mysql数据库优化(三)--分区
mysql的分区,分表
分区:把一个数据表的文件和索引分散存储在不同的物理文件中。 特点:业务层透明,无需任何修改,即使从新分表,也是在mysql层进行更改(业务层代码不动)
分表:把原来的表根据条件分成多个表,如原来的表为 user;现在分成2个小表 user_1,user_2; 特点:业务层需要修改代码。如过业务改变,可能需要从新分表,导致维护困难
当数据量达到一定级别后,需要通过 分区或分表来提高用户体验
如下知识点 为 分区
如:现在生产环境有用户表 account_user,对其按照 日期(每季度)进行分区。
表结构如下:
输入命令:show create table account_user;
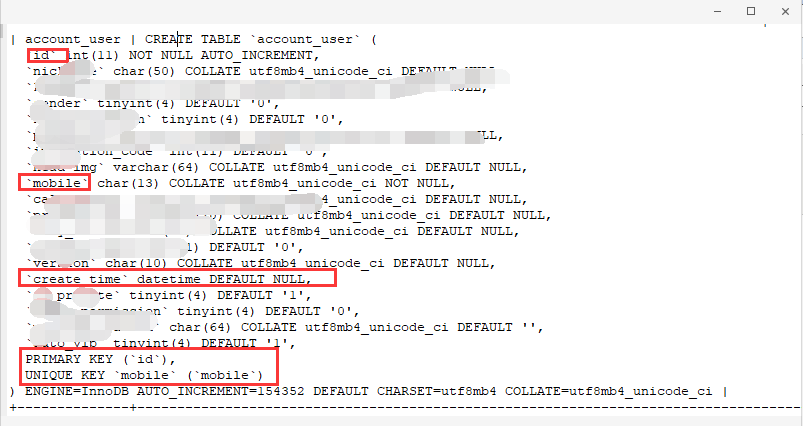
由于此表有 主键和unique键,在分区时,必须要求被用来匹配分区的字段被包含在 主键,和unique键中(也就是复合主键和复合unique键);
通过如下命令进行操作把 create_time分别放在主键和unique键中(这时mobile字段不能保证唯一性,这是个大问题,需要解决)
添加unique键: ALTER TABLE account_user ADD UNIQUE KEY (mobile,create_time);
删除unique键: ALTER TABLE account_user DROP UNIQUE KEY ;
添加主键:ALTER TABLE account_user ADD PRIMARY KEY (id,create_time);
删除主键:ALTER TABLE account_user DROP PRIMARY KEY;
然后根据官网教程:

如下根据range分区进行添加:
ALTER TABLE account_user PARTITION BY RANGE (TO_DAYS(create_time))
(
PARTITION account_user_2018_01 VALUES less than (TO_DAYS('2018-01-01')),
PARTITION account_user_2018_04 VALUES less than (TO_DAYS('2018-04-01')),
PARTITION account_user_2018_07 VALUES less than (TO_DAYS('2018-07-01')),
PARTITION account_user_2018_10 VALUES less than (TO_DAYS('2018-10-01')),
PARTITION account_user_2018_more VALUES less than MAXVALUE
)
然后查看 结果:

验证分区效果:
优点:根据create_time进行范围查询,会使用分区,避免全表扫描
使用分区的情况下:

只是查询了 3351行,或者说是查询了 (account_user_2018_01,account_user_2018_04,account_user_2018_07)三个分区
在没有分区的情况下:

发现进行全表扫描,行数为46808行
相关操作:
查看行数据所在分区:SELECT * FROM account_user PARTITION (account_user_2018_07) WHERE id=1;
增加分区: ALTER TABLE account_user ADD PARTITION (PARTITION account_user_2019_01 VALUES LESS THAN (TO_DAYS('2019-01-01'))); 如果对应range分区有 MAXVALUE ,要先删除,否则报错
删除分区: ALTER TABLE account_user DROP PARTITION account_user_2019_01;
删除分区数据:ALTER TABLE account_user TRUNCATE PARTITION account_user_2019_01,account_user_2019_04;
rebuild重建分区:ALTER TABLE account_user REBUILD PARTITION account_user_2019_01; #相当于drop所有记录,然后再reinsert;可以解决磁盘碎片
优化分区:ALTER TABLE account_user OPTIMIZE PARTITION account_user_2019_01; #在删除数据后回收空间和碎片整理
analzye分区:ALTER TABLE account_user ANALZYE PARTITION account_user_2019_01;
check分区:ALTER TABLE account_user CHECK PARTITION account_user_2019_01;
所有分区方式:
list: 每个分区的定义和选择是基于某列的值从属于一个值列表集中的一个值. 将要匹配的任何值都必须在值列表中找到。
如:
ALTER TABLE account_user PARTITION BY LIST (TO_DAYS(create_time))
(
PARTITION account_user_2018_01 VALUES IN (TO_DAYS('2018-01-01'),TO_DAYS('2018-01-02')),
PARTITION account_user_2018_04 VALUES IN (TO_DAYS('2018-01-03'),TO_DAYS('2018-01-04'))
)
range:每个分区包含那些分区表达式的值位于一个给定的连续区间内的行
如:
ALTER TABLE account_user PARTITION BY RANGE (TO_DAYS(create_time))
(
PARTITION account_user_2018_01 VALUES less than (TO_DAYS('2018-01-01')),
PARTITION account_user_2018_04 VALUES less than (TO_DAYS('2018-04-01')),
PARTITION account_user_2018_07 VALUES less than (TO_DAYS('2018-07-01')),
PARTITION account_user_2018_10 VALUES less than (TO_DAYS('2018-10-01')),
PARTITION account_user_2018_more VALUES less than MAXVALUE
)
在使用 范围查询 create_time 时,会使用分区进行查询(时间复杂度:O(log N)),所有速度比没有使用分区(时间复杂度:O(N))的快。
hash:无需定义分区的条件,数据会平均分配到每个分区。只需要指明分区数即可。
如:
ALTER TABLE account_user PARTITION BY HASH(TO_DAYS(create_time))
PARTITIONS 5
LINEAR HASH分区:在数据量大的场景,譬如TB级,增加、删除、合并和拆分分区会更快,缺点是,相对于HASH分区,它数据分布不均匀的概率更大。
ALTER TABLE account_user PARTITION BY LINEAR HASH(TO_DAYS(create_time))
PARTITIONS 5
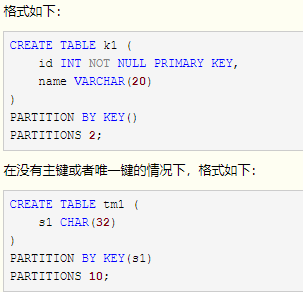
key分区:
1. KEY分区允许多列,而HASH分区只允许一列。
2. 如果在有主键或者唯一键的情况下,key中分区列可不指定,默认为主键或者唯一键,如果没有,则必须显性指定列。
3. KEY分区对象必须为列,而不能是基于列的表达式。
4. KEY分区和HASH分区的算法不一样,PARTITION BY HASH (expr),MOD取值的对象是expr返回的值,而PARTITION BY KEY (column_list),基于的是列的MD5值。
分区优点:
分区可以分在多个磁盘,存储更大一点
根据查找条件,也就是where后面的条件,查找只查找相应的分区不用全部查找了
进行大数据搜索时可以进行并行处理。
跨多个磁盘来分散数据查询,来获得更大的查询吞吐量
分区缺点:
其 分区对应的key必须包含主键或者unique键,导致 unique 键的字段失效(如用户注册表,手机号唯一性)
需要仔细考虑评估业务系统 对表 进行操作的侧重点,然后选择字段和分区方式进行分区,尽量平均分配数据到每个分区。分区后进行相关验证性测试 是否有效果
案例:
1.公司通过推荐注册可以提现红包的方式拉取用户,造成 其他人利用接口恶意注册僵尸用户,导致用户表数据量过多,影响正常用户的使用。需求:活跃用户只有总用户的5%,如何提高活跃用户的体验?
方案:
1.在 用户表中增加一个 代表活跃度的字段,在用户每次活跃后,其值相应增加。通过 分区的方式(通过 活跃度 字段进行range分区),提高访问速度 。
优点:无需系统层改变代码,活跃度改变后,会自动分区
2.在 用户表中增加一个 代表活跃度的字段,在用户每次活跃后,其值相应增加。通过分表的方式(根据 活跃度),
缺点:需要系统层(应用程序)改变代码。
在用户活跃度变化后,需要手动的从一个表变到另一个表,导致需要定期维护,较为复杂
相关资料:
https://blog.csdn.net/yongchao940/article/details/55266603
https://www.cnblogs.com/phpshen/p/6198375.html
https://blog.csdn.net/kingcat666/article/details/78324678
mysql数据库优化(三)--分区的更多相关文章
- 从运维角度来分析mysql数据库优化的一些关键点【转】
概述 一个成熟的数据库架构并不是一开始设计就具备高可用.高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善. 1.数据库表设计 项目立项后,开发部根据产品部需求开发项目,开发工程师工作其中一部分 ...
- mysql 数据库优化第一篇(基础)
Mysql数据库优化 1. 优化概述 存储层:存储引擎.字段类型选择.范式设计 设计层:索引.缓存.分区(分表) 架构层:多个mysql服务器设置,读写分离(主从模式) sql语句层:多个sql语句都 ...
- MySQL数据库优化、设计与高级应用
MySQL数据库优化主要涉及两个方面,一方面是对SQL语句优化,另一方面是对数据库服务器和数据库配置的优化. 数据库优化 SQL语句优化 为了更好的看到SQL语句执行效率的差异,建议创建几个结构复杂的 ...
- Mysql数据库优化技术之配置篇、索引篇 ( 必看 必看 转)
转自:Mysql数据库优化技术之配置篇.索引篇 ( 必看 必看 ) (一)减少数据库访问对于可以静态化的页面,尽可能静态化对一个动态页面中可以静态的局部,采用静态化部分数据可以生成XML,或者文本文件 ...
- 【MySQL】花10分钟阅读下MySQL数据库优化总结
1.花10分钟阅读下MySQL数据库优化总结http://www.kuqin.com2.扩展阅读:数据库三范式http://www.cnblogs.com3.my.ini--->C:\Progr ...
- 50多条mysql数据库优化建议
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的.在非群集索引下,数据在物理上随机存 ...
- 解开发者之痛:中国移动MySQL数据库优化最佳实践(转)
开源数据库MySQL比较容易碰到性能瓶颈,为此经常需要对MySQL数据库进行优化,而MySQL数据库优化需要运维DBA与相关开发共同参与,其中MySQL参数及服务器配置优化主要由运维DBA完成,开发则 ...
- mysql数据库优化 pt-query-digest使用
mysql数据库优化 pt-query-digest使用 一.pt-query-digest工具简介 pt-query-digest是用于分析 mysql慢查询的一个工具,它可以分析binlog.Ge ...
- MySQL数据库优化详解(收藏)
MySQL数据库优化详解 mysql表复制 复制表结构+复制表数据mysql> create table t3 like t1;mysql> insert into t3 select * ...
- 中国移动MySQL数据库优化最佳实践
原创 2016-08-12 章颖 DBAplus社群 本文根据DBAplus社群第69期线上分享整理而成,文末还有书送哦~ 讲师介绍章颖 数据研发工程师 现任中国移动杭州研发中心数据研发工程师,擅长M ...
随机推荐
- Python字符编码的发展、cmd寻找路径
字符编码的发展: ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示 ...
- python全栈开发笔记----基本数据类型---列表方法
#list 类中提供的方法 #参数 1.def append(self, *args, **kwargs)原来值最后追加#对象..方法(..) #li对象调用append方法 li = [11,22, ...
- docker-compose docker启动工具,容器互联
简介: docker可以一条命令就运行一个配置好的服务器,很是方便. 但是也有一个问题就是,当参数比较多,映射目录比较多,映射端口比较多………… 我以前就是写个脚本,用脚本来启动,很low啊. 也见到 ...
- leetcode python 030 Substring with Concatenation of All Words
## 您将获得一个字符串s,以及一个长度相同单词的列表.## 找到s中substring(s)的所有起始索引,它们只包含所有单词,## eg:s: "barfoothefoobarman&q ...
- intelij idea常用功能介绍
1.查看本地文件修改记录 保存本地修改记录: 可以将system下的LocalHistory保存,到另一个目录,需要的时候保存即可. 2.debbuger查看代码 1)优化设置 2)常用 3.条件断点 ...
- Angular2 NgModule 模块详解
原文 https://segmentfault.com/a/1190000007187393 我们今天要学习的是Angular2的模块系统,一般情况下我们使用一个根模块去启动我们的应用,然后使用许多 ...
- Charles抓包基本用法
Charles抓包 浏览器发送和接受的所有请求都可以抓到 1.可以定位问题(如果看不出来是服务端问题还是前端问题) 2.可以设置弱网模式 清空请求按钮如图: 抓包: 1 打开charles,在浏览器中 ...
- Python2入门(1)
一.基础语法1 - 输出语句 print "hello world",print默认输出换行,如果需要实现不换行需在变量末尾加上逗号,; 2 - python合法标识符 3 - 字 ...
- https加载非https资源时不出现问题
老规矩,国服第一博客copy王,原文链接:https://blog.csdn.net/zhengbingmei/article/details/81325325将系统变成了https访问之后,发现部分 ...
- python学习之路07
Python中你可能不关心的这几个关键字:break.continue.pass 1.break 作用:跳出循环[直接跳出整个循环,继续执行后面的代码] 1.特殊情况一 #当break使用在嵌套循环中 ...