关于MySQL checkpoint
Ⅰ、Checkpoint
1.1 checkpoint的作用
- 缩短数据库的恢复时间
- 缓冲池不够用时,将脏页刷到磁盘
- 重做日志不可用时,刷新脏页
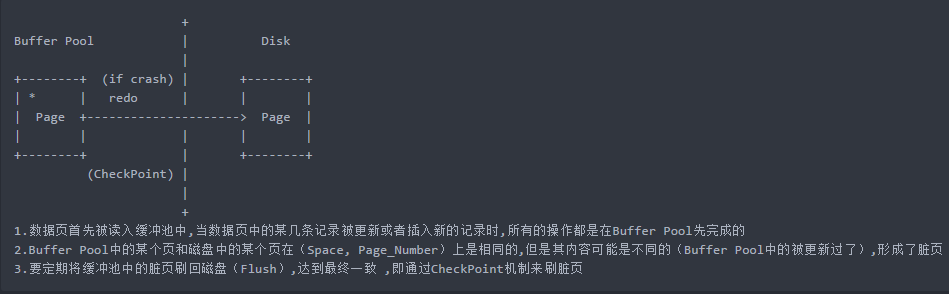
1.2 展开分析
page被缓存在bp中,page在bp中和disk中不是时刻保持一致的(page修改一下就刷一次盘是不现实的,是通过checkpoint来玩的)
万一宕机,重启的时候disk上那个page需要恢复到原来bp中page的那个版本
那问题是,两个page版本不一致咋整?没事,我们做到最终一致就行
那我们就说一下这个最终一致是个怎样的过程,通过一个例子来说明:
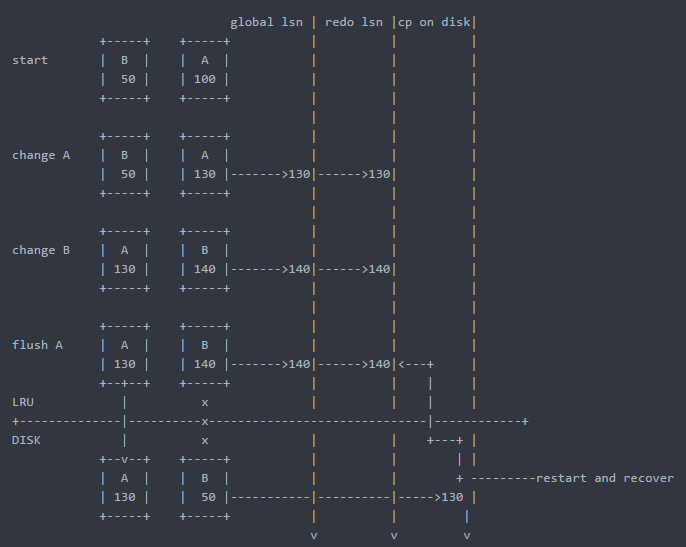
Step1:
一个page读到bp中时,它的lsn(这个鬼东西待会儿仔细说,先理解为一个flag)是100,然后这个page被modify了,它的lsn变成了130,当对应的事务提交后,修改日志会被记录到redo里面,此时redo和全局的lsn就相应的变成了130
Step2:
另外一个page之前进bp的时候lsn是50,前面那个page被modify之后,它也被修改,它的lsn变成了140,它这个140的lsn也写到了redo里,全局lsn变成140
Step3:
关键的一步,假设此时lsn为130的page被刷到disk上了(什么时候刷也是个学问,这里不说),而lsn为140的那个page还没被刷,磁盘上保存的还是老版本,突然宕机了。
Step4:
这时候restart数据库,就会从磁盘上cp的位置(130)开始读redo log,一直回放到140,这样没被刷到磁盘的那个page就恢复到宕机之前的状态了。划重点:
①这个130,140其实就是字节数,也就是说你对这个页修改产生了10个字节的日志,那么lsn就加10
②page原来读进bp的lsn甭管,只管它改变了多少字节就行,所以这个lsn的变化肯定是一个单调递增的过程,其实lsn就是日志写了多少字节(之前没理解好,以为各个page的lsn是自己玩自己的)
Ⅱ、LSN(log sequence number)——日志序列号
lsn是用来保存checkpoint的,保存现在刷新到磁盘的位置在哪里
这个130,140其实就是字节数,也就是说你对这个页修改产生了10个字节的日志,那么lsn就加10,lsn没有上限,8字节
2.1 lsn存在什么地方?
- 每个page有一个LSN,page更新一下LSN就会更新一下,记录在page header中
- 整个MySQL实例也有一个LSN(这就是checkpoint),记录在第一个重做日志的前2k的块里(就给它用,不会被覆盖)
- redo log里有一个LSN
全局lsn位置之前的内容已经刷磁盘上,只要恢复它后面的日志,数据就恢复了
2.2 查看lsn和整个checkpoint流程梳理
看page中的lsn,page中其实是保存两个lsn的,如下:
(root@172.16.0.10) [(none)]> desc information_schema.INNODB_BUFFER_PAGE_LRU;
+---------------------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------------+---------------------+------+-----+---------+-------+
| POOL_ID | bigint(21) unsigned | NO | | 0 | |
| LRU_POSITION | bigint(21) unsigned | NO | | 0 | |
| SPACE | bigint(21) unsigned | NO | | 0 | |
| PAGE_NUMBER | bigint(21) unsigned | NO | | 0 | |
| PAGE_TYPE | varchar(64) | YES | | NULL | |
| FLUSH_TYPE | bigint(21) unsigned | NO | | 0 | |
| FIX_COUNT | bigint(21) unsigned | NO | | 0 | |
| IS_HASHED | varchar(3) | YES | | NULL | |
| NEWEST_MODIFICATION | bigint(21) unsigned | NO | | 0 | |
| OLDEST_MODIFICATION | bigint(21) unsigned | NO | | 0 | |
| ACCESS_TIME | bigint(21) unsigned | NO | | 0 | |
| TABLE_NAME | varchar(1024) | YES | | NULL | |
| INDEX_NAME | varchar(1024) | YES | | NULL | |
| NUMBER_RECORDS | bigint(21) unsigned | NO | | 0 | |
| DATA_SIZE | bigint(21) unsigned | NO | | 0 | |
| COMPRESSED_SIZE | bigint(21) unsigned | NO | | 0 | |
| COMPRESSED | varchar(3) | YES | | NULL | |
| IO_FIX | varchar(64) | YES | | NULL | |
| IS_OLD | varchar(3) | YES | | NULL | |
| FREE_PAGE_CLOCK | bigint(21) unsigned | NO | | 0 | |
+---------------------+---------------------+------+-----+---------+-------+
20 rows in set (0.00 sec)
newest_modification 页最新更新完后的lsn
oldest_modification 页第一次更新完后的lsn
page刷到磁盘的时候,全局的check_point保存的是oldest(只保存第一次修改时的lsn),而page中的lsn保存的是newest
(root@172.16.0.10) [(none)]> show engine innodb status\G
...
---
LOG
---
Log sequence number 15151135824 当前内存中最新的LSN
Log flushed up to 15151135824 redo刷到磁盘的LSN
Pages flushed up to 15151135824 最后一个刷到磁盘上的页的最新的LSN(NEWEST_MODIFICATION)
Last checkpoint at 15151135815 最后一个刷到磁盘上的页的第一次被修改时的LSN(OLDEST_MODIFICATION)
...
Log sequence number和Log flushed up这两个LSN可能会不同,运行过程中后者可能会小于 前者,因为redo日志也是先在内存中更新,再刷到磁盘的
最后一个小于前面三个,为什么?脏页会被指向flush list这个就不多赘述了
flush list是根据lsn进行组织的,而且还是用一个page第一次放进来的lsn进行组织的,也就是说这个page再次发生更新,它的位置是不会移动的
分析一波:
bp的LRU列表中,一个page,假设LSN进来的时候是100,当前全局LSN也是100,如果这个page变化了,产生了20字节的日志,这时候page的lsn变成120,并且通过指针指向flush list中去了,但是这个page立马又被更新产生20字节日志,此时page的lsn为140,而此时在flush list中的lsn还是120(这里意思就是page里面保存了两种lsn,一个是第一次修改页的,一个是最后一次修改页的)
当这个lsn为120的page被刷到disk上,那么disk上的cp就是120了,但是上面的三个值都是140,是不是很好理解呢,那就是说,每个page只更新一次,那这四个值就相等了呗,23333!
为什么这么设计?
为了恢复的时候,保证redo回放的过程的连续性,不会出错
page A第一次修改后lsn是120,记录到全局lsn,后面还有个page B被更新,lsn变为140,此时,page A再更新,lsn变为160了。这时候发生宕机,page A被刷到磁盘,page B没刷过去,如果flush list里面记录160的话,发生故障重启时lsn为140的page B怎么恢复?是不是被跳过去了
那从120开始恢复,那个页已经是160了,为什么还要恢复?
数据库会检测,如果page的lsn大于实例的lsn,就不会恢复这个page,跨过去,只将page B从120恢复到140
tips:
①checkpoint不需要实时刷新到磁盘,不是一个页更新了就要更新磁盘上的cp,磁盘上的cp前置一点是没有关系的,大不了多scan一点redo log,读到不回放就是了,而是由master_thread控制,差不多每秒钟更新一次
②回滚问题
回滚不是通过redo来回滚的,所有的page前滚到一个位置(恢复完),这些page对应的事务还是活跃的,还没提交,之后这些事务都会通过undo log来undo回滚,但undo是通过redo来恢复的
比如一个页120-160已经恢复过去了,但是这个事务需要回滚,却又已经刷到磁盘了,没关系,通过undo log往回滚一下就好了
事务活跃列表存放在undo段中,只要事务没提交就在里面,提交后移动到undo的history中,这个历史列表是用来做purge的,这里面的undo会被慢慢回收
Ⅲ、checkpoint 分类
- Sharp Checkpoint
将所有的赃页都刷新回磁盘,刷新时系统hang住,InnoDB关闭时使用
相关参数:innodb_fast_shutdown={1|0} - Fuzzy Checkpoint
将部分脏页刷新回磁盘,对系统影响较小
innodb_io_capacity来控制,最小限制为100,表示一次最多刷新脏页的能力,与IOPS相关
SSD可以设置在4000-8000,SAS最多设置在800多(IOPS在1000左右)
Ⅳ、什么时候刷dirty page
以前在master thread线程中(从flush_list中进行刷新)
现在都在page_cleaner_thread线程中(每一秒,每十秒)
FLUSH_LRU_LIST 刷新
5.5以前需要保证在LRU_LIST尾部要有100个空闲页(可替换的页),即刷新一部分数据 ,保证有100个空闲页。
由innodb_lru_scan_depth参数来控制,并不只是刷最后一个页,默认探测尾部1024个页(默认),1024个页中所有脏页会一起刷掉,该参数是应用到每个Buffer Pool,总数即为该值乘以Buffer Pool的个数,总量超过innodb_io_capacity是不合理的,即此参数不得超过innodb_io_capacity/innodb_buffer_pool_instances,ssd的话,可以适当把这个扫描深度调深一点
- Async/Sync Flush Checkpoint
重做日志重用 Dirty Page too much
赃页比例超过bp总量的一定比例,本来是通过page_cleaner_thread来刷,但是脏页太多了,就会强行刷,由innodb_max_dirty_pages_pct参数控制
tips:
①页只会从flush_list中刷新这个观点是不对的,只有page_cleaner_thread定期问flush_list要脏页,一个一个刷,刷到innodb_io_capacity的比例值
②LRU list中既存在干净的页也存在脏页,假设最后一个页,是脏的,另一个线程需要一个页,free list已经空了,lru会把这个页淘汰给这个线程去使用,这时候也需要刷新这个脏页,默认一下探测1024个page,把脏页刷掉
关于MySQL checkpoint的更多相关文章
- MySQL checkpoint深入分析
1.日常关注点的问题 2.日志点分析 3.checkpoint:脏页刷盘的检查点 4.模糊检查点发生条件 1.master thread checkpoint 2.flush_lru_list che ...
- 【mysql】关于checkpoint机制
一.简介 思考一下这个场景:如果重做日志可以无限地增大,同时缓冲池也足够大,那么是不需要将缓冲池中页的新版本刷新回磁盘.因为当发生宕机时,完全可以通过重做日志来恢复整个数据库系统中的数据到宕机发生的时 ...
- Mysql怎么判断繁忙 checkpoint机制 innodb的主要参数
Mysql怎么判断繁忙,innodb的主要参数,checkpoint机制,show engine innodb status 2018年07月13日 15:45:36 anzhen0429 阅读数 ...
- MySQL中Checkpoint技术
个人读书笔记,详情参考<MySQL技术内幕 Innodb存储引擎> 1,checkpoint产生的背景数据库在发生增删查改操作的时候,都是先在buffer pool中完成的,为了提高事物操 ...
- mysql 原理 ~ checkpoint
一 简介:今天咱们来聊聊checkpoint 二 定义: checkpoin是重做日志对数据页刷新到磁盘的操作做的检查点,通过LSN号保存记录,作用是当发生宕机等crash情况时,再次启动时会查询ch ...
- MySQL中InnoDB脏页刷新机制Checkpoint
我们知道InnoDB采用Write Ahead Log策略来防止宕机数据丢失,即事务提交时,先写重做日志,再修改内存数据页,这样就产生了脏页.既然有重做日志保证数据持久性,查询时也可以直接从缓冲池页中 ...
- mysql事务、redo日志、undo日志、checkpoint详解
转载: https://zhuanlan.zhihu.com/p/34650908 事务: 说起mysql innodb存储引擎的事务,首先想到就是ACID(不知道的请google),数据库是如何做到 ...
- 携程二面:讲讲 MySQL 中的 WAL 策略和 CheckPoint 技术
前段时间我在准备暑期实习嘛,这是当时面携程的时候二面的一道问题,我一脸懵逼,赶紧道歉,不好意思不知道没了解过,面试官又解释说 redo log,我寻思着 redo log 我知道啊,WAL 是啥?给面 ...
- flink-----实时项目---day07-----1.Flink的checkpoint原理分析 2. 自定义两阶段提交sink(MySQL) 3 将数据写入Hbase(使用幂等性结合at least Once实现精确一次性语义) 4 ProtoBuf
1.Flink中exactly once实现原理分析 生产者从kafka拉取数据以及消费者往kafka写数据都需要保证exactly once.目前flink中支持exactly once的sourc ...
随机推荐
- HW2018校招研发笔试编程题
1. 数字处理 题目描述:给出一个不多于5位的整数,进行反序处理,要求 (1)求出它是几位数 (2)分别输出每一个数字(空格隔开) (3)按逆序输出各位数字(仅数字间以空格间隔,负号与数字之间不需要间 ...
- 【OSX】解决编译AOSP时需要10.5/10.6 SDK下载
有人遇到的是需要10.6的sdk. 公司网快下载了xcode, 把里面的10.5sdk和10.6sdk拿出来, 一共才一百多兆…… 下载链接: http://pan.baidu.com/s/1gdxG ...
- Apache Flume 1.7.0 源码编译 导入Eclipse
前言 最近看了看Apache Flume,在虚拟机里跑了一下flume + kafka + storm + mysql架构的demo,功能很简单,主要是用flume收集数据源(http上报信息),放入 ...
- Docz 用 MDX 写 React UI 组件文档
Docz 用 MDX 写 React UI 组件文档 前言 为了提升开发效率,创建一套 UI 组件库是一种较为有效的方式之一:可以减少重复工作.提高可复用,所以现在越来越多团队开始创建自己的 UI 组 ...
- ckeditor 在dwz里面使用
在ckeditor的配置的过程中,所有的配置的地方都配置了,但是就是不显示编辑器(编辑器代码如下),很郁闷哦 1 <textarea id="editor1" name=&q ...
- Android中不能在子线程中更新View视图的原因
这是一条规律,很多coder知道,但原因是什么呢? 如下: When a process is created for your application, its main thread is ded ...
- 十大经典排序算法的 JavaScript 实现
计算机领域的都多少掌握一点算法知识,其中排序算法是<数据结构与算法>中最基本的算法之一.排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大 ...
- Django models 常用数据类型
CharField class CharField(max_length=None[, **options]) # 字符串(存储从小到大各种长度) # 如果是巨大的文本类型,可以用 TextField ...
- netty源码解解析(4.0)-5 线程模型-EventExecutorGroup框架
上一章讲了EventExecutorGroup的整体结构和原理,这一章我们来探究一下它的具体实现. EventExecutorGroup和EventExecutor接口 io.netty.util.c ...
- html2canvas脚本实现将html内容转换canvas内容
在开始使用html2canvas之前,有一些关于html2canvas及其一些限制的好处. 介绍 该脚本允许您直接在用户浏览器上截取网页或部分网页的“屏幕截图”.屏幕截图基于DOM,因此它可能不是真实 ...