SQL Server关于WITH CUBE、WITH ROLLUP和GROUPING使用
通过查看sql 2005的帮助文档找到了CUBE 和 ROLLUP 之间的具体区别:
CUBE 生成的结果集显示了所选列中值的所有组合的聚合。
ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
再看看对grouping的解释:
当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。
仅在与包含 CUBE 或 ROLLUP 运算符的 GROUP BY 子句相关联的选择列表中才允许分组。
当看到以上的解释肯定非常的模糊,不知所云和不知道该怎样用,下面通过实例操作来体验一下:
--先建表(dbo.PeopleInfo):
CREATE TABLE [dbo].[PeopleInfo](
[id] [int] IDENTITY(1,1) NOT NULL,
[name] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[numb] [nchar](10) COLLATE Chinese_PRC_CI_AS NOT NULL,
[phone] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[FenShu] [int] NULL
) ON [PRIMARY]
--向表插入数据:
insert into peopleinfo([name],numb,phone,fenshu) values ('李欢','3223','1365255',80)
insert into peopleinfo([name],numb,phone,fenshu) values ('李欢','322123','1',90)
insert into peopleinfo([name],numb,phone,fenshu) values ('李名','3213112352','13152',56)
insert into peopleinfo([name],numb,phone,fenshu) values ('李名','32132312','13342563',60)
insert into peopleinfo([name],numb,phone,fenshu) values ('王华','3223','1365255',80)
--查询出插入的全部数据:
select * from dbo.PeopleInfo
操作一:1、查询所有数据;2、用group by 查询所有数据;3、用with cube。
select * from dbo.PeopleInfo --1, 查询所有数据;
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb --2,用group by 查询所有数据;
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube --3,用with cube。这三种情况的比较这三种情况的比较结果如图:

结果分析:
用第三种(用with cube)为什么会多出来有null的字段值呢?通过分析图上的值得组合会发现是怎么回事儿了,以第三条数据(李欢,null,170)为例:它只是把姓名是【李欢】的分为了一组,而没有考虑【numb】,所以有多出来了第三条数据,也说明了170是怎么来的。其他的也是这样。再回顾一下帮助文档的解释:CUBE 生成的结果集显示了所选列中值的所有组合的聚合, 发现明了了许多。
操作二:1、用with cube;2、用with rollup
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube --用with cube。
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with rollup --用with rollup。
结果分析:
为什么with cube 比 with rollup多出来一部分呢?原来它没有显示,以【numb】分组而不考虑【name】的数据情况。再回顾一下帮助文档的解释:ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合,那这个【某一层次】又是以什么为标准的呢?我的猜想是:距离group up最近的字段必须考虑在分组内。
证明猜想实例:
操作:用两个group up 交换字段位置的sql语句和一个在group up 后面增加一个字段的sql语句进行比较:
SQL语句如下:
select [name],numb from dbo.PeopleInfo group by [name],numb with rollup
select [name],numb from dbo.PeopleInfo group by numb,[name] with rollup
select [name],numb,phone from dbo.PeopleInfo group by [name],numb,phone with rollup

通过结果图的比较发现猜想是正确的。
---------------------------------------------------grouping-------------------------------------------------
现在来看看grouping的实例:
SQL语句看看与with rollup的结合(与with cube的结合是一样的):
select [name],numb,grouping(numb) from dbo.PeopleInfo group by [name],numb with rollup
结果分析:
结合帮助文档的解释:当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。 很容易理解再此就不多解释了。
原文:http://www.2cto.com/database/201304/206327.html
SELECT Groups = CASE WHEN GROUPING(Color) = 0 THEN Groups
WHEN GROUPING(Groups) = 1 THEN '总计'
ELSE ''
END ,
Item = CASE WHEN GROUPING(Color) = 0 THEN Item
WHEN GROUPING(Item) = 1 THEN Groups + ' 合计'
ELSE ''
END ,
Color = CASE WHEN GROUPING(Color) = 0 THEN Color
WHEN GROUPING(Color) = 1 THEN Item + ' 小计'
ELSE ''
END ,
Quantity = SUM(Quantity)
FROM @t
GROUP BY Groups ,
Item ,
Color
WITH ROLLUP
ORDER BY GROUPING(Groups) ,
CASE WHEN GROUPING(Groups) = 0 THEN Groups
END DESC ,
GROUPING(Item) ,
CASE WHEN GROUPING(Item) = 0 THEN Item
END DESC ,
GROUPING(Color) ,
CASE WHEN GROUPING(Color) = 0 THEN Color
END DESC;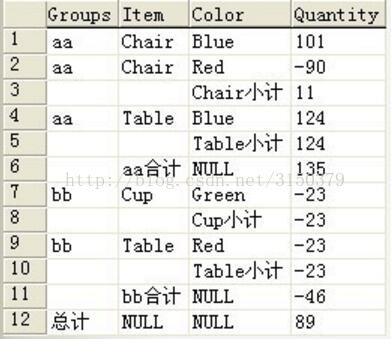
SQL Server关于WITH CUBE、WITH ROLLUP和GROUPING使用的更多相关文章
- CUBE,ROLLUP 和 GROUPING
1.用 CUBE 汇总数据 CUBE 运算符生成的结果集是多维数据集.多维数据集是事实数据的扩展,事实数据即记录个别事件的数据.扩展建立在用户打算分析的列上.这些列被称为维.多维数据集是一个结果集,其 ...
- 我的SQL SERVER数据库会装满吗?
概述 今天有个客户问我一个蛮有意思的问题.我使用的SQL SERVER 2008数据库,目前数据库130多G,其中某个表的记录条数就有3亿1千多万,占用了50多G.那SQL SERVER 数据库中的表 ...
- SQL SERVER:一条SQL语句插入多条记录等
在学习排名第二的mySql过程中,发现它的插入语句可以这样写: use test; create table fruits( fid char(10) not null ,s_id int null ...
- 消息:SQL Server 2017(vNext)的第三个公开的CTP(社区技术预览版)发布了
今天看到了一个新闻,跟大家分享一下,有兴趣的可以去尝试一下. SQL Server 2017 CTP3于5月23日发布了,详细版本号是6.7.55.0. 大家可以去安装试试.在下载页面,目前是SQL ...
- SQL Server 2008 R2 Build List
By Steve Jones, 2014/09/30 (first published: 2010/05/25) This is a list of the builds for SQL Server ...
- SQL Server 之 GROUP BY、GROUPING SETS、ROLLUP、CUBE
1.创建表 Staff CREATE TABLE [dbo].[Staff]( ,) NOT NULL, ) NULL, ) NULL, ) NULL, [Money] [int] NULL, [Cr ...
- SQL Server WITH ROLLUP、WITH CUBE、GROUPING语句的应用
CUBE:CUBE 生成的结果集显示了所选列中值的所有组合的聚合. ROLLUP:ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合. GROUPING:当行由 CUBE 或 ROLLUP ...
- SQL Server ->> GROUPING SETS, CUBE, ROLLUP, GROUPING, GROUPING_ID
在我们制作报表的时候常常需要分组聚合.多组聚合和总合.如果通过另外的T-SQL语句来聚合难免性能太差.如果通过报表工具的聚合功能虽说比使用额外的T-SQL语句性能上要好很多,不过不够干脆,还是需要先生 ...
- 【SQL】面面俱到 | 在SQL中使用CUBE和ROLLUP实现数据多维汇总
偶然在网上看到一篇文章,讲到数据汇总,提到了CUBE,感觉有些晦涩,想试着自己表述一下.同时,个人也认为CUBE还是很有用的,对SQL或数据分析感兴趣的小伙伴不妨了解一下,或许有用呢! 先设定个需求, ...
随机推荐
- Scrum Meeting 5
第五次会议 No_00:工作情况 No_01:任务说明 待完成 已完成 No_10:燃尽图 No_11:照片记录 待更新 No_100:代码/文档签入记录 No_101:出席表 ...
- Linux期末总结
Linux内核学习总结 1.计算机是如何工作的? 存储程序计算机工作模型 X86汇编基础 汇编一个简单的C程序分析其汇编指令执行过程 2.操作系统是如何工作的? 三个法宝——存储程序计算机.函数调用堆 ...
- Linux内核及分析 第八周 进程的切换和系统的一般执行过程
学习笔记: 一.进程调度与进程调度的时机分析 1.不同类型的进程有不同需求的调度需求: 第一种分类: —I/O-bound:频繁的进行I/O,通常会花费很多时间等待I/O操作的完成 —CPU-boun ...
- Liinux 学习心得
Linux 内核学习心得 姬梦馨 原创作品 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 反汇编一个简 ...
- 《Linux内核设计与实现》 第五周 读书笔记(第十八章)
第18章 调试 20135307张嘉琪 18.1 准备开始 18.2 内核中的bug 内核中的bug多种多样,它们的产生可以有无数的原因,同时它们的表象也变化多端,从明白无误的错误代码(比如,没有把正 ...
- 读书笔记(chapter3)
进程管理 3.1进程 1.进程:进程就是处于执行期的程序,实际上,进程就是正在执行的程序代码的实时结果: 2.执行线程,简称线程,是进程中活动的对象(每个线程拥有独立的程序计数器.进程栈.和一组进程寄 ...
- add (db.collection.add)添加数据
db.collection('cheshi').add({ data: { cheshi:4, } }).then((res) => { console.log(res) })
- python删除数组元素导致跳过元素
复现的情况大概可以写成这样 abc = [1, 2, 2, 3, 4] print abc for index, i in enumerate(abc): if i == 2: del abc[ind ...
- BZOJ5306 HAOI2018染色(容斥原理+NTT)
容易想到枚举恰好出现S次的颜色有几种.如果固定至少有i种恰好出现S次,那么方案数是C(M,i)·C(N,i*S)·(M-i)N-i*S·(i*S)!/(S!)i,设为f(i). 于是考虑容斥,可得恰好 ...
- CF-Contest339-614
614A-Link/Cut Tree 比较水,注意64位int仍然可能溢出. #include <cstdio> #include <algorithm> #include & ...