洗礼灵魂,修炼python(19)--文件I/O操作,linecache,fileinput模块
文件I/O操作
1.什么是文件I/O操作
首先I/O(input/output),即输入/输出端口,然后文件,大家应该都是是什么,一个数据,一个txt或者html文档就是一个文件。文件操作就是对文件进行读写删除等的操作。文件I/O操作,个人理解,就是与用户有交互式的文件操作,换句话就是读写操作
文件也是一个可迭代对象
2.有哪些操作:
1):I/O操作:raw_input函数,input函数即可以进行I/O操作,也就是前面说的让代码活起来,这里不再赘述
2):文件操作:
打开关闭文件:
- 打开文件:
- open/with open/file
- f=open('c:/xxx.txt')
- f=file('c:/xxx.txt')(这个写法是python2特有,和open一样的)
- with open('c:/xxx.txt') as f:suite
- 关闭文件:close(),如果使用with则不必考虑文件关闭问题,会自动关闭文件
读写操作:
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ |
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
| xb |
以可写入的二进制形式打开 |
x,w都是可写入模式,X是如果路径下存在同名文件则抛出异常,但是w不管存在否,不存在则新建,存在则覆盖
当文件对象创建成功后,会自带一些文件属性:
f.fileno():文件描述符,描述文件大小
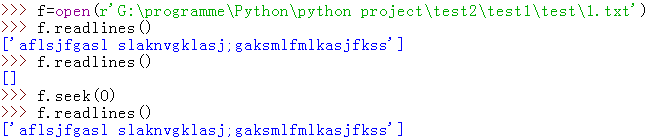
f.readlines():以列表形式返回所有行,每一行作为列表元素,包括行结束符(换行符\n等)
f.readline():每一次只返回一行,包括行结束符
f.next():以迭代的方式,不会移动文件指针
f.tell():返回当前指针在文件中的位置,换句话就是告诉你文件内的当前位置
f.name:属性,不为方法,不加括号,读取文件名字【什么是属性,个人理解,即不能加括号来实例化后进行调用的方法】
f.flush():将缓冲区的进程结束,内容保存到文件里
f.xreadlines():比readlines更高效的方法,但已废弃
f.isatty():判断该文件是否为终端设备文件,返回一个bool值
f.truncate(size):窃取文件,内容并只保存size个字节
f.closed :属性,不加括号,判断文件是否已关闭,返回bool
f.mode :属性,获取当前文件的打开方式
f.newlines:属性,本身为换行符,行结束符字符串,如果没有读取到则返回none
f.softspace:属性,软空间,0表示输出一段数据后加入一个空格,1表示不加
f.seek(offset[, whence]):重新定位指针位置(指针这个概念很重要,很多语言都有,自行体会)
offset -- 开始的偏移量,也就是代表需要移动偏移的字节数
whence:可选,默认值为 0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起
w:就是在指针指向文件内容开头位置写入
a:就是在指针指向文件内容结尾写入
以上的属性可以赋值
读取返回出文件内容:
使用迭代法:
for I in f: #这里直接迭代文件,效率更高,不用使用list转化为列表在迭代,并且效率不高 pirnt (i)
注意:
读取文件:
f=open('python.txt')
for i in f:
print(i)
此时迭代时f不加.read()则是一行一行输出,迭代时f加.read()则是一个字符逐个输出,这一点很重要
linecache
1.作用
linecache模块允许从任何文件里得到任何的行,并且使用缓存进行优化,常见的情况是从单个文件读取多行
此模块使用内存来缓存文件内容,这是需要耗费内存的,打开文件的大小和速度和电脑的内存大小有关系
2.函数:

常用函数:
linecache.checkcache(filename):检查缓存的有效性。如果在缓存中的文件在硬盘上发生了变化,并且你需要更新版本,使用这个函数。如果省略filename,将检查缓存里的所有条目。
linecache.clearcache():清除缓存。如果你不再需要先前从getline()中得到的行。读取文件之后,如果不需要使用文件的缓存时,需要在最后清理一下缓存,使linecache.clearcache()清理缓存,释放缓存。
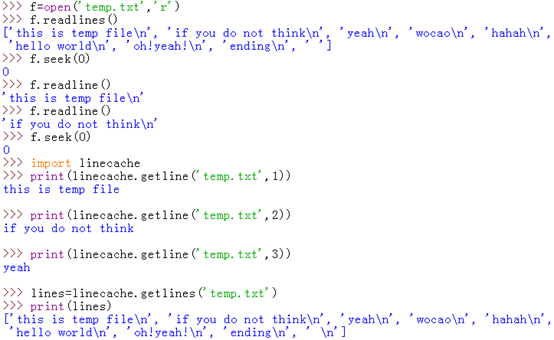
linecache.getline(filename,lineno):从名为filename的文件中得到第lineno行。这个函数从不会抛出一个异常–产生错误时它将返回”(换行符将包含在找到的行里)。如果文件没有找到,这个函数将会在sys.path搜索。
linecache.getlines(filename):从名为filename的文件中得到全部内容,输出为列表格式,以文件每行为列表中的一个元素,并以linenum-1为元素在列表中的位置存储
linecache.updatecache(filename):更新文件名为filename的缓存。如果filename文件更新了,使用这个函数可以更新linecache.getlines(filename)返回的列表。
注意:使用linecache.getlines('XXX.txt')打开文件的内容之后,如果XXX.txt文件发生改变,当再次用linecache.getlines获取的内容并不是文件的已改变的内容,还是之前的内容,此时有两种方法:
- 使用linecache.checkcache(filename)来更新文件在硬盘上的缓存,然后在执行linecache.getlines('XXX.txt')就可以获取到XXX.txt的最新内容;
- 直接使用linecache.updatecache('XXX.txt'),即可获取最新的a.txt的罪行内容
其实linecache模块和文件操作很像对不?确实有点像,功能也差不多,用时自行选择:
fileinput
因为这个模块用得不是很多,基础概念已经有网友总结的很好了,所以下面部分内容我直接转载别人的,原帖:Python中fileinput模块介绍
1.作用:
fileinput模块可以对一个或多个文件中的内容进行迭代、遍历等操作。该模块的input()函数有点类似文件readlines()方法,区别在于前者是一个迭代对象,需要用for循环迭代,后者是一次性读取所有行。
用fileinput对文件进行循环遍历,格式化输出,查找、替换等操作,非常方便
2.函数:

fileinput.input() #返回能够用于for循环遍历的对象
fileinput.input (files=None, inplace=False, backup='', bufsize=0, mode='r', openhook=None)
files:文件的路径列表,默认是stdin方式,多文件['1.txt','2.txt',...]inplace:是否将标准输出的结果写回文件,默认不取代backup:备份文件的扩展名,只指定扩展名,如.bak。如果该文件的备份文件已存在,则会自动覆盖。bufsize:缓冲区大小,默认为0,如果文件很大,可以修改此参数,一般默认即可mode:读写模式,默认为只读openhook:该钩子用于控制打开的所有文件,比如说编码方式等
fileinput.filename() #返回当前文件的名称
fileinput.lineno() #返回当前已经读取的行的数量(或者序号)
fileinput.filelineno() #返回当前读取的行的行号
fileinput.isfirstline() #检查当前行是否是文件的第一行
fileinput.isstdin() #判断最后一行是否从stdin中读取
fileinput.close() #关闭队列
(以下则为本人原创总结)

文件替换操作时,是可以实现,但是会修改源文件格式,添加字符串符号,换行符等的,排列也有问题,源文件留下,更改文件放在其后:
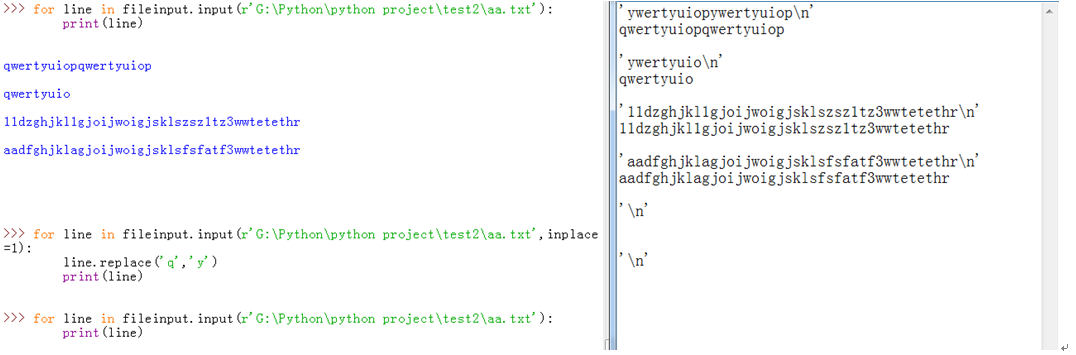
有点问题是不?别着急,我们进行测试一下:
fileinput(filename,inplace=0)中,先看inplace的作用:(不给出inplace则默认为0)

上面的replace是字符串的替换方法,如果没给出inplace则只是输出,但不会修改源文件
当inplace=1时:

当同样的操作,给出input为1之后,源文件发生改变,而带有backup=’bak’时,源文件修改的同时会备份源文件并在原来基础上加上backup参数的后缀,换句话就是备份一个源文件,然后再在源文件上修改。这样的操作在编程开发时是很需要的
看出什么没?是的,可以看出:如果不加inplace, 即默认为0,inplace=0则对比输出,不会修改源文件的;当inplace=1时不输出,修改源文件
以上的都是围绕I/O文件操作,多练习,多总结
洗礼灵魂,修炼python(19)--文件I/O操作,linecache,fileinput模块的更多相关文章
- Python之文件与目录操作及压缩模块(os、shutil、zipfile、tarfile)
Python中可以用于对文件和目录进行操作的内置模块包括: 模块/函数名称 功能描述 open()函数 文件读取或写入 os.path模块 文件路径操作 os模块 文件和目录简单操作 zipfile模 ...
- python 关于文件夹的操作
在python中,文件夹的操作主要是利用os模块来实现的, 其中关于文件夹的方法为:os.lister() , os.path.join() , os.path.isdir() # path 表示文 ...
- 【转】Python之文件与目录操作(os、zipfile、tarfile、shutil)
[转]Python之文件与目录操作(os.zipfile.tarfile.shutil) Python中可以用于对文件和目录进行操作的内置模块包括: 模块/函数名称 功能描述 open()函数 文件读 ...
- Python之文件与目录操作(os、zipfile、tarfile、shutil)
Python中可以用于对文件和目录进行操作的内置模块包括: 模块/函数名称 功能描述 open()函数 文件读取或写入 os.path模块 文件路径操作 os模块 文件和目录简单操作 zipfile模 ...
- python中文件的基础操作
打开文件的三种方式: open(r'E:\学习日记\python\code\文件的简单操作.py') open('E:\\学习日记\\python\\code\\文件的简单操作.py') open(' ...
- 洗礼灵魂,修炼python(17)--跨平台操作三剑客—os,os.path.sys模块
os 1.作用: 因为客户基本都是使用不同的操作系统,在不同的系统下,要完成一个项目,那必须跨平台操作,而python本来就是一个跨平台的语言,而有了os模块,则不需要在意什么系统.并且os模块是用于 ...
- Python之文件和目录操作
1.文件基本操作 python内置了打开文件的函数open(),使用规则如下: File_object=open(filename[,access_mode][,buffering]) Filen ...
- python 中文件夹的操作
文件有两个管家属性:路径和文件名. 路径指明了文件在磁盘的位置,文件名原点的后面部分称为扩展名(后缀),它指明了文件的类型. 一:文件夹操作 Python中os 模块可以处理文件夹 1,当前工作目录 ...
- Python中文件路径名的操作
1 文件路径名操作 对于文件路径名的操作在编程中是必不可少的,比如说,有时候要列举一个路径下的文件,那么首先就要获取一个路径,再就是路径名的一个拼接问题,通过字符串的拼接就可以得到一个路径名.Pyth ...
- Python对文件的读写操作
Python使用open函数来读写文件,open函数的第一个参数是文件名,第二个参数是可选的,有4种常见模式:(1)r 打开一个文件来读数据,这是默认模式:(2)w 打开一个文件来写数据,如果文件已有 ...
随机推荐
- Python函数学习——初步认识
函数使用背景 假设老板让你写一个监控程序,24小时全年无休的监控你们公司网站服务器的系统状况, 当cpu\memory\disk等指标的使用量超过阀值时即发邮件报警, 你掏空了所有的知识量,写出了以下 ...
- centos下如何使用sendmail发送邮件
最近在实施服务端日志监控脚本,需要对异常情况发送邮件通知相关责任人,记录下centos通过sendmail发送邮件的配置过程. 一.安装sendmail与mail 1.安装sendmail: 1) ...
- dart之旅(二)- 内建类型
目录 number 类型 字符串 布尔类型 像大多数语言一样,dart 也提供了 number,string,boolean 等类型,包括以下几种: numbers strings booleans ...
- MVC5笔记
创建一个MVC网站后,我们可以在/app_strat/routeConfig.cs中来查看集中控制路的方法,RegisterRoutes方法(注册路由),我们改一下,删除默认的RegisterRout ...
- nmcli工具详解
目录 1. nmcli 安装 2. nmcli 基本选项 3. general 常规选项 3.1 status 3.2 hostname 3.3 permissions 3.4 loggin 4. n ...
- Spring Boot + Spring Cloud 实现权限管理系统 后端篇(十九):服务消费(Ribbon、Feign)
技术背景 上一篇教程中,我们利用Consul注册中心,实现了服务的注册和发现功能,这一篇我们来聊聊服务的调用.单体应用中,代码可以直接依赖,在代码中直接调用即可,但在微服务架构是分布式架构,服务都运行 ...
- FC游戏 《三国志2-霸王的大陆》攻略
<三国志2-霸王的大陆>是日本南梦宫公司研发的一款历史战略模拟游戏,于1992年06月10日在红白机平台上发行. 在开始游戏选择君主时(一定要在君主未出现前的画面时进行第二步),按住1P的 ...
- JS nodeList转数组,兼容IE低版本
一.前言 nodeList转数组貌似很少会这样去操作,但我在做图片懒加载时,我获取了所有需要做懒加载的img元素,也就是一个NodeList对象,打个比方: 对这些元素进行src修改后,我想将此项从N ...
- Docker系列之Docker镜像(读书笔记)
一.基本概念 Docker包括三个基本概念镜像.容器.仓库. Docker镜像:就是一个只读的模板.例如:一个镜像可以包含一个完整的ubuntu操作系统环境,里面仅安装了Apache或其他应用程序.用 ...
- SPI OLED 驱动
根据之前说过的 SPI 驱动的框架,在我们添加 SPI 设备驱动的时候需要与 SPI Master 完成匹配,通过 spi_register_board_info 进行注册. 构造设备 static ...