Hadoop RPC源码分析
Hadoop RPC源码分析
上一篇文章http://www.cnblogs.com/dycg/p/rpc.html
讲了Hadoop RPC的使用方法,这一次我们从demo中一层层进行分析。
RPC说白了,就3个核心,交互协议、服务端、客户端。
在Hadoop RPC(hadoop-common-2.4.jar)中也是这样
交互协议
org.apache.hadoop.ipc.VersionedProtocol ,所有协议的父类
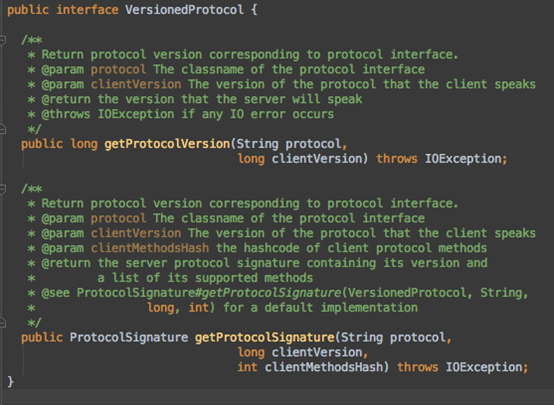
其实就2个方法,版本与签名。不同版本与签名的协议,就算同一个类名也无法通信。
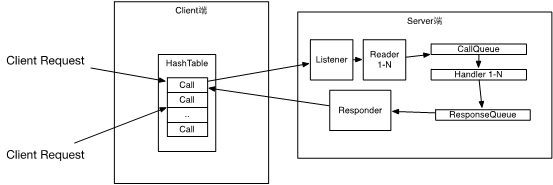
服务端:
RPC.Server 处理客户端的连接请求,并处理相关业务,最后返回结果
客户端:
Client,封装请求数据,并接收Response
好,正式开始分析源码吧。
协议部分,我就不说了,就是实现VersionedProtocol接口并添加一些业务方法即可。
我们从客户端程序入口点开始分析,先看看客户端是如何取得协议对象的。

想要与服务端通信就先要得到协议对象,RPC.getProxy就是得到协议对象的方法,沿着代码进入最底层,你会发现,它默认先得到一个RpcEngine(默认实现是WritableRpcEngine),它是什么呢?简单点说就是,它相当于我们启动服务器,获取协议的类。有了WritableRpcEngine后,调用它的getProxy方法,得到我们的协议代理对象(采用java的动态代理机制实现),对应我们的例子就是ClientProtocol的代理对象。

最关键就是这个Invoker对象,我们调用ClientProtocol.echo()方法时候,会先触发这个Invoker.invoke()方法。
Invoker对象如何构造的呢

其实就创建了2个成员变量:
ConnectionID:
保存目标地址(remoteAddress,protocol)和用户ticket,这三者可以唯一确定一个Connection
Client:
主要完成的功能是发送远程调用信息并接收返回结果。图中的factory,是SocketFactory
接着,当我们调用ClientProtocol.echo()方法的时候,触发Invoker.invoke,让我们看看这一步又干了什么事
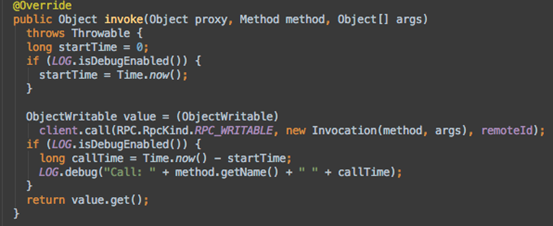 封装一个Invocation对象,这个对象持有目标方法和参数。
封装一个Invocation对象,这个对象持有目标方法和参数。
进入client.call()方法看看
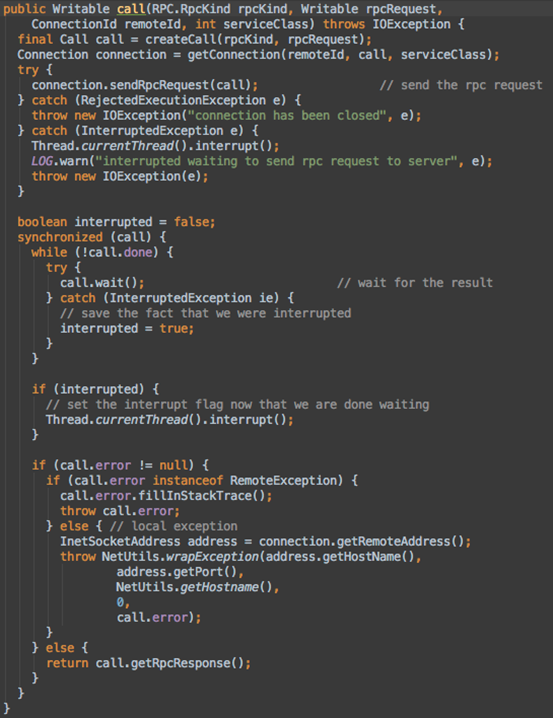
这下切入正题了
- 首先创建一个Call对象,封装了RPC请求,成员变量有唯一标识id、请求数据、返回数据、是否完成等
- 创建Connection对象(它是个线程),并与服务器连接,即Client与Server之间的一个通信连接。保存未完成的Call对象至哈希表,唯一标识ID,Server通信的Socket,网络输入输出流。
- 调用connection.sendRpcRequest(call);将Call对象发送给Server
- 等待Server端处理Call请求。服务端处理完成后,通过网络返回给Client端。这部分代码不在call方法里,还记得1中Connection是个线程吗?去run方法看看
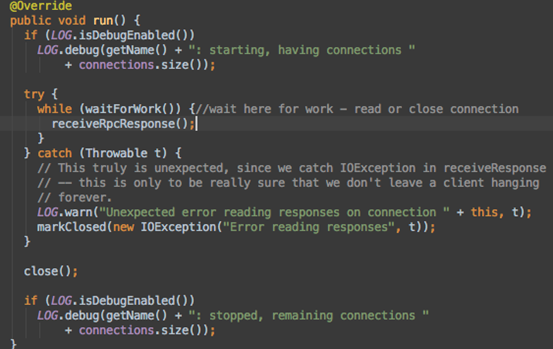
线程一直循环,直到Server返回结果,然后调用receiveRpcResponse方法返回数据。
- 再次回到call方法,它也有个循环,一直在等待结果返回。结果返回后,检查下成功失败后,就将Call从哈希表中移除了。
经历了上面5步,String result = proxy.echo("123"); 的结果是result = hello 123
最后,我们再看看服务端是怎么工作的。
如何启动服务?

启动服务器很简单,通过RPC.Builder().build()构造Server后就能start启动了。我们进入build()方法内部看看。

return这里,想想看,它其实就是调用WritableRpcEngine.getServer()方法。
看看代码非常多,其实最关键的就一个Server.java Line 2176行
responder = new Responder();
仔细看这个类,它作用是启动一个线程,从reponseQueue中一个个处理要返回给客户端的数据,有些数据可能比较大,一次无法完全返回,则将剩下的数据重新加入队列等待下一次返回。
再进入Server.start()方法看看:
简单明了。 Responder就是刚刚创建的用于返回数据给客户端的线程,启动它。
Listener是什么?
继续看代码,用了JAVA NIO, 它是负责监听客户端连接请求的,它内部又有
private Reader[] readers = null;
每个Reader是一个线程,负责读取连接请求发来的数据,也用了NIO。
那它把数据读来放哪?
processRpcRequest()跟踪到这个方法,发现它把读取完成的数据创建到一个新的Call对象,然后放入callQueue

那什么时候处理呢?
别急,上上图还有个Handler还没看呢。
它也是个线程,启动了N个。一直在循环处理callQueue中的call,如果队列中没call就block waiting。
读到Call后,依然是调用call方法,一层层进去看,最后还是回到了WritableRpcEngine.call() Line 417行,
Object value = method.invoke(protocolImpl.protocolImpl, call.getParameters());
得到结果后,就开始返回给Client了,如果没发一次性全部返回,剩下部分就交给Reponder线程去完成。
至此,整体流程全部完成。 我们来个全家福。
Hadoop RPC源码分析的更多相关文章
- [Hadoop] - TaskTracker源码分析(状态发送)
TaskTracker节点向JobTracker汇报当前节点的运行时信息时候,是将运行状态信息同心跳报告一起发送给JobTracker的,主要包括TaskTracker的基本信息.节点资源使用信息.各 ...
- Hadoop TextInputFormat源码分析
from:http://blog.csdn.net/lzm1340458776/article/details/42707047 InputFormat主要用于描述输入数据的格式(我们只分析新API, ...
- Hadoop RPC源码阅读-交互协议
Hadoop版本Hadoop2.6 RPC主要分为3个部分:(1)交互协议(2)客户端 (3)服务端 (1)交互协议 协议:把某些接口和接口中的方法称为协议,客户端和服务端只要实现这些接口中的方法就可 ...
- Hadoop RPC源码阅读-客户端
Hadoop版本Hadoop2.6 RPC主要分为3个部分:(1)交互协议(2)客户端(3)服务端 (2)客户端 先展示RPC客户端实例代码 public class LoginController ...
- [Hadoop] - TaskTracker源码分析
在Hadoop1.x版本中,MapReduce采用master/salve架构,TaskTracker就是这个架构中的slave部分.TaskTracker以服务组件的形式存在,负责任务的执行和任务状 ...
- 踏着前人的脚印学Hadoop——RPC源码
A simple RPC mechanism.A protocol is a Java interface. All parameters and return types must be one ...
- Hadoop RPC源码阅读-服务端Server
Hadoop版本Hadoop2.6 RPC主要分为3个部分:(1)交互协议 (2)客户端(3)服务端 (3)服务端 RPC服务端的实例代码: public class Starter { public ...
- [Hadoop] - TaskTracker源码分析(TaskTracker节点健康状况监控)
在TaskTracker中对象healthStatus保存了当前节点的健康状况,对应的类是org.apache.hadoop.mapred.TaskTrackerStatus.TaskTrackerH ...
- Hadoop TaskScheduler源码分析
TaskScheduler是MapReduce中的任务调度器.在MapReduce中,JobTracker接收JobClient提交的Job,将它们按InputFormat的划分以及其他相关配置,生成 ...
随机推荐
- 转)nodejs后台启动方式PM2
如果直接通过node app来启动,如果报错了可能直接停在整个运行,supervisor感觉只是拿来用作开发环境的.再网上找到pm2.目前似乎最常见的线上部署nodejs项目的有forever,pm2 ...
- [leetcode]54. Spiral Matrix螺旋矩阵
Given a matrix of m x n elements (m rows, n columns), return all elements of the matrix in spiral or ...
- python的基本用法(一)
1.什么变量,什么是数据类型? 变量就是用来存放东西的, 数据类型:字符串str,整数int,浮点数(小数)float type()函数用来检验数据格式的类型 2.什么是for循环,什么是while循 ...
- Spark2.0学习(一)--------Spark简介
官网对Spark的介绍 http://spark.apache.org/ Apache Spark™ is a unified analytics engine for large-scale dat ...
- windows下 zookeeper
1.zookeeper的安装和配置 下载:http://zookeeper.apache.org/releases.html 把conf目录下的zoo_sample.cfg改名成zoo.cfg,这里我 ...
- CentOS上部署.net core
1.阿里云更换系统安装CentOS7.4 64位版本 2.试用XShell 5 登录服务器 参考https://www.microsoft.com/net/learn/get-started/linu ...
- 3.在自己的bag上运行Cartographer ROS
1.验证自己的bag cartographer ROS提供了一个工具cartographer_rosbag_validate来自动分析包中的数据.在尝试调试cartographer之前运行这个工具. ...
- 《Linux就该这么学》第三天课程
秦时明月经典语录: 王道: 千里挥戈,万众俯首.四海江湖,百世王道.——项羽 今天主要介绍了常用系统工作的命令 如需进一步了解,请前往https://www.linuxcool.com(附带配音) r ...
- Jmeter小技巧以及问题集合
一.JDBC Request与BeanShell PostProcessor的结合使用 JDBCRequest部分 BeanShell PostProcessor配置项 二.if控制器的用法 三. ...
- 下划线字符串camel
const camel = (str) => { let slices = str.split('_'); let result = []; for(let i = 1, len = slice ...