分布式计算(五)Azkaban使用
在安装好Azkaban后,熟悉Azkaban的用法花了较长时间,也踩了一些坑,接下来将详细描述Azkaban的使用过程。
目录
一、界面介绍
二、Projects
1. 创建Command类型单一Job示例
1)创建一个Project,填写名称和描述
2)点击Create Project之后
3)创建Job
4)打包Job资源文件并上传
2. 创建Command类型多Job工作流
1)创建Project
2)上传文件
3)执行一次
4)指定定时任务
一、界面介绍

首页有6个菜单:
- Projects:最重要的部分,创建一个工程,所有flows将在工程中运行
- Scheduling:显示定时任务
- Executing:显示当前运行的任务
- History:显示历史运行任务
- Scheduled Flow Triggers:定时flow触发器
- Documentation:Azkaban文档
二、Projects
创建工程:创建之前我们先了解下Project、Flow和Job之间的关系,一个Project包含一个或多个Flow,一个Flow包含多个Job。Job是你想在Azkaban中运行的一个进程,可以是简单的Linux命令,可以是Java程序,也可以是复杂的Shell脚本,当然,如果你安装相关插件,也可以运行插件。一个Job可以依赖于另一个Job,这种多个Job和它们的依赖组成的图表叫做Flow。
1. 创建Command类型单一Job示例
1)创建一个Project,填写名称和描述

2)点击Create Project之后
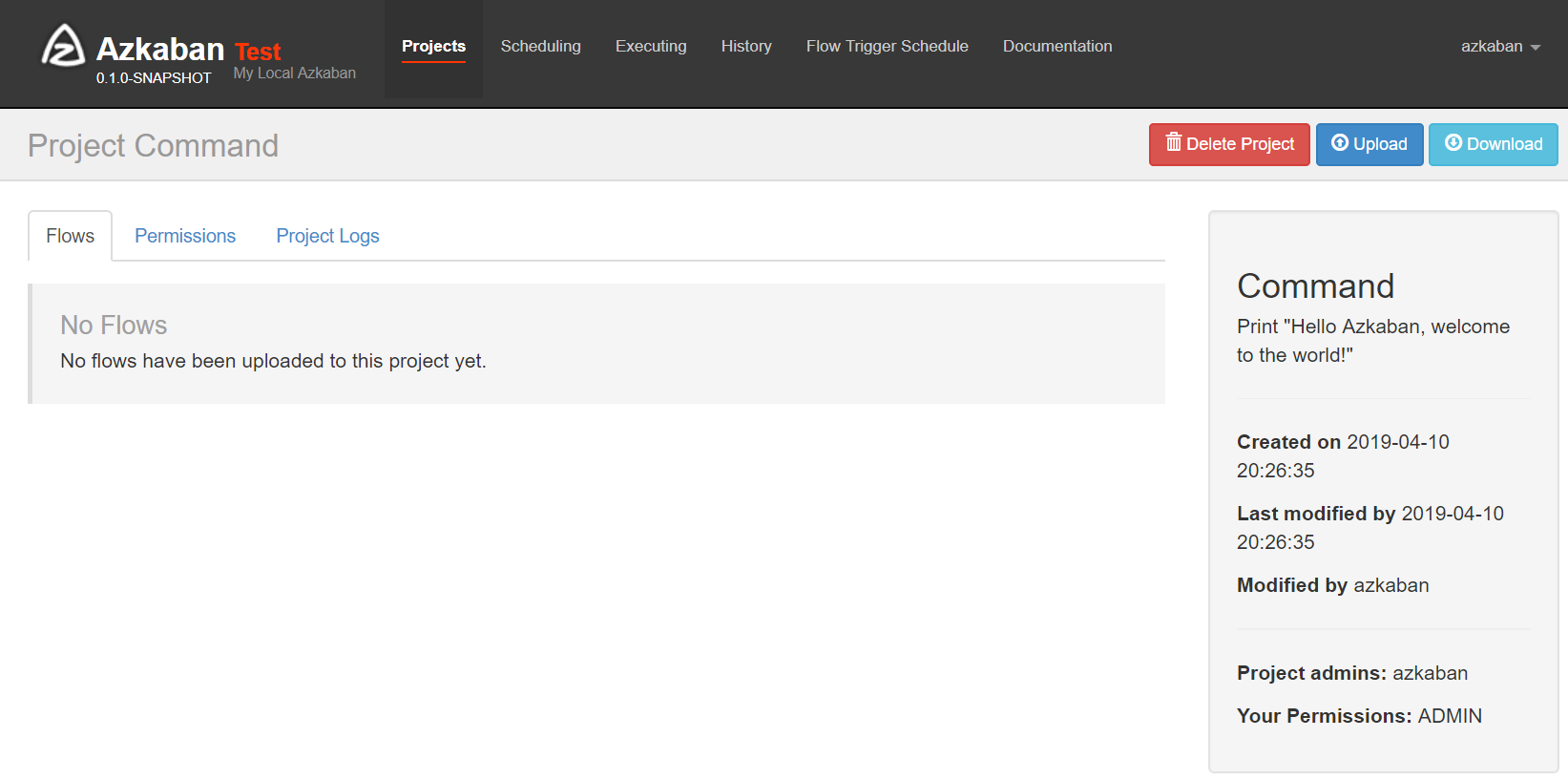
- Flows:工作流程,由多个Job组成
- Permissions:权限管理
- Project Logs:工程日志
3)创建Job
创建Job很简单,只要创建一个以.job结尾的文本文件就行了,例如我们创建一个工作,用来打印Hello Azkaban, welcome to the world!,名字叫做command.job
#command.job type=command command=echo 'Hello Cellphone, welcome to this world!'
一个简单的job就创建好了,解释下,type的command,告诉Azkaban用unix原生命令去运行,比如原生命令或者Shell脚本,当然也有其他类型,后面介绍。
4)打包Job资源文件并上传
注意:只能是zip格式!!!
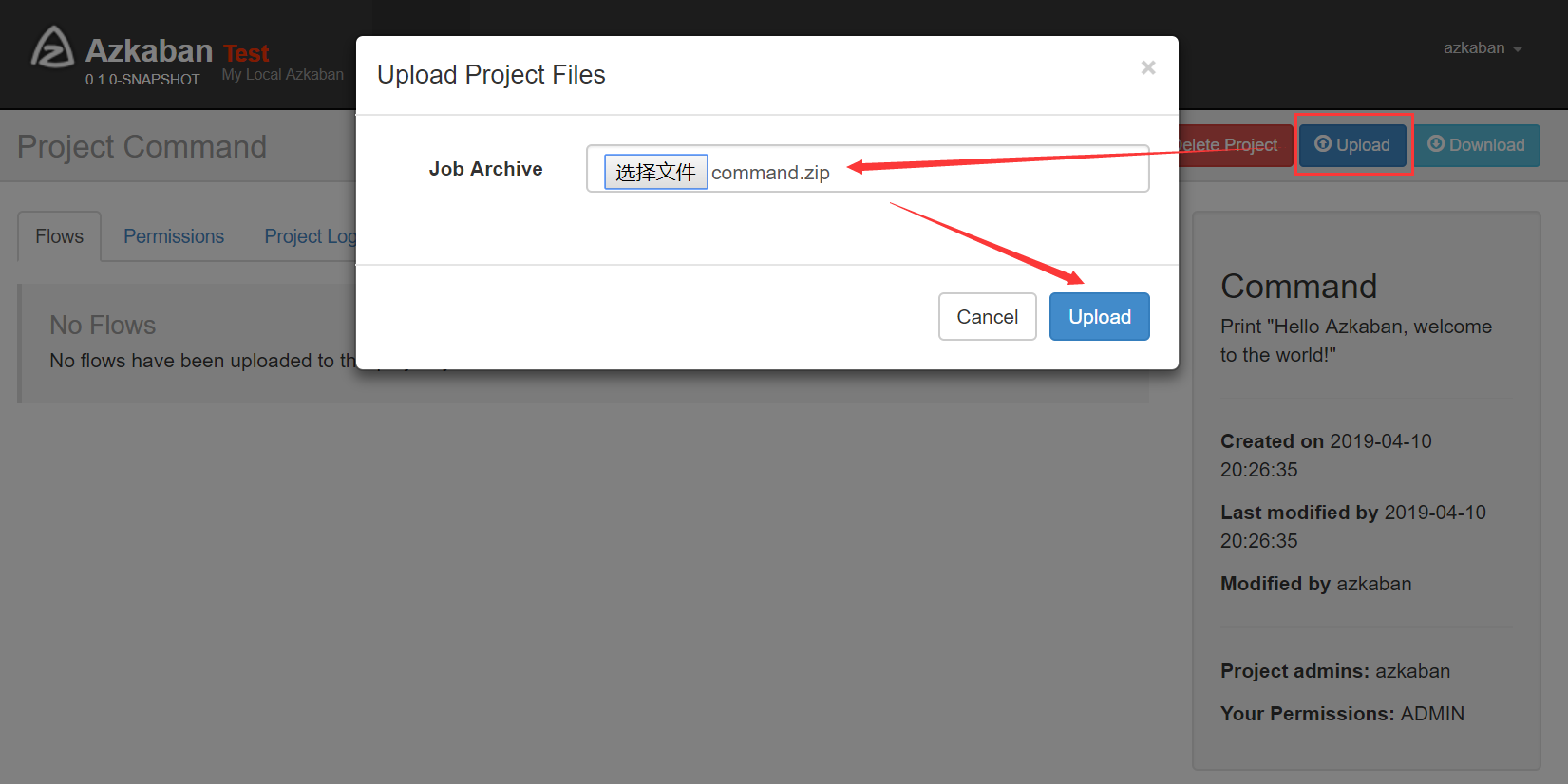
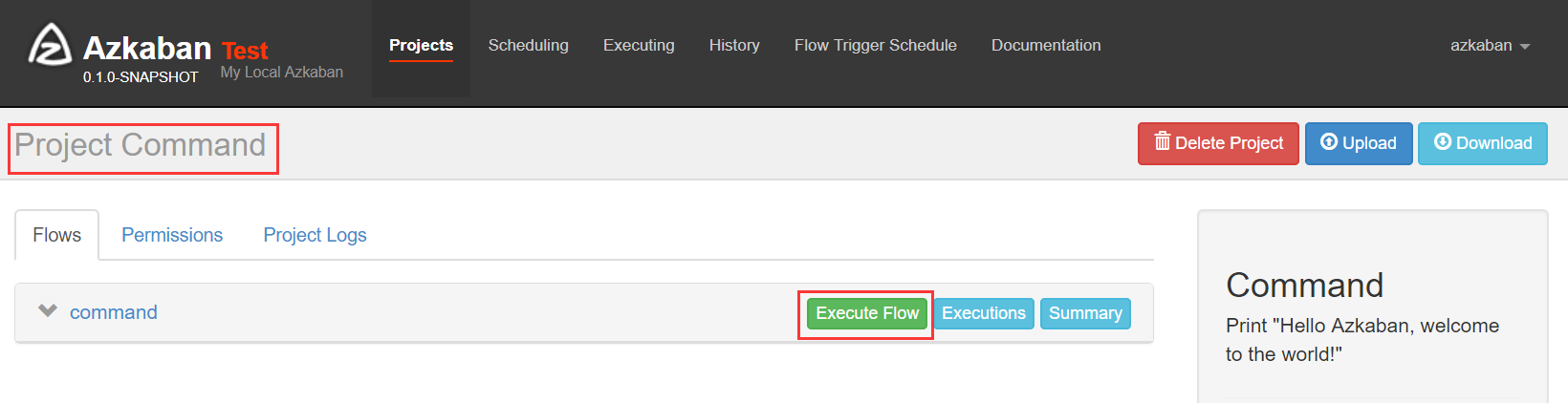

在分布式计算(四)Azkaban安装文中说到,安装的是two server model模式,所以在执行Flow时需要显示指定useExecutor,在 flow params中设置"useExecutor" = EXECUTOR_ID,而EXECUTOR_ID是数据表executors的id。如果不指定,配置的Flow是无法成功执行的。如果不想通过页面设置来指定Executor,可以在properties文件中指定,同时在代码中加上对该属性的解析,然后,才能分发到指定Executor。

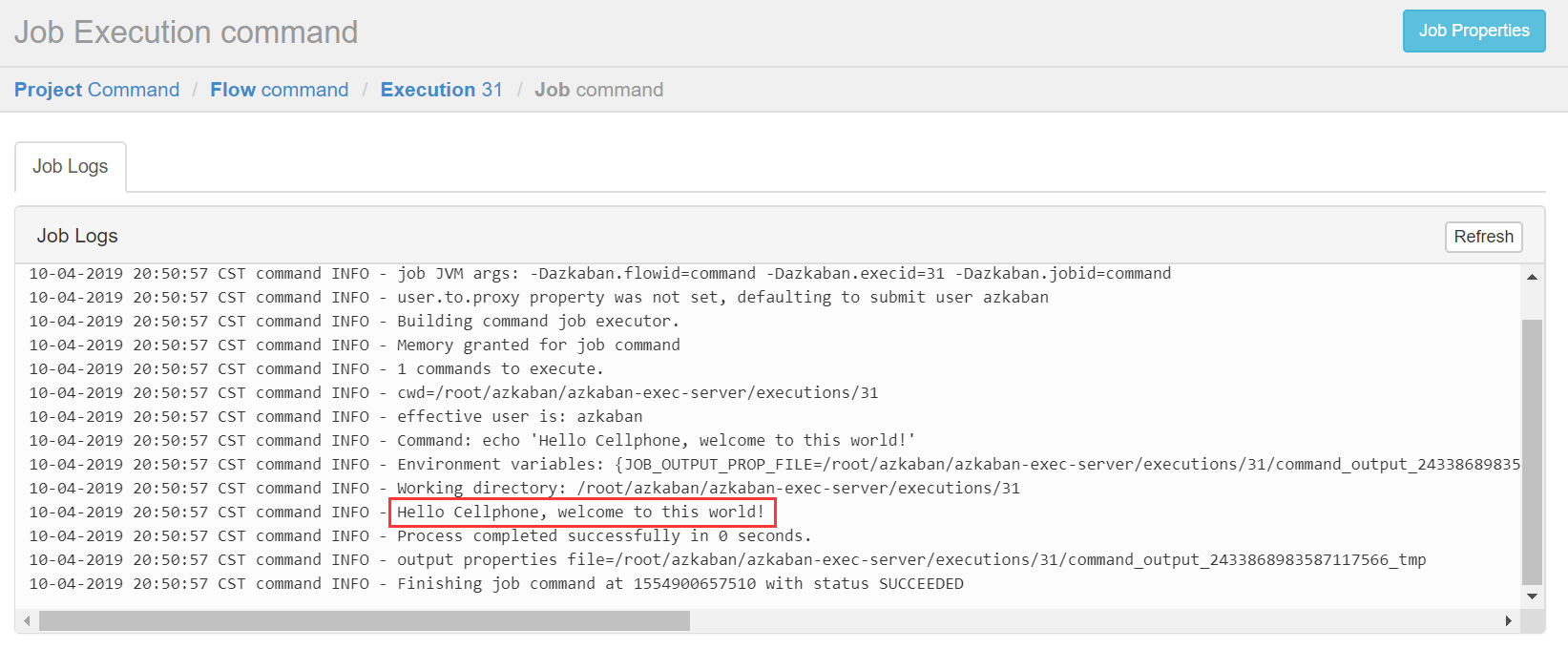
2. 创建Command类型多Job工作流
1)创建Project
前面介绍过多个Job和它们的依赖组成Flow。怎么创建依赖,只要指定dependencies参数就行了。比如导入Hive前,需要进行数据清洗,数据清洗前需要上传,上传之前需要从Ftp获取日志。
定义5个Job:
1. download_log_from_ftp1:从ftp1下载日志
2. download_log_from_ftp2:从ftp2下载日志
3. upload_log_to_hdfs:上传日志到hdfs
4. clean_data:清洗数据
5. transport_data_to_hive:将清洗完的数据入hive库
依赖关系:
3依赖1和2,4依赖3,5依赖4,1和2没有依赖关系。
download_log_from_ftp1.job
type=command
# 执行sh脚本,建议这样做,后期只需维护脚本就行了,azkaban定义工作流程
# 这里为了测试,把command修改为echo + 相应命令
command=echo 'sh /job/download_log_from_ftp1.sh'
download_log_from_ftp2.job
type=command
# 执行sh脚本,建议这样做,后期只需维护脚本就行了,azkaban定义工作流程
# 这里为了测试,把command修改为echo + 相应命令
command=echo 'sh /job/download_log_from_ftp2.sh'
upload_log_to_hdfs.job
type=command
command=echo 'sh /job/upload_log_to_hdfs.sh'
#多个依赖用逗号隔开
dependencies=download_log_from_ftp1,download_log_from_ftp2
clean_data.job
type=command
command=echo 'sh /job/clean_data.sh'
#多个依赖用逗号隔开
dependencies=upload_log_to_hdfs
transport_data_to_hive.job
type=command
command=echo 'sh /job/transport_data_to_hive.sh'
#多个依赖用逗号隔开
dependencies=clean_data
可以运行unix命令,也可以运行python脚本(强烈推荐)。将上述job打成zip包。
2)上传文件
创建工程MultiJob,并上传MultiJob.zip
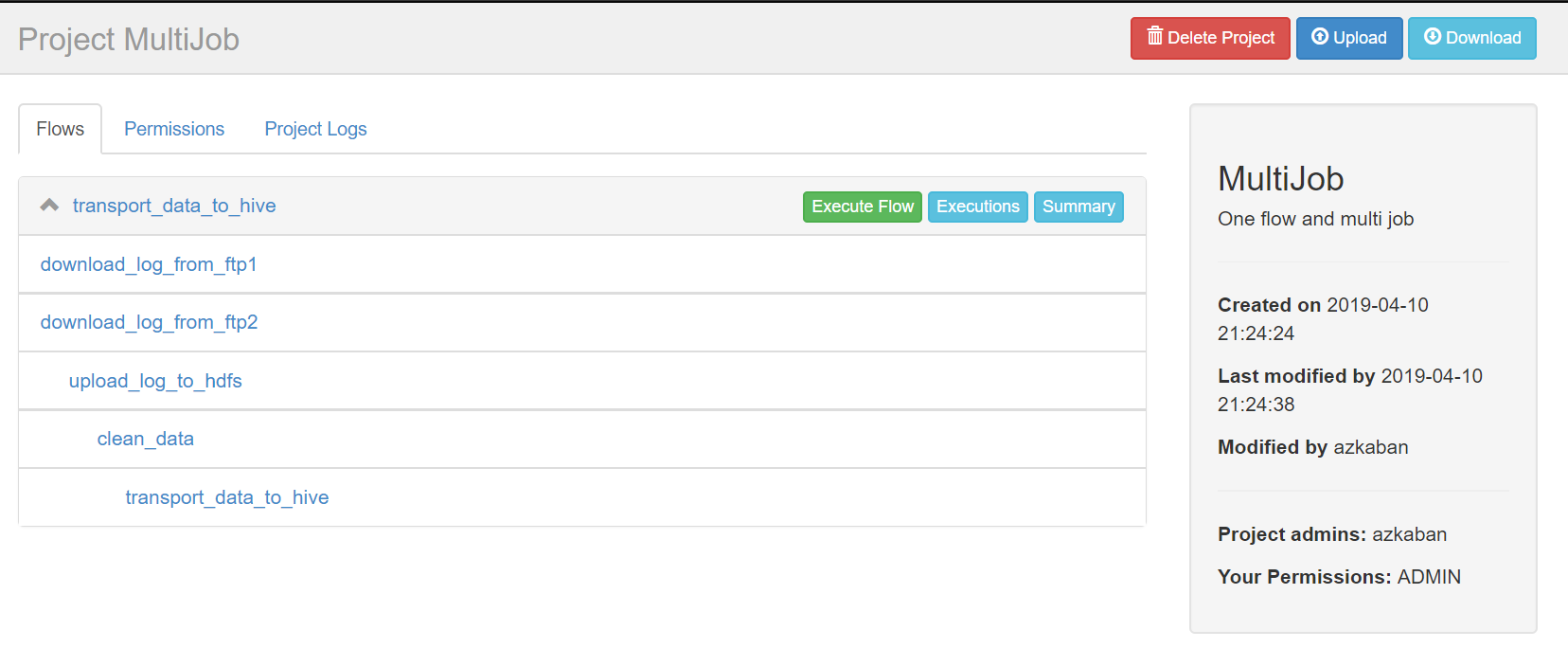
点击transport_data_to_hive进入流程,azkaban流程名称以最后一个没有依赖的job定义的。
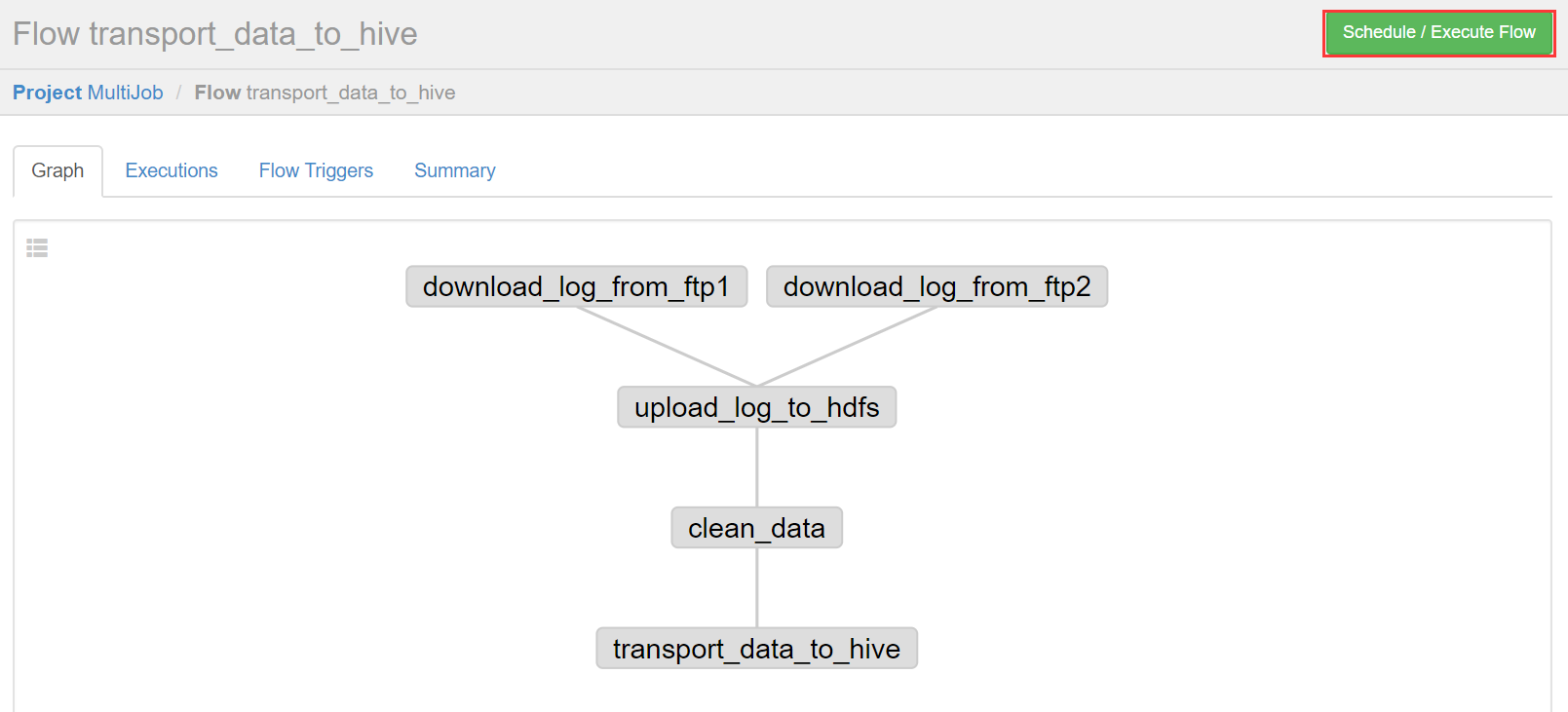
右上方是配置执行当前流程或者执行定时流程。

说明:
Flow view:流程视图,可以禁用,启用某些Job
Notification:定义任务成功或者失败是否发送邮件
Failure Options:定义一个Job失败,剩下的Job怎么执行
Concurrent:并行任务执行设置
Flow Parametters:参数设置
3)执行一次
设置好上述参数,点击execute。
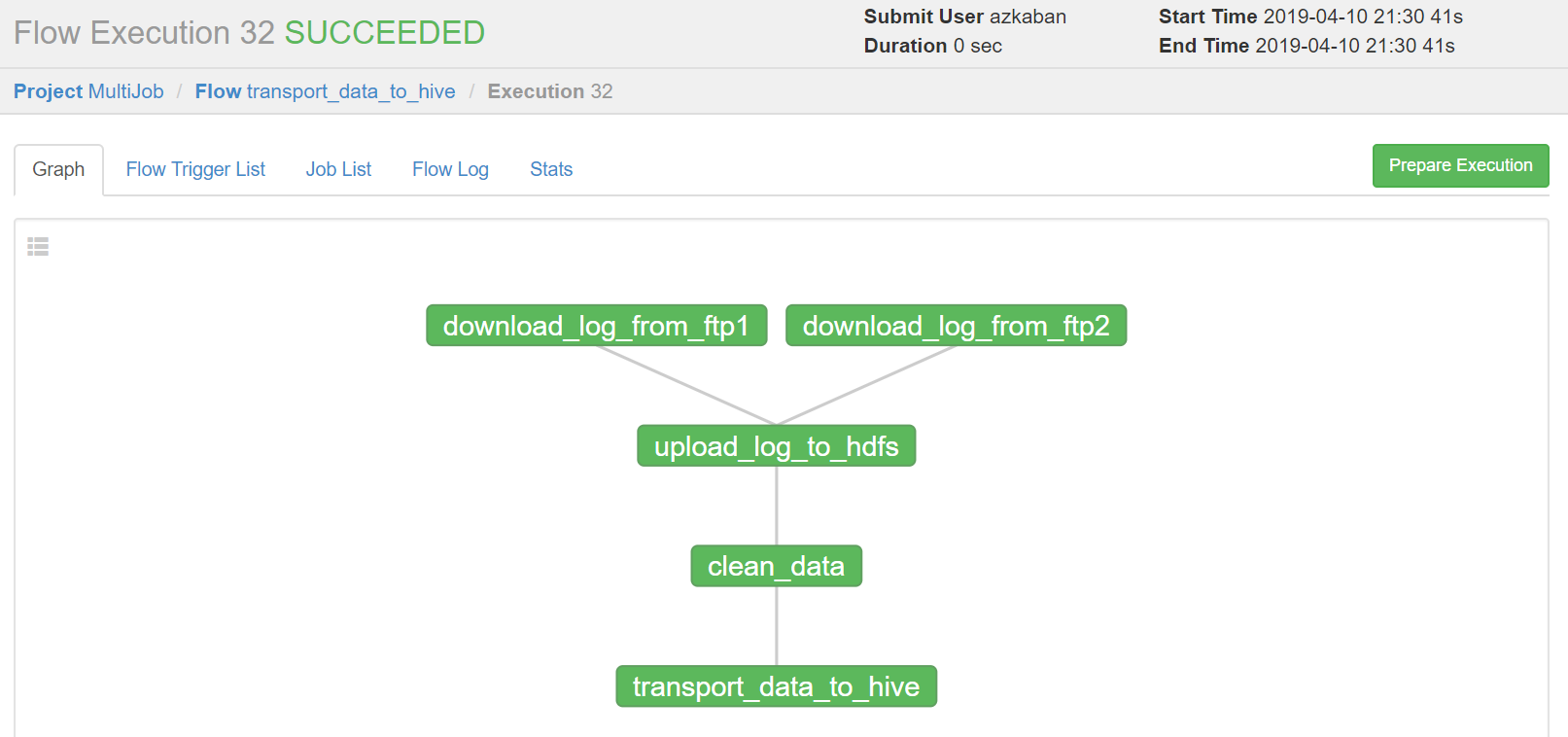
绿色代表成功,蓝色是运行,红色是失败。可以查看job运行时间,依赖和日志,点击details可以查看各个job运行情况。
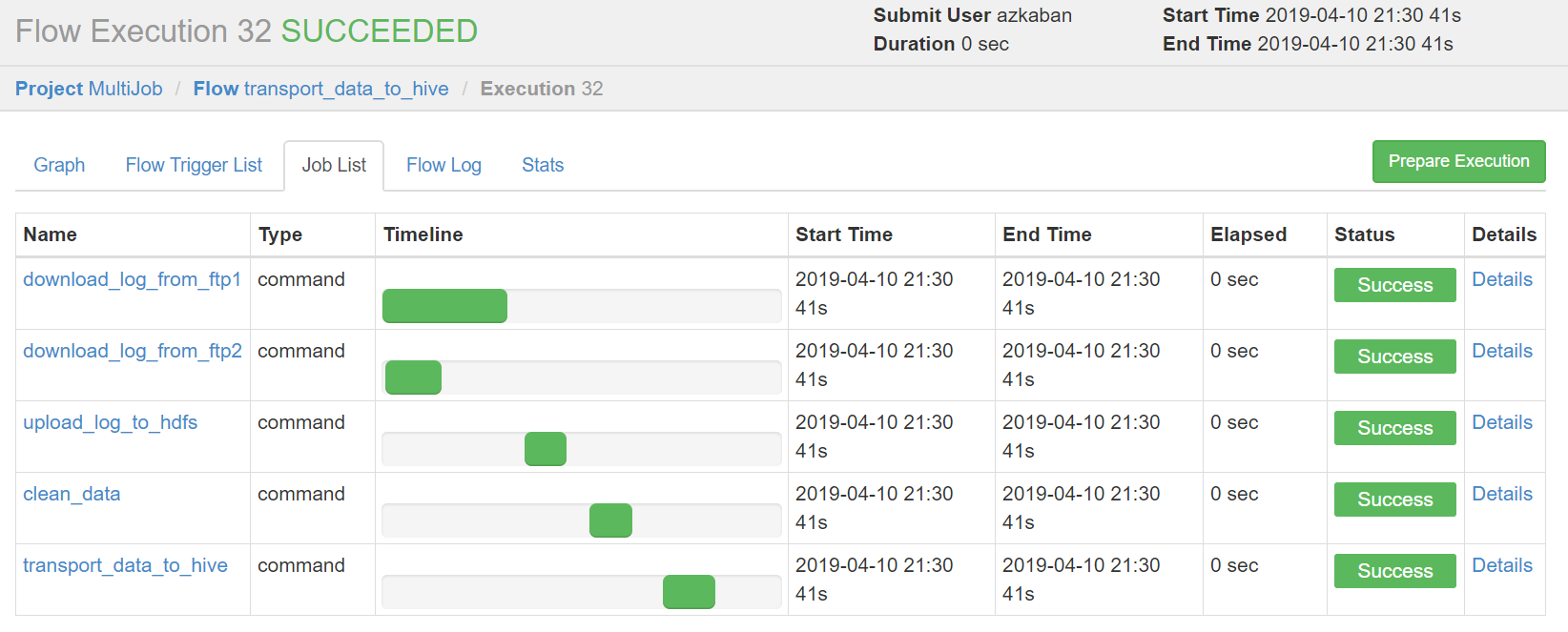
4)指定定时任务
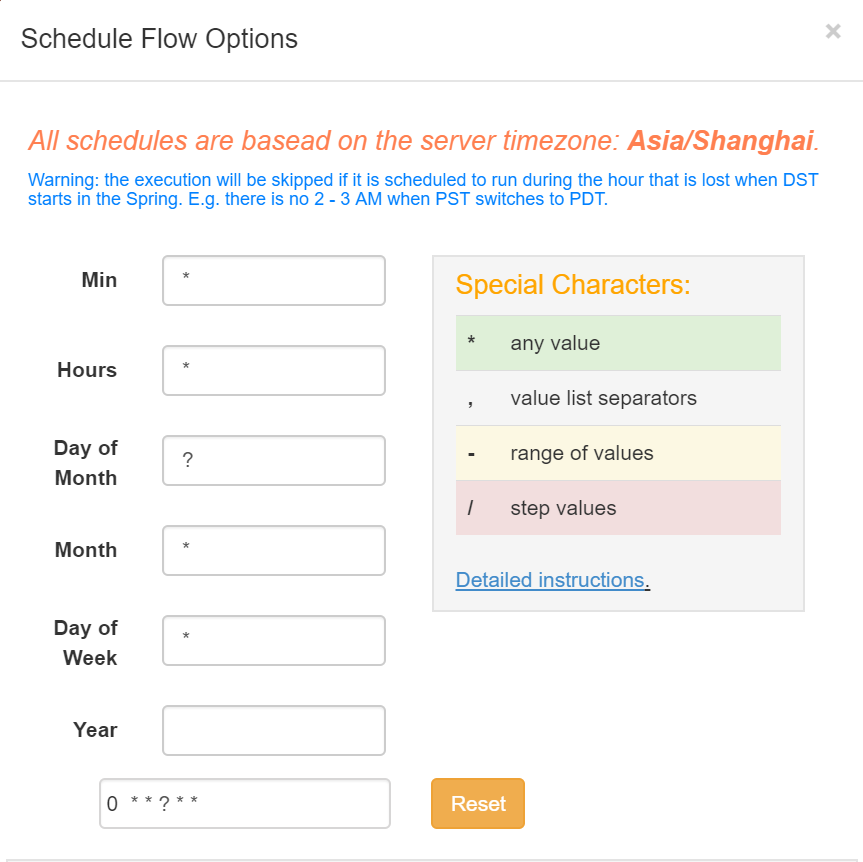
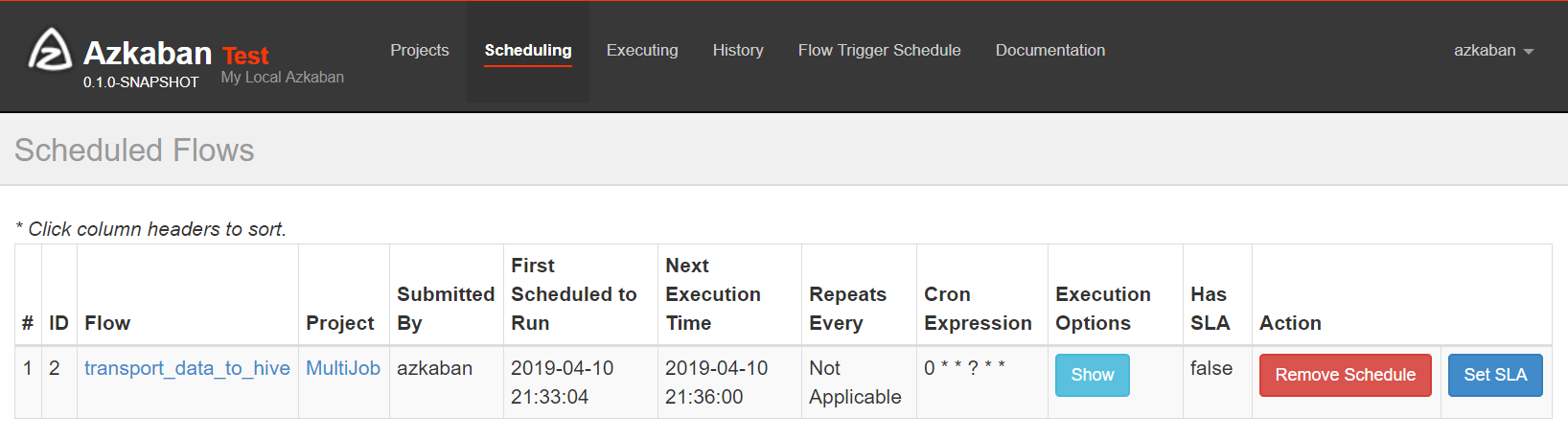
可以查看下次执行时间。
问题
1. Azkaban 执行 Flow 一直处于 Preparing 状态,无法正常执行
修改 web-server conf/azkaban.properties 配置
# execute 主机过滤器配置, 去掉 MinimumFreeMemory
# MinimumFreeMemory 过滤器会检查 executor 主机空余内存是否会大于 6G,如果不足 6G,则 web-server 不会将任务交由该主机执行
azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
分布式计算(五)Azkaban使用的更多相关文章
- 分布式计算(三)Azkaban介绍
转载自:Azkaban学习之路 (一)Azkaban的基础介绍 目录 一.为什么需要工作流调度器 二.工作流调度实现方式 三.常见工作流调度系统 四.各种调度工具对比 五.Azkaban 与 Oozi ...
- Azkaban2.5安装部署(系统时区设置 + 安装和配置mysql + Azkaban Web Server 安装 + Azkaban Executor Server安装 + Azkaban web server插件安装 + Azkaban Executor Server 插件安装)(博主推荐)(五)
Azkaban是什么?(一) Azkaban的功能特点(二) Azkaban的架构(三) Hadoop工作流引擎之Azkaban与Oozie对比(四) 不多说,直接上干货! http://www.cn ...
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
大数据时代之hadoop(一):hadoop安装 大数据时代之hadoop(二):hadoop脚本解析 大数据时代之hadoop(三):hadoop数据流(生命周期) 大数据时代之hadoop(四): ...
- 分布式计算(四)Azkaban安装
Azkaban是一个批量工作流任务调度器,使用Java语言开发.用于在一个工作流内以一个特定的顺序运行一组工作和流程.Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web ...
- apache ignite系列(五):分布式计算
ignite分布式计算 在ignite中,有传统的MapReduce模型的分布式计算,也有基于分布式存储的并置计算,当数据分散到不同的节点上时,根据提供的并置键,计算会传播到数据所在的节点进行计算,再 ...
- Azkaban 2.5.0 job type 插件安装
一.环境及软件 安装环境: 安装目录: /usr/local/ae/ankaban Hadoop 安装目录 export HADOOP_HOME=/usr/local/ae/hadoop-1.2.1 ...
- Azkaban 2.5.0 搭建
一.前言 最近试着参照官方文档搭建 Azkaban,发现文档很多地方有坑,所以在此记录一下. 二.环境及软件 安装环境: 系统环境: ubuntu-12.04.2-server-amd64 安装目录: ...
- 大数据基础知识:分布式计算、服务器集群[zz]
大数据中的数据量非常巨大,达到了PB级别.而且这庞大的数据之中,不仅仅包括结构化数据(如数字.符号等数据),还包括非结构化数据(如文本.图像.声音.视频等数据).这使得大数据的存储,管理和处理很难利用 ...
- Google的PageRank及其Map-reduce应用(日志五)
上一篇:Hadoop的安装(日志四) 1,算法的原理解释: 如下图所示,G就是传说中的谷歌矩阵,这个矩阵是n*n型号的,n表示共计有n个网页. 如矩阵中所示: 11位置处的元素,是表示第一个网页指向的 ...
随机推荐
- 【IDEA&&Eclipse】5、IntelliJ IDEA常见配置
[idea配置jdk] http://blog.csdn.net/tolcf/article/details/50803414 [idea intellij 如何配置tomcat]http://jin ...
- Java面试总结(集合、spring)
Java 集合框架简介 Java Collections Framework,最开始也是一个开源框架,后来被收录到JDK中 所谓的集合,就是能存放多个数据元素的容器,在Java中原生的容器是数组 数组 ...
- 微信服务号 redirect_uri域名与后台配置不一致,错误代码10003
微信服务号开发获取用户openid时一直提示 redirect_uri域名与后台配置不一致,错误代码10003:后台也配置了域名 原因: 结果:获取到了openid
- Jquery插件开发之图片放大镜效果(仿淘宝)
原网转载地址:http://www.cnblogs.com/hnvvv/archive/2011/11/19/2255197.html 需求:公司某个网站,需要实现图片预览效果,并能像淘宝一样实现局部 ...
- 2018-01-11 Antlr4实现数学四则运算
中文编程知乎专栏原文地址 基本参考https://pragprog.com/book/tpantlr2/the-definitive-antlr-4-reference 一书"Buildin ...
- 2017-07-20 在Maven Central发布中文API的Java库
知乎原链 相关问题: 哪些Java库有中文命名的API? 且记下随想. 之前没有发布过, 看了SO上的推荐:Publish a library to maven repositories 决定在son ...
- 一些关于Viewport与device-width的东西~(转)
内容转自 http://www.cnblogs.com/koukouyifan/p/4066567.html 非常感谢 口口一凡 为我们提供的这篇文章,受益匪浅,特地转到自己的博客收藏起来. 以下是原 ...
- typedef struct LNode命名结构指针(线性表的链式存储)
一.typedef 关键字 1. 简介: typedef工具是一个高级数据特性,利用typedef可以为某一些类型自定义名称. 2. 工作原理: 例如我们定义链表的存储结构时,需要定义结点的存储数据元 ...
- Java并发编程(六)volatile关键字解析
由于volatile关键字是与Java的内存模型有关的,因此在讲述volatile关键之前,我们先来了解一下与内存模型相关的概念和知识. 一.内存模型的相关概念 Java内存模型规定所有的变量都是存在 ...
- 软件工程-CMM与CMMI
CMM CMMI