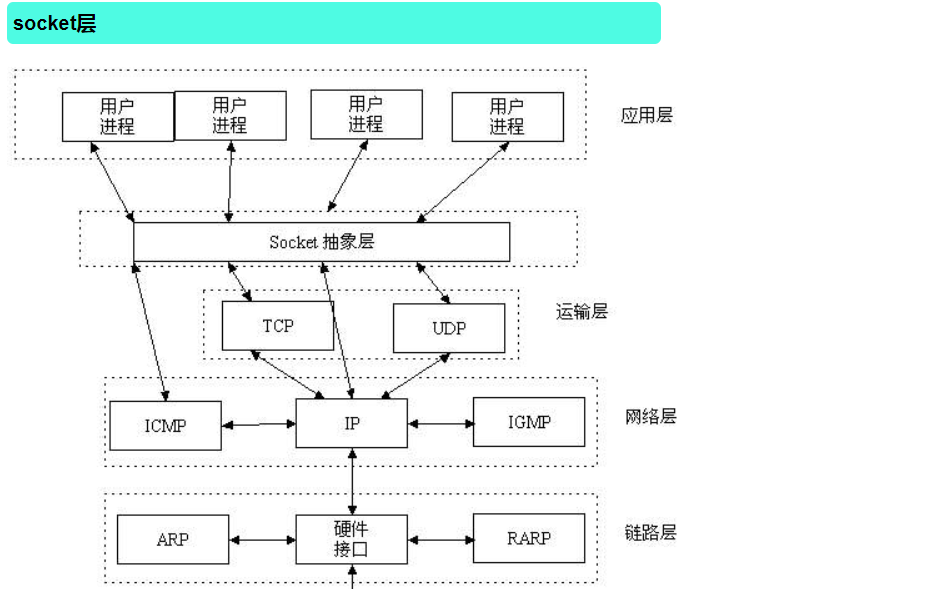
理解socket
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
其实站自己的角度上看,socket就是一个模块。我们通过调用模块中已经实现的方法建立两个进程之间的连接和通信。也有人将socket说成ip+port,因为ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序。
所以我们只要确立了ip和port就能找到一个应用程序,并且使用socket模块来与之通信。
socket也叫 套接字
基于文件类型的套接字家族: 套接字家族的名字:AF_UNIX
基于网络类型的套接字家族 :套接字家族的名字:AF_INET
基于TCP协议的socket:服务端和客户端都可以先发送信息,但是必须是一发一收
#server端
import socket
sk = socket.socket() # 创建了一个socket对象
sk.bind(('192.168.21.36',8080)) # 绑定一台机器的(ip,端口)
# 回环地址 - 指向自己这台机器
sk.listen() # 建立监听等待别人连接,后面可以接数字,表示可以接收几个客户端
conn,addr = sk.accept() # 阻塞:在这里等待直到接到一个客户端的连接,
#获取到一个客户端的连接后,就已经完成了三次握手,建立了连接
# conn是连接
# addr是对方的地址
print(conn)
print(addr)
conn.send(b'hello') # 和对方打招呼,数据的类型为bytes类型
msg = conn.recv(1024) # 对方和我说的话
# 有发必有收 收发必相等
print(msg)
conn.close() # 关闭连接
sk.close() # 关闭服务器套接字
#client端
import socket
sk = socket.socket() #创建了一个socket对象
sk.connect(('127.0.0.1',8898)) # 尝试连接服务器(打电话)
sk.send(b'hello!')
ret = sk.recv(1024) # 对话(发送/接收)
print(ret)
sk.close() # 关闭客户套接字
基于UDP协议的socket:udp是无链接的,启动服务之后必须先接受消息,不需要提前建立链接,接收和传递的时候都需要带上对方的地址。
#server端
import socket
import time
sk = socket.socket(type=socket.SOCK_DGRAM) #SOCK_DGRAM
sk.bind(('127.0.0.1',8080)) # while True:
# msg,adder = sk.recvfrom(1024)
# print(msg.decode('utf-8'))
# info = input('>>>').encode('utf-8')
# sk.sendto(info,adder) sk.close() #提供服务
#接收信息:时间的格式
#将我的时间转化为 接收到的格式
time_foramt,adder = sk.recvfrom(1024)
t_time = time.strftime(time_foramt.decode('utf-8'),time.localtime(time.time())) sk.sendto(t_time.encode('utf-8'),adder) sk.close() # 在udp协议中,服务端(server)不需要进行监听也不需要建立连接
#在启动服务端之后只能先 被动的等待客户端发送信息过来
# 客户端发送信息的同时还会自带地址信息
# 消息回复的时候,也就是传递信息的时候 ,不仅需要发送信息,还需要把自己的地址写上
#client端
import socket
sk =socket.socket(type=socket.SOCK_DGRAM)
ip_port = ('127.0.0.1',8080) # 地址 while True:
info = input('>>>')
if info == 'bye':
break
new_info = ('\033[34m来自二哥的消息:%s\033[0m'%info).encode('utf-8')
sk.sendto(new_info,ip_port)
ret,adder = sk.recvfrom(1024)
print(ret.decode('utf-8')) time_foramt = '%Y/%m/%d ; %H:%M:%S'
sk.sendto(time_foramt.encode('utf-8'),ip_port) new_time,adder = sk.recvfrom(1024)
print(new_time.decode('utf-8')) sk.close()
基于UDP的socket与基于TCP的socket的区别是:
基于UDP的socket中的服务端可以与很多的客户端同时进行发送消息,比如QQ,同时与多个人聊天
而基于TCP的socket中的服务端与客户端 建立了长连接,就一直站着这条线。
只有服务端与客户端断开了连接,下一个客户端才能与服务端建立连接。

黏包
同时执行多条命令之后,得到的结果很可能只有一部分,在执行其他命令的时候又接收到之前执行的另外一部分结果,这种显现就是黏包现象。
注意 : 只有TCP中有黏包现象,UDP永远也不
#server端
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8090))
sk.listen() conn,addr = sk.accept() #一种解决黏包的方法:
while True:
cmd = input('>>>')
if cmd =='q':
conn.send(b'q')
break
conn.send(cmd.encode('gbk')) num = conn.recv(10240).decode('utf-8')
conn.send(b'ok') ret = conn.recv(int(num)).decode('gbk')
print(ret)
#client端
import socket
import subprocess sk = socket.socket()
sk.connect(('127.0.0.1',8090)) #一种解决黏包的方法:
# while True:
# cmd = sk.recv(1024).decode('gbk')
# if cmd =='q':
# break
# ret = subprocess.Popen(cmd,shell=True,
stdout=subprocess.PIPE,stderr=subprocess.PIPE)
# # shell = True 就表示 直接执行操作系统的命名
# std_out = ret.stdout.read() #read() 只能读取一次
# std_err = ret.stderr.read()
# num = str(len(std_out) +len(std_err)).encode('utf-8')
# #ret.stdout.read() 是一个'gbk'的bytes类型
# # print(std_out)
# # print(std_err)
# sk.send(num)
# sk.recv(1024) #ok #防止send在一起,产生黏包
#
# sk.send(std_out)
# sk.send(std_err)
#
# sk.close()
黏包成因:
TCP协议有 1.面向流的通信特点(一条消息有多少字节对应用程序是不可见的,也就是不清楚信息的大小)和2.Nagle算法(将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。)
可靠黏包的tcp协议:是面向流的,tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到下次数据的接收时才会清除缓冲区内容。数据是可靠的,但是会粘包。
而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,因此用UDP协议发送时,用sendto函数最大能发送数据的长度为:65535- IP头(20) – UDP头(8)=65507字节。
用sendto函数发送数据时,如果发送数据长度大于该值,则函数会返回错误。(丢弃这个包,不进行发送)
所以UDP是以一个整体的消息发送过去, 多了就不会发送了。
而用TCP协议发送时,由于TCP是数据流协议,因此不存在包大小的限制(暂不考虑缓冲区的大小),这是指在用send函数时,数据长度参数不受限制。而实际上,所指定的这段数据并不一定会一次性发送出去,如果这段数据比较长,会被分段发送,如果比较短,可能会等待和下一次数据一起发送。
总结:

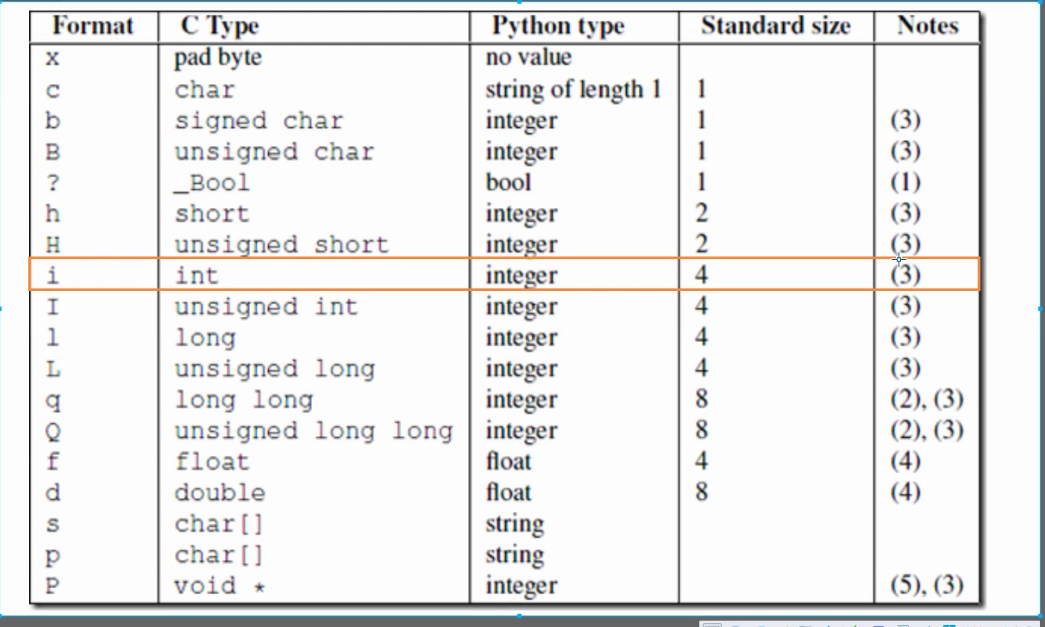
struct模块:
该模块可以把一个类型,如数字,转成固定长度的bytes,在这里我们主要用 Int类型 转成 4个字节多一点。
#server端
#用模块解决黏包的方法struct模块 import socket
import struct sk = socket.socket()
sk.bind(('127.0.0.1',8090))
sk.listen() conn,addr = sk.accept() while True:
cmd = input('>>>')
if cmd =='q':
conn.send(b'q')
break
conn.send(cmd.encode('gbk')) byte_num = conn.recv(4) # 4个字节 int 类型是'i'
int_num = struct.unpack('i',byte_num)[0] #获得一个元组(num,) ret = conn.recv(int_num).decode('gbk')
print(ret)
#client端
#用模块解决黏包的方法struct模块
import struct
import socket
import subprocess sk = socket.socket()
sk.connect(('127.0.0.1',8090)) while True:
cmd = sk.recv(1024).decode('gbk')
if cmd =='q':
break
ret = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
# shell = True 就表示 直接执行操作系统的命名
std_out = ret.stdout.read() #read() 只能读取一次
std_err = ret.stderr.read()
num = (len(std_out) +len(std_err))
byte_num = struct.pack('i',num) #byte_num 一定为4个字节 sk.send(byte_num) sk.send(std_out)
sk.send(std_err) # recv(1024) 每次最多的字节位4096,
# 用struct模块,大于4096后还是4个字节,只不过表现形式不相同
#
# ret =struct.pack('i',409600)
# print(ret,len(ret))
# #b'\x00@\x06\x00' 4 ,数字太大了就用其他的符号替换了一位,太大了就报错了

报头里面可以放一些文件名和文件的路径。
我们还可以把报头做成字典,字典里包含将要发送的真实数据的详细信息,然后json序列化,然后用struck将序列化后的数据长度打包成4个字节(4个自己足够用了)
简易版的上传和下载文件,以及报头的使用:
#接收请求
#server
import socket
import struct
import json
import os # Buffer = 4096
Buffer = 1024 sk = socket.socket()
ip_port = ('127.0.0.1',8090)
sk.bind(ip_port) sk.listen() conn,adder = sk.accept() byes_num = conn.recv(4)
num = struct.unpack('i',byes_num)[0] #返回的时候是一个元组 报头的大小 head = conn.recv(num).decode('utf-8') #字符串
dict_head = json.loads(head) #反序列化,为一个字典 operate = dict_head['operate']
if operate =='upload':
filesize = dict_head['filesize']
filename = dict_head['filename']
up_path = dict_head['up_path']
if up_path:
file_name = os.path.join(up_path,filename)
with open(file_name,'wb')as f:
while filesize:
print(filesize)
if filesize >= Buffer:
data =conn.recv(Buffer)
filesize -=Buffer
f.write(data)
else:
data = conn.recv(filesize)
f.write(data)
break conn.close()
sk.close()
else:
with open(filename, 'wb')as f:
while filesize:
print(filesize)
if filesize >= Buffer:
data = conn.recv(Buffer)
filesize -= Buffer
f.write(data)
else:
data = conn.recv(filesize)
f.write(data)
break conn.close()
sk.close() elif operate =='download':
filesize = dict_head['filesize']
file_path = dict_head['filepath'] with open(file_path, 'rb')as f:
while filesize:
print(filesize)
if filesize >= Buffer:
data = f.read(Buffer)
conn.send(data)
filesize -= Buffer else:
data = f.read(Buffer)
conn.send(data)
break conn.close()
sk.close()
#发送请求
#client
import socket
import os
import json
import struct
import time Buffer = 1024
# Buffer = 4096 sk =socket.socket()
ip_port = ('127.0.0.1',8090) sk.connect(ip_port) def file_name(path):
new_path = os.path.basename(path)
return new_path
#发送文件
#报头 def head(operate,up_path):
filename = file_name(filepath)
head = {'operate': operate,
'filepath': None,
'filename': None,
'filesize': None,
'up_path':up_path}
file_path = os.path.join(filepath) # 文件的路径
if os.path.isfile(file_path):
filesize = os.path.getsize(file_path) # 文件的大小也字节
head['filesize'] = filesize
head['filepath'] = filepath
head['filename'] = filename # 传输这个head(字典)就要序列化,把字典转换为字符串,字符串转换为bytes
json_head = json.dumps(head)
byte_head = json_head.encode('utf-8') # bytes类型的报头数据 # 先要传输报头的长度 byhead_len = len(byte_head)
byte_num = struct.pack('i', byhead_len) sk.send(byte_num)
sk.send(byte_head) return file_path,filesize
else:
print('文件不存在') print('欢迎来到上传下载系统')
n = input('01:上传;02:下载>>>>')
if n =='01':
#上传
filepath = input("请输入上传文件完整的路径>>")
up_path = input("请输入将上传文件放置的路径>> 0:代表当前的目录:>>>")
if up_path == '0':
file_path, filesize = head('upload',None)
with open(file_path, 'rb') as f:
print('开始上传文件')
time.sleep(1)
while filesize:
print(filesize)
if filesize >= Buffer:
connet = f.read(Buffer)
sk.send(connet)
filesize -= Buffer
else:
connet = f.read(filesize)
sk.send(connet)
print('上传文件成功')
break
sk.close() else:
file_path, filesize = head('upload',up_path)
with open(file_path, 'rb') as f:
print('开始上传文件')
while filesize:
print(filesize)
if filesize >= Buffer:
connet = f.read(Buffer)
sk.send(connet)
filesize -= Buffer
else:
connet = f.read(filesize)
sk.send(connet)
print('上传文件成功')
break sk.close() elif n =='02':
filepath = input("请输入下载文件完整的路径>>")
down_path = input("请输入将下载文件放置的路径>> 0:代表当前的目录:>>>")
filename = file_name(filepath)
head = {'operate':'download', #报头
'filepath': None,
'filename': None,
'filesize': None}
file_path = os.path.join(filepath) # 文件的路径
if os.path.isfile(file_path):
filesize = os.path.getsize(file_path) # 文件的大小也字节
head['filesize'] = filesize
head['filepath'] = filepath
head['filename'] = filename # 传输这个head(字典)就要序列化,把字典转换为字符串,字符串转换为bytes
json_head = json.dumps(head)
byte_head = json_head.encode('utf-8') # bytes类型的报头数据 # 先要传输报头的长度 byhead_len = len(byte_head)
byte_num = struct.pack('i', byhead_len) sk.send(byte_num)
sk.send(byte_head)
if down_path == '0':
with open(filename, 'wb')as f:
print('开始下载文件')
while filesize:
print(filesize)
if filesize >= Buffer:
data = sk.recv(Buffer)
filesize -= Buffer
f.write(data)
else:
data = sk.recv(filesize)
f.write(data)
print('下载文件成功')
break sk.close() else:
file_name = os.path.join(down_path,filename)
with open(file_name, 'wb')as f:
print('开始下载文件') while filesize:
print(filesize)
if filesize >= Buffer:
data = sk.recv(Buffer)
filesize -= Buffer
f.write(data)
else:
data = sk.recv(filesize)
f.write(data)
print('下载文件成功')
break
sk.close()
else:
print('输入错误,请重新输入')
验证客户端链接的合法性
用hmac模块来加密,跟hashlib模块一样。
#server
import socket
import os
import hmac #也是一种加密方式 和 hashlib 类似
secret_key = b'egg' # 密钥
sk = socket.socket()
sk.bind(('127.0.0.1',8080)) sk.listen() def check_coon(coon):
msg = os.urandom(32) # 随机获得32个字节
coon.send(msg)
h = hmac.new(secret_key,msg) #bytes密钥+字节 = 密文
s_h = h.digest() #获取密文
c_h = coon.recv(1024)
return hmac.compare_digest(c_h,s_h) #比较两者的密钥是否一样,返回pool值 coon,adder = sk.accept() ret = check_coon(coon) if ret:
print('合法的客户端') else:
print('不合法的客户端')
#client
import socket
import hmac
secret_key = b'egg' # 密钥 sk = socket.socket()
sk.connect(('127.0.0.1',8080)) msg = sk.recv(1024) #服务端放过开的字节
h = hmac.new(secret_key,msg)
c_h =h.digest()
sk.send(c_h) sk.close()
socketserver:(可以和多个客户端进行交互)
#server
import socketserver class MyServer(socketserver.BaseRequestHandler):
def handle(self):
while True:
ret = self.request.recv(1024) #self.request ---> conn
print(self.client_address) #self.client_address --->((127.0.0.1),端口) 地址
print(ret.decode('utf-8'))
info = input('>>>')
self.request.send(info.encode('utf-8')) if __name__ == '__main__':
server = socketserver.ThreadingTCPServer(('127.0.0.1',8080),MyServer) #内部的源码实际就是起服务,和监听
# Thread 线程
server.serve_forever() #有多个线程,永远的接收客户端,可以接收多个
#client
import socket
sk = socket.socket() sk.connect(('127.0.0.1',8080)) while True:
msg = input(">>>>")
sk.send(('来自一个人的消息:'+msg).encode('utf-8'))
ret = sk.recv(1024).decode('utf-8')
print(ret) sk.close()
并发编程
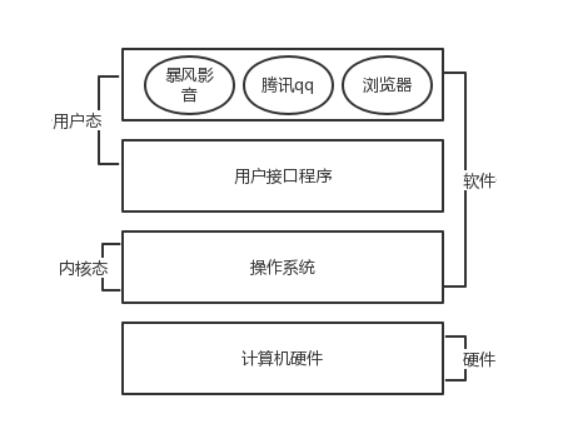
操作系统是 管理计算机 硬件 与软件 资源的计算机程序,同时也是计算机系统的内核与基石。
操作系统就是一个协调、管理和控制计算机硬件资源和软件资源的控制程序。操作系统所处的位置如图
操作系统的功能:
1.封装了对硬件的操作过程,给应用程序提供好用的接口。
2.对多个作业进行调度管理来分配硬件资源,将应用程序对硬件资源的竞态请求变得有序化。
进程
只有在运行当中的程序 —— 进程;进程 是 操作系统 中资源分配的最小单位
程序和进程的区别:
程序是指令和数据的有序集合,其本身没有任何运行的含义,是一个静态的概念。
而进程是程序在处理机上的一次执行过程,它是一个动态的概念。
程序可以作为一种软件资料长期存在,而进程是有一定生命期的。程序是永久的,进程是暂时的。
如果对同一个程序执行两次,就会在操作系统中出现两个进程,所以我们可以同时运行一个软件,分别做不同的事情也不会混乱。
进程的特性:
动态性:进程的实质是程序在多道程序系统中的一次执行过程,进程是动态产生,动态消亡的。
并发性:任何进程都可以同其他进程一起并发执行
独立性:进程是一个能独立运行的基本单位,同时也是系统分配资源和调度的独立单位;即每个进程之间是隔离的,为隔离资源.
异步性:由于进程间的相互制约,使进程具有执行的间断性,即进程按各自独立的、不可预知的速度向前推进
结构特征:进程由程序、数据和进程控制块三部分组成。
多个不同的进程可以包含相同的程序:一个程序在不同的数据集里就构成不同的进程,能得到不同的结果;但是执行过程中,程序不能发生改变。
只有操作系统才能调度进程;调度进程有以下几种算法:
# 先来先服务算法 FCFS
# 短作业优先算法
# 时间片轮转算法
# 多级反馈算法
进程的并发与并行;
并行:指两者同时运行,资源够的话,4核(4个CUP),即可以并行3个进程。
并发:并发是指资源有限的情况下,两者交替轮流使用资源,比如一段路(单核CPU资源)同时只能过一个人,A走一段后,让给B,B用完继续给A ,交替使用,目的是提高效率。
两者的区别:
并行是从微观上,也就是在一个精确的时间片刻,有不同的程序在执行,这就要求必须有多个处理器。
并发是从宏观上,在一个时间段上可以看出是同时执行的,比如一个服务器同时处理多个任务。
同步: 调度之后 ,还一定要等到结果后,才能往下执行。
异步:调度之后,不管结果,继续往下执行。
阻塞:等待请求,如果没有就一直等着,不能往下执行
i/o,值inout,output,输入和输出,是一个阻塞的,accpet,sleep,rev,等都是阻塞的。
非阻塞:不等待,继续往下执行
例子:比如你在银行排队办理业务。
同步阻塞:效率最低的,你只能在银行排队,等待什么事情都做不了。
异步阻塞 :相当于你领了一个号码,等待别人叫你,但是你只能在银行里面做别的事情,比如打电话。
同步非阻塞:在排队的时候,边打电话,边看轮到你没,这个程序需要在这两种不同的行为之间来回的切换,效率可想而知是低下的。
异步非阻塞:效率更高,在银行里得到一个号码,轮到你了,别人就去叫你,而你可以离开银行做别的事情。没有阻塞在等待上面。
很多人会把同步和阻塞混淆,是因为很多时候同步操作会以阻塞的形式表现出来,
同样的,很多人也会把异步和非阻塞混淆,因为异步操作一般都不会在真正的IO操作处被阻塞。
进程的创建与结束
创建进程有很多方式 —— 就是让一个程序运行起来
所有的进程都是被进程创建出来的
父进程 子进程
创建:
在UNIX中该系统调用是:fork,fork会创建一个与父进程一模一样的副本
,二者有相同的存储映像、同样的环境字符串和同样的打开文件(在shell解释器进程中,执行一个命令就会创建一个子进程)
在windows中该系统调用是:CreateProcess,CreateProcess既处理进程的创建,也负责把正确的程序装入新进程。
结束:
1. 正常退出(自愿,如用户点击交互式页面的叉号,或程序执行完毕调用发起系统调用正常退出,在linux中用exit,在windows中用ExitProcess)
2. 出错退出(自愿,python a.py中a.py不存在)
3. 严重错误(非自愿,执行非法指令,如引用不存在的内存,1/0等,可以捕捉异常,try...except...)
4. 被其他进程杀死(非自愿,如kill -9)
在python程序中的进程操作
python当中创建进程来替我做事情,就是通过multiprocess模块中的Process模块
Process为一个类,先实例化一个类,Process(参数)
参数介绍:1 group参数未使用,值始终为None
2 target表示调用对象,即子进程要执行的任务(函数)
3 args表示调用对象的位置参数元组,args=(1,2,'egon',);args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号。
4 kwargs表示调用对象的字典,kwargs={'name':'egon','age':18}
5 name为子进程的名称
在windows操作系统中使用Process需要注意:在Windows操作系统中由于没有fork(linux操作系统中创建进程的机制),在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件。因此如果将process()直接写在文件中就会无限递归创建子进程报错。所以必须把创建子进程的部分使用if __name__ ==‘__main__’ 判断保护起来,import 的时候 ,就不会递归运行了。
使用Process模块创建进程的二种方法:
#第一种实现进程的方法;Process实例化
# from multiprocessing import Process
# import os
# import time
# a= 10
# def func(k):
# print('子进程:%s'%k,os.getpid()) #每次执行子进程时 都会把模块里面的方法以及变量全部执行一遍,
# # 已经把a=10,放入子进程里面的空间了
# # print('父进程:', os.getppid())
# # global a
# n = a-1
# print(n)
#在创建子进程的时候会自动 import 启动它的这个文件,而在 import 的时候又执行了整个文件,所以用if __name__ == '__main__'来控制。
# if __name__ == '__main__':
# p_list = []
# for i in range(5):
# p = Process(target=func,args=(i,)) #实例化一个进程的对象 #args = 进程的参数, 必须就一个元组(没有顺序)
# # print('456789',os.getpid()) #获得当前的进程PID
# p.start() #直到执行了start后才开启了一个func()进程,
# p_list.append(p) # 也就是告诉操作系统我要创建一个进程(不关心是否创建了进程),然后就往下执行了。
# # time.sleep(5)
# for p in p_list:
# p.join() # 阻塞 等待子进程的结束 , 这样就又变成了同步了
# # a = 10 #进程之间的数据是隔离的,子进程拿不到这个a
# print('789456', os.getpid())
# # time.sleep(5)
# 就实现了异步(不等待继续往下运行) #第二种实行子进程的方法。通过来类,这个类一定要继承Process,并且要有run方法来执行。
#
# import os
# from multiprocessing import Process
#
# class MyProcess(Process):
# def __init__(self,name):
# # Process.__init__(self)
# super().__init__() #创建类的__init__,同时必须还要调用父类的__init__
# self.name = name
#
# def run(self):
# print('子进程:',os.getpid())
# self.func() # --->在子进程中调用
# # print(self.name)
#
# def func(self):
# print('子进程:',os.getpid())
#
#
# if __name__ == '__main__':
# p = MyProcess('alex') #添加参数的时间,往__init__函数添加
# p.start() #start会自动调用run
# p.join() # 阻塞 等待子进程的结束
# #p.func() # ---> 在主进程中调用 PID为主进程
# print('主进程:',os.getpid())
守护进程
# 在正常的进程中,子进程不会随着主进程的代码的结束而结束,并且主进程的结束要等子进程的结束
# 守护进程的作用: 子进程会随着主进程的代码的结束而结束。
#p.daemon = True ,一定要在开启进程之间,即 p.start()之前开启守护进程。 #在守护进程中, 子进程不能再开启一个子进程,开启了就不会执行子进程了
# import time
# from multiprocessing import Process
#
#
# def func():
# time.sleep(1)
# print('----'*10)
# time.sleep(15) #15s
# print('----' * 10)
#
#
# def cal_time():
# # p = Process(target=func) #子进程不能再开启一个子进程
# # p.start()
# while True:
# time.sleep(1)
# print('过去了1秒')
#
#
#
# if __name__ == '__main__':
# p = Process(target=cal_time)
# p.daemon =True #开启 守护进程
#
# p.start()
#
# p1 = Process(target=func)
# p1.start()
# for i in range(100):
# time.sleep(0.1) #10s
# print('*'*i)
#
# p1.join() # 使p的子进程不再随主进程的结束而结束了,等到p1的子进程结束而结束。
#进程中的方法:
#p.start();p.join()(同步的) ; p.is_alive() ---> 判断一个进程是否存在,若存在则返回True;不存在则返回False;
# p.terminate() ---> 结束一个进程,则是让操作系统结束进程,即不会马上就结束,所以说是一个异步的; #进程中的属性:
#p.pid --->查看进程的ID
#p.name --->查看进程的名字
#在主进程,直接调用,如果要在子进程中查看,需要创建类,通过self.pid;self.name来查看;
# import time
from multiprocessing import Process # def cal_time():
# print('6666')
# # time.sleep(6)
# # print('过去了5秒')
#
# if __name__ == '__main__':
# p = Process(target=cal_time)
# # p.daemon =True #开启 守护进程
# p.start() #异步的, 告诉操作系统我要创建一个子进程 # print(p.is_alive())
# time.sleep(1) #自己的理解 : # 迅速的关闭一个进程,导致子进程还没有创建,就在关闭了PyCharm上的所创建的子进程
# # 但是内存中这个进程还没有关闭,要等操作系统来关闭
# p.terminate() #在子进程的代码没有执行完的时间内 是 异步的 ,告诉操作系统结束进程,即不会马上就结束;
# # 但是只要子进程的代码结束完后,p.terminate() 就会立即结束进程。
# time.sleep(1)
# print(p.is_alive()) # print(p.pid,p.name) #6588 Process-1(操作系统起的)
# p.name= 'alex'
# print(p.pid, p.name) #5744 alex #如果要在子进程中查看,需要创建类,通过self.pid;self.name来查看; # class MyProcess(Process):
# def run(self):
# print('66666',self.name,self.pid)
#
#
#
# if __name__ == '__main__':
# p = MyProcess()
# p.start()
# p.name
# p.pid
#66666 MyProcess-1 7064 # from multiprocessing import Process
#
# def func(num):
# print(num)
#
#
# if __name__ =='__main__':
# for i in range(10):
# p = Process(target=func,args=(i,))
# p.start()
# # p.join() #有序的
锁
加锁可以保证多个进程修改同一块数据时,同一时间只能有一个任务可以进行修改,
即串行的修改,没错,速度是慢了,但牺牲了速度却保证了数据安全。
#加锁,,并且只有一把钥匙,所以在拿钥匙,以及还钥匙的过程中只能有一个进程;好处,使数据安全 #模拟抢票
# import time
# import random
# import json
# from multiprocessing import Lock
# from multiprocessing import Process
# #
# def search(i):
# with open('ticket') as f :
# ret = json.load(f)['count']
# print('%s查看票数'%i,ret)
#
# def get(i):
# with open('ticket','r') as f:
# ret = json.load(f)['count'] #查看剩余的票数
# time.sleep(random.random()) #网络的延迟
# if ret > 0 :
# with open('ticket', 'w') as f:
# dic = {'count':ret-1}
# json.dump(dic,f)
# print('%s买到票了'%i)
# else:
# print('%s没有买到票'%i)
#
# def task(i,lock):
# search(i) #查看票数
# lock.acquire() #获得钥匙
# get(i) #抢票
# lock.release() #只有释放钥匙后,后面的人才能拿到钥匙,执行抢票。
#
#
# if __name__ == '__main__':
# lock = Lock() #实例化一个锁
# for i in range(10):
# p = Process(target=task,args=(i,lock))
# p.start()
信号量 本质是也是 锁,只不过钥匙可能会有多把
#信号量(Semaphore),本质上是可控制钥匙的个数的锁,在锁里面加了一个计算器,用来计算钥匙的数量。拿一个减一,还一个加一
#例子,KTV里面只能有4个人同时在里面唱歌,现在有10个在外面等着进入。 # import time
# import random
# from multiprocessing import Semaphore
# from multiprocessing import Process
#
#
# def song(i,sem):
# sem.acquire() #需要锁 ,阻塞
# print('%s,进入ktv'%i)
# time.sleep(random.randint(1,10))
# print('%s,离开ktv'%i)
# sem.release() #释放锁
#
# if __name__ == '__main__':
# sem = Semaphore(4) #有4把钥匙,控制钥匙的
# for i in range(10):
# Process(target=song,args=(i,sem)).start()
#事件 #异步阻塞
#事件 标志 同时是所有的进程 都阻塞,或是是非阻塞 # from multiprocessing import Event
# e = Event() #实例化一个事件 #把事件看作为一个交通信号灯
# e.set() #把阻塞变为非阻塞;即把红灯变为绿灯。
# e.wait() #刚实例化出来的一个事件对象,默认的信号是阻塞信号,相当在等红绿灯,一开的灯默认为红灯
# #阻塞的信号,wait就等,如果是非阻塞信号的话,wait就不等。
# e.clear() #把非阻塞变为阻塞;即把绿灯变为红灯
#
# print(e.is_set()) #判断刚实例化出来的对象是否是阻塞的,True为非阻塞;False为阻塞;
#例子
#模拟 红绿灯的事件。
#20辆车要通过红绿灯,每6秒 变换一次; from multiprocessing import Event
from multiprocessing import Process
import random
import time def trafficc_light(e):
while True:
if e.is_set(): #绿灯
time.sleep(6)
print('红灯亮了')
print('车辆等待中')
e.clear()
else:
time.sleep(6)
print('绿灯亮了')
e.set() def car_go(i,e):
e.wait() #等红绿灯。
print('%s 车通过了'%i) if __name__ == '__main__':
e = Event() #事件可以控制所有子进程同时阻塞与非阻塞。
light = Process(target=trafficc_light,args=(e,))
# light.daemon = True
light.start()
for i in range(20):
if i % 6:
time.sleep(2)
car = Process(target=car_go,args=(i,e))
car.start()
锁,信号量,事件 都是在 进程与进程 之间 共享的。
虽然可以用文件共享数据实现进程间通信,但问题是:
1.效率低(共享数据基于文件,而文件是硬盘上的数据)
2.需要自己加锁处理 #因此我们最好找寻一种解决方案能够兼顾:1、效率高(多个进程共享一块内存的数据)2、帮我们处理好锁问题。
这就是mutiprocessing模块为我们提供的基于消息的IPC通信机制:队列和管道。 队列(Queue)可以实现进程之间的信息通信,主进程与子进程,子进程与子进程;
#队列,原则是先进先出,Put放,get取; 可以实现进程之间的信息通信,主进程与子进程,子进程与子进程;
#只能是multiprocessing中的Queue
# from multiprocessing import Queue
# from multiprocessing import Process
#
#
# def data_get(q):
# for i in range(10):
# print(q.get())
#
#
# def data_put(q):
# for i in range(10):
# q.put(i)
#
# if __name__ == '__main__':
# q =Queue(5) #限制一个队列中同时只能有5个数据,取走一个就在存入一个。
# p = Process(target=data_get,args=(q,))
# p.start()
# p1 = Process(target=data_put,args=(q,))
# p1.start() #模型,生产者与消费者模型。
#生产包子,吃包子; from multiprocessing import Queue
from multiprocessing import Process
import time def eat(q):
for i in range(10):
time.sleep(1)
print('吃了%s个包子'%q.get()) def create(q):
for i in range(20):
q.put(i) if __name__ == '__main__':
q =Queue(5) #限制一个队列中同时只能有5个数据,取走一个就在存入一个。
p = Process(target=create,args=(q,))
p.start()
p1 = Process(target=eat,args=(q,))
p1.start()
p2 = Process(target=eat, args=(q,))
p2.start() #首先,对于内存空间来说,每次只有很少的数据会在内存中,Queue(5)来限制内存中的数据;
#对于生产与消费之间的不平衡来说:
#增加消费者或者是生产者来调节效率
进阶的生产者和消费者的模型,这里用到JoinableQueue模块
# from multiprocessing import JoinableQueue
#
# q = JoinableQueue()
# q.task_done() #用来检测消费者是否把生产的数据消费完,
# q.join() #把消费者的信息反馈生产者的信息
#进阶的生产者和消费者的模型,
# 消费者把生产者所生产的数据给消费完了 ————> 生产者的代码执行结束 ————> 主进程的代码执行结束 ————>守护进程的消费者代码执行结束 #用到JoinableQueue里面的task_done方面来检测消费者是否已经把生产者所生产的数据给消费完了,消费完了以后,生产者里面的join着会得到
#消息,结束生产者的代码,然后主进程代码结束了,守护进程的消费者也结束了,这样就不用关心消费者要处理多少数据.
#队列 里面 自带 有 锁,即数据是安全的。即不会一个数据被多个人拿到,只会被一个人拿到。 from multiprocessing import JoinableQueue
from multiprocessing import Queue
from multiprocessing import Process
import time
import random def consumer(q,name):
while True:
food = q.get()
# if food == None:break
print('%s吃了%s'%(name,food))
q.task_done() def producer(q,food):
for i in range(5):
q.put('%s-%s'%(food,i))
print('生产了%s'%food)
time.sleep(random.randint(1, 3))
#生产完成以后发一个数据表示生产结束了,从而使消费者接收到后接收
# q.put(None) #这种比较LOW
# # q.put(None) #????为什么put2个None,程序就结束了,正常应该是只有2个人接收到None,还有一个人没有接收到信息
q.join() if __name__ == '__main__':
q =JoinableQueue()
# q=Queue()
p = Process(target=producer,args=(q,'苹果'))
p.start()
p0 = Process(target=producer,args=(q,'香蕉'))
p0.start()
p1 = Process(target=consumer,args=(q,'zlex'))
p1.daemon = True
p1.start()
p2 = Process(target=consumer, args=(q,'eggon'))
p2.daemon = True
p2.start()
# p2 = Process(target=consumer, args=(q, 'eggon0'))
# p2.start()
# #
p.join()
p0.join()
进程间通信---IPC
IPC---队列;管道---IPC;Pipe。
管道,是一个双向通信的,管道中的有send,recv方法;进程与进程之间的管道,关闭一端不影响,不用的一端要及时关闭,通过EOFError异常来关闭管道的通信;from multiprocessing import Procesfrom multiprocessing import Pipe
from multiprocessing import Pipe
from multiprocessing import Process def func(p):
p_foo, p_son = p
p_foo.close()
while True:
try:
print(p_son.recv())
except EOFError: #只有发送端全部关闭后,当管道里面没有数据的时候就会报错;
p_son.close()
break #发送端不关闭,则会阻塞,一直等待发送端发送数据。 if __name__ == '__main__':
p_foo,p_son = Pipe()
p = Process(target=func,args=((p_foo,p_son),))
p.start()
p_son.close() #不会影响子进程里面的p_son
p_foo.send('heoll')
p_foo.send('heoll_0')
p_foo.send('heoll_1')
p_foo.close()
管道:
双向通信;数据不安全,没有锁的机制,
因此基于 管道和锁,实现了队列;
队列 = 管道 + 锁
队列 是用在同一台机器上的多个进程之间的通信,数据是安全的。
进程间数据是独立的,可以借助于队列或管道实现通信,二者都是基于消息传递的
虽然进程间数据独立,但可以通过Manager实现数据共享。
#Manager 支持的进程与进程之间数据分享类型有:list;dic等python中的所有的数据类型;pipe;
#但是并不提供对数据的安全性
from multiprocessing import Manager,Process,Lock
def work(d,lock):
lock.acquire() #不加锁而操作共享的数据,肯定会出现数据错乱
# d['count']-=1
d[0] +=1
lock.release()
if __name__ == '__main__':
lock=Lock()
m =Manager()
# dic=m.list({'count':100}) #创建的字典在进程之间共享。
li = m.list([i for i in range(10)])
p_l=[]
for i in range(20):
p=Process(target=work,args=(li,lock))
p_l.append(p)
p.start()
for p in p_l:
p.join()
print(li)
但进程间应该尽量避免通信,即便需要通信,也应该选择进程安全的工具来避免加锁带来的问题。
以后我们会尝试使用数据库来解决现在进程之间的数据共享问题。
进程池:
定义一个池子,池子里面有固定数量的进程,同时工作;
比如要执行100个任务,池子里面有5个进程,就用5个进程来循环完成100个任务,
就不需要按照原来 创建100个进程来完成任务,用进程池大大提高了效率;池中进程的数量是固定的,那么在同一时间最多有固定数量的进程在运行。
进程池中的3个方法:map;apply—同步的;apply_aync——异步的。
进程池为什么出现 :开过多的进程 1.开启进程浪费时间 2. 操作系统调度太多的进程也会影响效率
开进程池 : 有几个现成的进程在池子里,有任务来了,就用这个池子中的进程去处理任务,
任务处理完之后,再把进程放回池子里,池子中的进程就能去处理其他任务了。
当所有的任务都处理完了,进程池关闭,回收所有的进程
import os
import time
from multiprocessing import Pool
from multiprocessing import Process
# Pool() 实例化一个进程池,里面的参数是核数+1(cup+1)
import os
# print(os.cpu_count())
# p.map(func,range(100)) #p.map(func-函数名,iterable-可迭代的对象), #在windows操作系统会按照顺序来调用,看这像是同步的;
#但是在mac中不是同步的
# p.apply(func,args=(i,)) 同步提交任务的机制
#ret = p.apply_async(func,args=(i,)),apply_async 是异步提交任务的机制,可以接收func的返回对象,返回的对象需要用get方法获取返回值。 #使用get来获取apply_aync的结果,如果是apply,则没有get方法,
# 因为apply是同步执行,立刻获取结果,也根本无需get def func(i):
i+=1
# return i
print(i,os.getpid())
# time.sleep(random.randint(1,3))
if __name__ == '__main__':
ret_l = []
p = Pool(5) #用进程池大大提高了效率
# for i in range(20):
# ret = p.apply_async(func,args=(i,))
# ret_l.append(ret)
# p.apply(func,args=(i,))
p.map(func,range(20))
p.close() #不允许再向进程池中添加任务。
p.join()
print('6666')
# for i in ret_l:
# print(i.get())
# print('6666') #在windows操作系统会按照顺序来调用。
#
# p_list = []
# start0_time = time.time()
# for i in range(20): #创建100个进程来完成任务
# p = Process(target=func,args=(i,))
# p.start()
# p_list.append(p)
#
# [i.join()for i in p_list]
# print(time.time() - start0_time)
回调函数:
把多进程中的函数的返回值返回给回调函数; 回调函数不能在传入参数了,回调函数在主程序中运行。
#回调函数
# from multiprocessing import Pool
# import os
#
# def call(arg): #回调函数不能在传入参数了,回调函数在主程序中运行
# print(arg,os.getpid())
#
# def func(i):
# i+=1
# # print('子程序',os.getpid())
# return i #返回给回调函数
#
#
# if __name__ == '__main__':
# p = Pool(4)
# for i in range(20):
# p.apply_async(func,args=(i,),callback=call) #把多进程中的函数的返回值返回给回调函数
# #用这个 p.apply_async(func)的时候因为 与主进程是异步的; 就先要p.close() ; p.join(),等到子进程结束后才能结束主程序;
#不然主程序就结束后,可能子进程还没有执行完;
# p.close()
# p.join()
# print(os.getpid())
回调函数多用于爬虫,返回的网页给主程序进程分析
# 例子
# 请求网页
# 网络延时 IO操作
# 单进程
# 10个页面 同时访问多个 —> 多进程
# 分析页面:长短 ——>回调函数
# from multiprocessing import Pool
# from urllib.request import urlopen
# import requests
#
# def del_url(arg):
# # print(arg['url'],arg['accpet'],len(arg['ret']))
# with open('url.txt','a')as f :
# f.write('url:'+arg['url']+',')
# f.write('status_code:' + str(arg['accpet'])+',')
# f.write('url_long:' + str(len(arg['ret']))+'\n')
# def get_url(url):
# ret = urlopen(url).read().decode('utf-8')
# accpet = requests.get(url).status_code
#
# dic = {'url':url,'ret':ret,'accpet':accpet}
#
# return dic
#
# if __name__ == '__main__':
# p = Pool(5)
#
# urls = ['https://www.hao123.com',
# 'https://www.baidu.com/',
# 'https://www.sina.com.cn/',
# 'http://www.google.cn/',
# 'https://www.80s.tw/'
# ]
#
#
# for url in urls:
# p.apply_async(get_url,args=(url,),callback=del_url) #不能传入一个可迭代的对象
#
# p.close()
# p.join() 回调函数在爬虫的应用
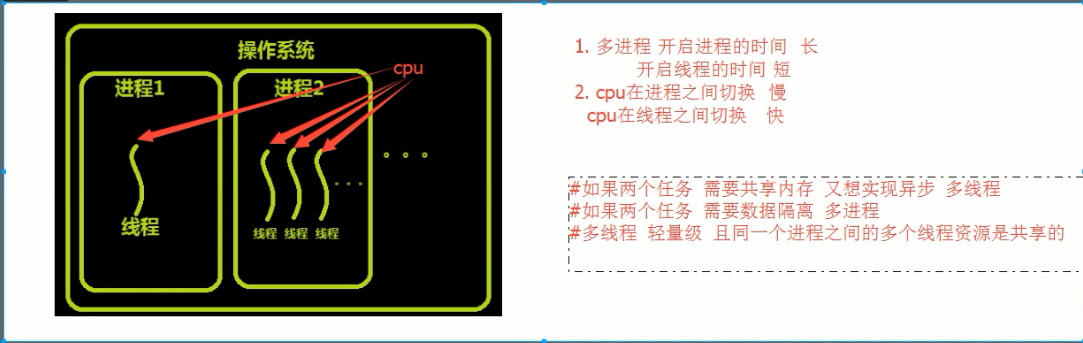
线程
进程: 执行中的程序
线程: 轻量级的进程
进程只管存放数据,就相当于独立的内存;而线程则是使用进程中的数据;
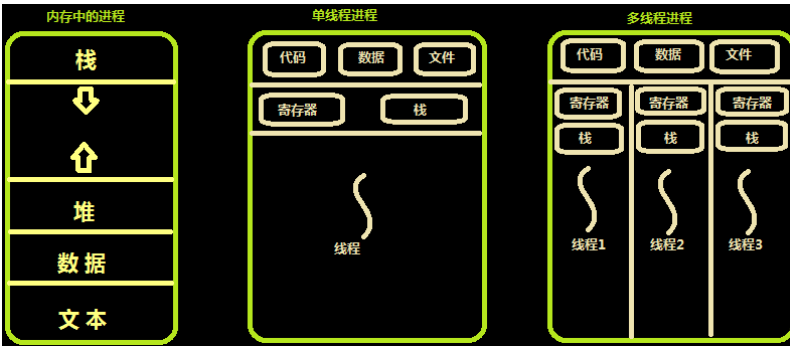
在上图中其实在同一个进程中的 多个线程 之间有属于他们各自的数据存放的空间;
线程的特点:
1.轻型实体
2.独立调度和分派的基本单元;
3.共享进程中的资源
4.可并行执行:就是用多个cup同时执行多个线程,这个目前没有解决;主要是因为GIL(全局解释器锁),在Cpython解释器中的;主要是为了保障数据的安全,就是在同一时间下只能执行一个线程;
因此该问题主要是Cpython解释器的问题,而不是Python本身这门语言的问题。
一个程序中能同时有多进程和多线程;
线程启动,用threading 模块里面的 Thread ,和启线程的multiprocessing 方法一样。
因为 线程在是进程中执行的,所以不用if __name__ == '__main__' 来控制了
类里面的静态属性,只有多个 子线程 共享,而多个子 进程 不共享,因为进程之间是资源独立的
#第一种开启线程的方法 实例化Thread
# import time
# from threading import Thread
# import os
# def fuc():
# time.sleep(1)
# print('heoll',os.getpid())
#
#
#
# t = Thread(target=fuc)
# t.start()
# t = Thread(target=fuc)
# t.start()
#
# print('123',os.getpid()) #线程的调度快,并且在 同一 进程中的 线程 与 线程之间是异步的 #第二种开启线程的方法,为 创建一个类,类继承Thread,并且有run 方法
# import time
# from threading import Thread
# class MyThread(Thread):
# n=0 #静态属性 ; 类里面的静态属性,只有多个 子线程 共享,而多个子 进程 不共享
# def __init__(self,age,name):
# self.age = age
# Thread.__init__(self) #在父类中有name变量了
# self.name = name
# def run(self):
# MyThread.n +=1
# time.sleep(1) #更好的看出异步
# print(self.age,'666',self.name)
#
#
# for i in range(10):
# my_t = MyThread('alex','eggn')
# my_t.start()
#
#
# print(MyThread.n)
threading.currentThread() :返回当前的线程变量;这个对象中 同样也能和类一样拿到线程名和其他的属性
threading.currentThread().name(得到线程的名字);threading.currentThread().ident(得到线程的ID);
threading.activeCount()(返回正在运行着的线程 列表);threading.enumerate() (返回正在运行着的线程 个数)
import threading
import time def func(i):
time.sleep(0.5)
print(i,threading.currentThread().name,threading.currentThread().ident)
#通过 threading.currentThread() 这个对象下面的ident属性 得到 线程的ID for i in range(20):
t = threading.Thread(target=func,args=(i,))
t.start() print(threading.enumerate()) # 返回正在运行着的线程 列表
print(threading.activeCount()) # 返回正在运行着的线程的 个数
#返回了21个线程,是因为在一个进程中至少有一个线程,即主线程,因此 在运行着的线程的个数 = 主线程 + 自己创建的子进程的个数
#面试可能会提到 # 21 = 1 + 20
守护线程:
无论 是守护进程 还是守护线程 ,都是 遵循 当主进程 或者是 主线程 的代码执行结束后,守护进程和守护线程的代码就结束了;
主线程 的代码执行结束 是指 主线程 所在的进程 内所有非守护线程 统统运行完毕,主线程才算运行完毕。
进程设置守护进程 是一个属性 daemon = True; 线程中守护进程是一个带参数的函数——setDaemon(True)
import time
from threading import Thread
def func():
print('开始执行子线程')
time.sleep(3)
print('子线程执行完毕') def func2():
print('开始执行子线程2')
time.sleep(3)
print('子线程执行完毕2') t = Thread(target=func)
t.setDaemon(True) # 进程设置守护进程 是一个属性 daemon = True;线程中守护进程是一个带参数的函数
t.start()
t2 = Thread(target=func2)
t2.start()
#t2.join() # 等待t2结束
#有join和没有join的两种理解:
# 守护线程 守护进程 都是等待主进程或者主线程中的代码 执行完毕
# t2 = Thread(target=func)
# t2.start() ---> 主线程代码执行完毕
# 守护线程就结束了
# 主线程这个程序 还没结束 等待t2继续执行
# t2执行完毕 主线程结束 # t2 = Thread(target=func)
# t2.start()
# t2.join() # 等待t2结束 执行完这句话代码才执行完毕
# t2线程执行完毕
# 主线程中没有代码了,守护线程结束
锁
GIL (全局解释器锁)不是锁数据 而是锁线程;保证同一时间CUP只能调度一个线程;
在多线程中 特殊情况 仍然要加锁 保证数据的安全
#科学家吃面的模型,充分的解释了这 在多线程中 特殊情况 下数据有可能不安全
import time
from multiprocessing import RLock,Lock
from threading import Thread
# noddels = kz = RLock()
noddels = Lock()
kz = Lock() def eat(name):
noddels.acquire()
print('%s拿到面了'%name)
time.sleep(1)
kz.acquire()
print('%s拿到筷子了' % name)
print('%s吃面' % name)
kz.release()
noddels.release() def eat2(name):
kz.acquire()
print('%s拿到筷子了' % name) #time.sleep(2) #类型有许多的代码
noddels.acquire()
print('%s拿到面了' % name)
print('%s吃面' % name)
noddels.release()
kz.release() t = Thread(target=eat,args=('alex',)).start()
t1 = Thread(target=eat,args=('xinin',)).start()
t2 = Thread(target=eat2,args=('eggon',)).start()
t3 = Thread(target=eat2,args=('jin',)).start() #alex拿到面了
#eggon拿到筷子了 这样的结果 就成为死锁了。
#因此在这里用递归锁 来解决这个问题。 用递归锁就相当于一把钥匙,去执行。
# 同步锁在多线程并发的情况下,同一个线程中 如果出现多次acquire 就可能产生死锁线程现象
# 用递归锁就能避免
递归锁(RLock): 可以多次的递(acquire)和归(release) ;
上面的模型为科学家吃面,有3个人,必须同时有筷子和面才能吃,为了安全,都加上了锁,才才能保证一个人吃,但是用同步锁,有问题,有可能会造成死锁的现象。
线程 中的事件:
#线程 中的 事件;
#跟进程中的事件是一样的 # from threading import Event
# e = Event() #事件里面有一个flag 默认 为 False 即阻塞
# e.set() #False ---- True ,阻塞---非阻塞
# e.clear() #True ---- False, 非阻塞 --- 阻塞
# e.is_set() #判断此时的flag为什么,T--非阻塞,F---阻塞
# 一个数据库连接的例子
# import time
# import random
# from threading import Thread
#
#
# def conn_mysql():
# count = 1
# while not e.is_set():
# if count >3:
# raise TimeoutError
# print('尝试这第%d次连接'%count)
# count +=1
# e.wait(0.5) #从以前的一直等待,变成了只会等待0.3s, 不管是否能通过
#
# print('连接成功')
#
#
# #检查数据库是否连接
# def check_mysql(): #模拟一个连接检测的时间
# time.sleep(random.randint(1,3))
# e.set() #可以与数据库连接 #线程共用进程里面的资源
#
#
# e = Event()
# Thread(target=check_mysql).start()
# Thread(target=conn_mysql).start()
线程队列:
直接 import queue 导入就行;队列是 先进 先出, 数据是安全的。
import queue
# q = queue.Queue() # 队列 线程安全的
# q.get()
# q.put()
# q.qsize()
LifoQueue() 后进后出的
lfq = queue.LifoQueue() # 后进先出 :栈
lfq.put(1)
lfq.put(2)
lfq.put(3)
lfq.put(4)
print(lfq.get())
print(lfq.get())
print(lfq.get())
print(lfq.get())
PriorityQueue() 按照优先级,值越小越优先,如果优先级的值相同就按照asc码小的先出。
import queue
pq = queue.PriorityQueue() # 值越小越优先,值相同就asc码小的先出
pq.put((1,'c'))
pq.put((1,'b'))
pq.put((15,'c'))
pq.put((2,'d'))
#
print(pq.get())
print(pq.get()) #(1, 'b')
#(1, 'c')
线程中的 定时器的使用:
from threading import Timer
import time
def hello():
while True:
time.sleep()
print("hello, world")
while True: # 每隔一段时间要开启一个线程
t = Timer(10, hello) # 定时开启一个线程,执行一个任务
# 定时 : 多久之后 单位是s
# 要执行的任务 :函数名
t.start()
# While的位置 是由 sleep的时间 放置的:
# sleep的时间短 就在线程内while True ; 相当于在一个线程内
# sleep的时间长 就在主线程while True ; 相当于创建线程
条件(condition)
import threading
def run(n):
con.acquire()
con.wait() # 等着 传递信号
print("run the thread: %s" % n)
con.release() if __name__ == '__main__':
con = threading.Condition() # 条件 = 锁 + wait的功能
for i in range(10):
t = threading.Thread(target=run, args=(i,))
t.start() while True:
inp = input('>>>')
if inp == 'q':
break
con.acquire() # condition中的锁 是 递归锁
# con.notify(int(inp)) # 在 传递信号 前后必须加锁和释放锁。
if inp == 'all':
con.notify_all()
else:
con.notify(int(inp)) # 传递信号 notify(1) --> 可以放行一个线程
con.release()
线程池:
from concurrent import futures 是一个新的模块
futures.ThreadPoolExecutor() #线程池
futures.ProcessPoolExecutor() #进程池 ; 两者的用法一样;
这样 统一了入口和方法 简化了操作 降低了学习的时间成本
import time
import random
from concurrent import futures
def funcname(n):
print(n)
time.sleep(random.randint(1,3))
return n*'*'
def call(args):
print(args.result())
thread_pool = futures.ThreadPoolExecutor(5)
# thread_pool.map(funcname,range(10)) # 是一个生成器
# map,天生异步,接收可迭代对象的数据,不支持返回值
f_lst = []
for i in range(10):
f = thread_pool.submit(funcname,i) # submit 合并了创建线程对象和start的功能 。
f_lst.append(f)
thread_pool.shutdown() # shutdown 有 close() join()这2个的功能。
for f in f_lst: # 一定是按照顺序出结果
print(f.result()) #f.result()才能等到结果;阻塞 等f执行完得到结果 # 回调函数 add_done_callback(回调函数的名字)
thread_pool.submit(funcname, 1).add_done_callback(call)
线程池实现的简单的网页的爬虫:
from concurrent import futures # 新的模块, 导入 线程池 和 进程池
import requests def get_url(url):
data = requests.get(url)
return {'url':url,'conten_long':len(data.text),'status_code':data.status_code}
def call_deal(arg):
print(arg.result()) #要result()才能获得值; urls = [ 'https://www.hao123.com',
'https://www.baidu.com/',
'https://www.sina.com.cn/',
'http://www.google.cn/',
'https://www.80s.tw/' ] thread_pool = futures.ThreadPoolExecutor(5) #实例化一个线程池
f_list = [] for url in urls:
f=thread_pool.submit(get_url,url)#.add_done_callback(call_deal) #对象.submit ----有创建进程和开始进程的功能。
f_list.append(f) for f in f_list:
print(f.result()) thread_pool.shutdown() #close()和jion() 这个2个功能的结合 # for i in thread_pool.map(get_url,urls): #thread_pool.map(get_url,urls)是一个生成器
# print(i)
协程介绍
协程:是单线程下的并发,又称为微线程;协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
需要强调的是:
#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行)
#2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
对比操作系统控制线程的切换,用户在单线程内控制协程的切换
优点如下:
#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
#2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点如下:
#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
#2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
总结协程特点:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 附加:一个协程遇到IO操作自动切换到其它协程,但是不能规避掉IO的时间(如何实现检测IO,yield、greenlet(实现自动切换)都无法实现,就用到了gevent模块(select机制))
import time
from greenlet import greenlet # 在单线程中切换状态的模块
def eat1():
print('吃鸡腿1')
g2.switch()
time.sleep(5)
print('吃鸡翅2')
g2.switch() def eat2():
print('吃饺子1')
g1.switch() #切换协程1
time.sleep(3)
print('白切鸡') g1 = greenlet(eat1)
g2 = greenlet(eat2)
g2.switch() #切换到那个协程去执行,然后g2执行完后就结束了
# gevent内部封装了greenlet模块
Greenlet模块
from gevent import monkey
monkey.patch_all()
#就是把下面的所有的模块 都可以 让gevent可以识别的io阻塞
import time # time socket urllib requests
import gevent # greenlet gevent在切换程序的基础上又实现了规避IO
from threading import current_thread
def func1():
print(current_thread().name)
print(123)
time.sleep(1) #time.sleep 就可以让gevent识别的io阻塞;切换来规避IO
print(456) def func2():
print(current_thread().name) # dummythread 虚设的线程 即假线程;
print('hahaha')
time.sleep(1) #切换来规避IO
print('10jq') g1 = gevent.spawn(func1) # 遇见他认识的io会自动切换的模块
g2 = gevent.spawn(func2)
# g1.join()
# g2.join()
gevent.joinall([g1,g2])
import gevent def func1():
print('123')
gevent.sleep(3) #切换1秒
print('hahaha') def func2():
print('123456789')
gevent.sleep(2)
print('7777') g1 = gevent.spawn(func1) # 遇到 他认识的 i/o 会自动的切换模块,并且延时过后,回到原来的位置。
g2 = gevent.spawn(func2)
g1.join() #g1的函数执行结束后就结束了
Gevent之同步与异步
from gevent import spawn, joinall, monkey; monkey.patch_all() import time def task(pid):
time.sleep(0.5)
print('Task %s done' % pid) def synchronous(): # 同步
for i in range(10):
task(i) def asynchronous(): # 异步
g_l = [spawn(task, i) for i in range(10)]
joinall(g_l)
print('DONE') if __name__ == '__main__':
print('Synchronous:')
synchronous()
print('Asynchronous:')
asynchronous()
协程的应用:
爬虫
from gevent import monkey;monkey.patch_all()
import time
import gevent
import requests # 爬取网页
# 10个网页
# 协程函数去发起10个网页的爬取任务
def get_url(url):
res = requests.get(url) #i/o,阻塞
print(url,res.status_code,len(res.text)) url_lst =[
'http://www.sohu.com',
'http://www.baidu.com',
'http://www.qq.com',
'http://www.python.org',
'http://www.cnblogs.com',
'http://www.mi.com',
'http://www.apache.org',
'https://www.taobao.com',
'http://www.360.com',
'http://www.7daysinn.cn/'
] g_lst = []
start = time.time()
for url in url_lst:
g = gevent.spawn(get_url,url) #geven 不仅切换,而且能规避i/o(主要是网络的延迟,socket,爬虫)
g_lst.append(g)
gevent.joinall(g_lst)
print(time.time() - start)
python基础知识点四的更多相关文章
- Python 基础语法(四)
Python 基础语法(四) --------------------------------------------接 Python 基础语法(三)------------------------- ...
- Python基础知识(四)
Python基础知识(四) 一丶列表 定义格式: 是一个容器,由 [ ]表示,元素与元素之间用逗号隔开. 如:name=["张三","李四"] 作用: 存储任意 ...
- Python基础学习四
Python基础学习四 1.内置函数 help()函数:用于查看内置函数的用途. help(abs) isinstance()函数:用于判断变量类型. isinstance(x,(int,float) ...
- 最全Python基础知识点梳理
本文主要介绍一些平时经常会用到的python基础知识点,用于加深印象,也算是对于学习这门语言的一个总结与回顾.python的详细语法介绍可以查看官方编程手册,也有一些在线网站可以学习 python语言 ...
- Python基础知识点小结
1.Python基础知识 在Python中的两种注释方法,分别是#注释和引号(''' ''')注释,#注释类似于C语言中的//注释,引号注释类似于C语言中的/* */注释.接着在Python中 ...
- Python基础知识点总结
Python基础知识与常用数据类型 一.Python概述: 1.1.Python的特点: 1.Python是一门面向对象的语言,在Python中一切皆对象 2.Python是一门解释性语言 3.Pyt ...
- Python基础篇(四)_组合数据类型的基本概念
Python基础篇——组合数据类型的基本概念 集合类型:元素的集合,元素之间无序 序列类型:是一个元素向量,元素之间存在先后关系,通过序号进行访问,没有排他性,具体包括字符串类型.元组类型.列表类型 ...
- python 基础知识点整理 和详细应用
Python教程 Python是一种简单易学,功能强大的编程语言.它包含了高效的高级数据结构和简单而有效的方法,面向对象编程.Python优雅的语法,动态类型,以及它天然的解释能力,使其成为理想的语言 ...
- python基础知识点三
内置函数和匿名函数 python 一共有68个内置的函数:它们就是python提供给你直接可以拿来使用的所有函数 内置函数的图:链接 :https://www.processon.com/mindma ...
随机推荐
- 关于 ubuntu 下 防火墙 ufw的使用
ufw 是 iptables 的一个语法糖.详细介绍
- python中元组与数组的区别
列表: a=['12', '3rr'] 元组: t=(21,34) 列表可以修改,而元组不可以修改,如果元组中仅有一个元素,则要在元素后加上逗号. 元组和列表的查询方式一样. 元组只可读不可修改. 如 ...
- 找不到 main 方法, 请将 main 方法定义为: public static void main(String[] args) 否则 JavaFX 应用程序类必须扩展javafx.应用程序类必 须扩展javafx.application.Application”
用eclipse写代码的时候,写了一个简单的程序,编译的时候突然出现“错误: 在类 com.test.demo 中找不到 main 方法, 请将 main 方法定义为: public static v ...
- WinDbg 之 SOS扩展命令
SOS.dll (SOS debugging extension) The SOS Debugging Extension (SOS.dll) helps you debug managed prog ...
- The way to unwind the stack on Linux EABI
I. probe the stack frame structure The original idea is to unwind the function call stack according ...
- [Day11]接口、多态
1.接口 (1)接口定义:interface关键字 ,所在文件仍然是.java文件,编译后仍产生.class文件. 定义格式 public interface 接口名{ 抽象方法1: 抽象 ...
- TZOJ:3660: 家庭关系
描述 给定若干家庭成员之间的关系,判断2个人是否属于同一家庭,即2个人之间均可以通过这些关系直接或者间接联系. 输入 输入数据有多组,每组数据的第一行为一个正整数n(1<=n<=100), ...
- [转贴] 软件测试职业发展的 A 面和 B 面
[转贴] 软件测试职业发展的 A 面和 B 面 1.所谓的软件测试技术到底包含什么? 梅子:我先来从传统意义上来谈一下测试技术,主要就是测试分析,测试设计,测试管理,测试执行,自动化测试技术,专项测试 ...
- 解决win10无法访问共享
一台win10共享的文件夹,有的电脑是可以访问的,我的win10 访问不了,说什么 遇到未知错误,用以下方法得以解决 ----------------------------------------- ...
- python基础之 面向对象
1.什么是面向对象? 在大学学习c#的时候接触面向对象,知道好像有什么方法,属性,人狗大战啥的.但是都忘记了,也不知道面向对象到底是个啥! 在python中一切都是对象,linux中一切都是文件(突然 ...