mysql分区方案的研究
笔者觉得,分库分表确实好的。但是,动不动搞分库分表,太麻烦了。分库分表虽然是提高数据库性能的常规办法,但是太麻烦了。所以,尝试研究mysql的分区到底如何。
之前写过一篇文章,http://www.cnblogs.com/wangtao_20/p/7115962.html 讨论过订单表的分库分表,折腾起来工作量挺大的,需要多少技术去折腾。做过的人才知道有多麻烦
要按照什么字段切分,切分数据后,要迁移数据;分库分表后,会涉及到跨库、跨表查询,为了解决查询问题,又得用其他方案来弥补(比如为了应对查询得做用户订单关系索引表)。工作量确实不小。
从网上也可以看到,大部分实施过的人(成功的)的经验总结:水平分表,不是必须的,能不做,尽量不做。
一、探讨分区的原理
了解分区到底在做什么,存储的数据文件有什么变化,这样知道分区是怎么提高性能的。
实际上:每个分区都有自己独立的数据、索引文件的存放目录。本质上,一个分区,实际上对应的是一个磁盘文件。所以分区越多,文件数越多。
现在使用innodb存储较多,mysql默认的存储引擎从mysiam变为了innodb了。
以innodb来讨论:
innodb存储引擎一张表,对应两个文件:表名.ibd、表名.frm。
如果分区后,一个分区就单独一个ibd文件,如下图:
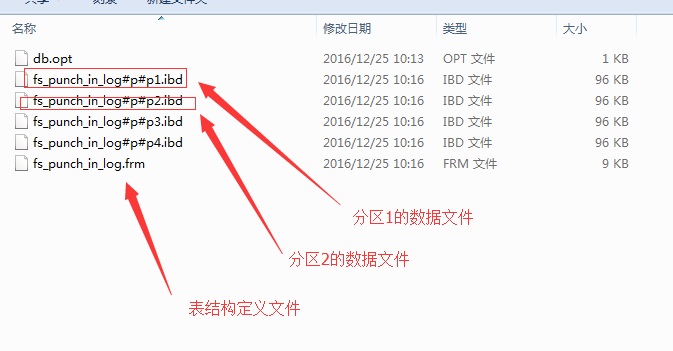
将fs_punch_in_log表拆分成4个分区,上图中看到,每个分区就变成一个单独的数据文件了。mysql会使用"#p#p1"来命名数据文件,1是分区的编号。总共4个分区,最大值是4。
分表的原理,实际上类似,一个表对应一个数据文件。分表后,数据分散到多个文件去了。性能就提高了。
分区后的查询语句
语句还是按照原来的使用。但为了提高性能。还是尽量避免跨越多个分区匹配数据。
如下图,由于表是按照id字段分区的。数据分散在多个分区。现在使用user_id作为条件去查询。mysql不知道到底分配在哪个分区。所以要去全部分区扫描,如果每个分区的数据量大,这样就耗时很长了。
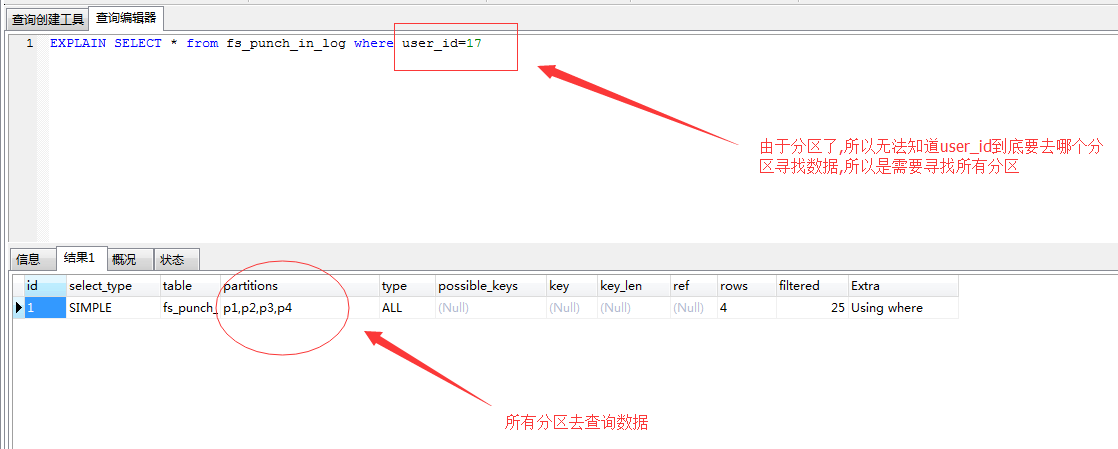
分区思路和分区语句
id字段的值范围来分区:在1-2千万分到p0分区,4千万到-6千万p1分区。6千万到8千万p2分区。依此推算下去。这样可以分成很多的分区了。
为了保持线性扩容方便。那么只能使用range范围来算了。
sql如下
CREATE TABLE `fs_punch_in_log` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键自增' ,
`user_id` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '签到的用户id' ,
`punch_in_time` int(10) UNSIGNED NULL DEFAULT NULL COMMENT '打卡签到时间戳' ,
PRIMARY KEY (`id`)
) partition BY RANGE (id) (
PARTITION p1 VALUES LESS THAN (40000000),
PARTITION p2 VALUES LESS THAN (80000000),
PARTITION p3 VALUES LESS THAN (120000000),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
以上语句经过笔者测验,注意点:
- 按照hash均匀分散。传递给分区的hash()函数的值,必须是一个整数(hash计算整数计算,实现均匀分布)。上面的id字段就是表的主键,满足整数要求。
- partition BY RANGE 中的partition BY表示按什么方式分区。RANGE告诉mysql,我使用范围分区。
情况:如果表结构已经定义好了,里面有数据了,怎么进行分区呢?使用alter语句修改即可,经过笔者测验了。
ALTER TABLE `fs_punch_in_log`
PARTITION BY RANGE (id)
( PARTITION p1 VALUES LESS THAN (40000000),
PARTITION p2 VALUES LESS THAN (80000000),
PARTITION p3 VALUES LESS THAN (120000000),
PARTITION p4 VALUES LESS THAN MAXVALUE )
注:由于表里面已经存在数据了,进行重新分区,mysql会把数据按照分区规则重新移动一次,生成新的文件。如果数据量比较大,耗时间比较长。
二、四种分区类型
mysql分区包括四种分区方式:hash分区、按range分区、按key分区、list分区。
四种有点多,实际上,为了好记,把类再缩小点,就两大类方式进行分区:一种是计算hash值、一种是按照范围值。
其实分库分表的时候,也会用到两大类,hash运算分、按值范围分。
1、HASH分区
有常规hash和线性hash两种方式。
- 常规hash是基于分区个数取模(%)运算。根据余数插入到指定的分区。打算分4个分区,根据id字段来分区。
怎么算出新插入一行数据,需要放到分区1,还是分区4呢? id的值除以4,余下1,这一行数据就分到1分区。
常规hash,可以让数据非常平均的分布每一个分区。比如分为4个取,取余数,余数总是0-3之间的值(总到这几个分区去)。分配打散比较均匀。
但是也是有缺点的:由于分区的规则在创建表的时候已经固定了,数据就已经打散到各个分区。现在如果需要新增分区、减少分区,运算规则变化了,原来已经入库的数据,就需要适应新的运算规则来做迁移。
实际上在分库分表的时候,使用hash方式,也是数据量迁移的问题。不过还好。
针对这个情况,增加了线性hash的方式。
- 线性HASH(LINEAR HASH)稍微不同点。
实际上线性hash算法,就是我们memcache接触到的那种一致性hash算法。使用虚拟节点的方式,解决了上面hash方式分区时,当新增加分区后,涉及到的数据需要大量迁移的问题。也不是不需要迁移,而是需要迁移的数据量小。
在技术实现上:线性哈希功能使用的一个线性的2的幂(powers-of-two)运算法则,而常规哈希使用的是求哈希函数值的模数。
线性哈希分区和常规哈希分区在语法上的唯一区别在于,在“PARTITION BY”子句中添加“LINEAR”关键字。
两者也有有相同的地方:
- 都是均匀分布的,预先指定n个分区,然后均匀网几个分区上面分布数据。根据一个字段值取hash值,这样得到的结果是一个均匀分布的值。后面添加新的分区多少需要考虑数据迁移。
- 常规HASH和线性HASH,因为都是计算整数取余的方式,那么增加和收缩分区后,原来的数据会根据现有的分区数量重新分布。
- HASH分区不能删除分区,所以不能使用DROP PARTITION操作进行分区删除操作;
考虑以后迁移数据量少,使用线性hash。
2、按照range范围分区
范围分区,可以自由指定范围。比如指定1-2000是一个分区,2000到5000千又是一个分区。范围完全可以自己定。后面我要添加新的分区,很容易吗?
3、按key分区
类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
4、按list方式分区
可以把list看成是在range方式的基础上的改进版。list和range本质都是基于范围,自己控制范围。
range是列出范围,比如1-2000范围算一个分区,这样是一个连续的值。
而list分区方式是枚举方式。可以指定在1,5,8,9,20这些值都分在第一个分区。从list单词的字面意思命名暗示就是列表,指定列表中出现的值都分配在第几个分区。
三、如何根据业务选择分区类型
1、何时选择分区,何时选择分表
分表还是比分区更加灵活。在代码中可以自己控制。一般分表会与分库结合起来使用的。在进行分表的时候,顺带连分库方案也一起搞定了。
分表分库,性能和并发能力要比分区要强。分表后,有个麻烦点:自己需要修改代码去不同的表操作数据。
代码很多处要做专门的匹配如下:
非常适合业务刚刚起步的时候,能不能做起来,存活期是多久不知。不用把太多精力花费在分库分表的适应上。
mysql分区方案的研究的更多相关文章
- mysql分区研究
表分区学习 1. 概述 1.1. 优点: l 将表分区比一个表在单个磁盘或者文件系统存储能够存储更多数据 l 可以通过drop分区删除无用数据,也可以通过增加分区添加数据 l 查询可以通过分区裁剪进行 ...
- 由mysql分区想到的分表分库的方案
在分区分库分表前一定要了解分区分库分表的动机. 对实时性要求比较高的场景,使用数据库的分区分表分库. 对实时性要求不高的场景,可以考虑使用索引库(es/solr)或者大数据hadoop平台来解决(如数 ...
- mysql分区
<?php /* 分区 目录 18.1. MySQL中的分区概述 18.2. 分区类型 18.2.1. RANGE分区 18.2.2. LIST分区 18.2.3. HASH分区 18.2.4. ...
- 第18章:MYSQL分区
第18章:分区 目录 18.1. MySQL中的分区概述 18.2. 分区类型 18.2.1. RANGE分区 18.2.2. LIST分区 18.2.3. HASH分区 18.2.4. KEY分区 ...
- ubuntu系统分区方案
一.各文件及文件夹的定义 /bin:bin是binary(二进制)的缩写.存放必要的命令 存放增加的用户程序. /bin分区,存放标准系统实用程序./boot:这里存放的是启动LINUX时使用的一些核 ...
- Mysql 分区详解
详见:http://blog.yemou.net/article/query/info/tytfjhfascvhzxcyt120 一.什么是表分区通俗地讲表分区是将一大表,根据条件分割成若干个小表.m ...
- linux 分区方案
背景 之前安装过linux好多次,也学习过好几次,竟然也是一直没开窍,这次不知为啥醒悟了.了解了linux的分区道道.总结起来就是分区主要是根目录(类似c盘),swap,boot(必须有的, win ...
- mysql 分区说明
当 MySQL的总记录数超过了100万后,性能会大幅下降,可以采用分区方案 分区允许根据指定的规则,跨文件系统分配单个表的多个部分.表的不同部分在不同的位置被存储为单独的表. 1.先看下innodb的 ...
- Ubuntu分区方案归总
更新时间:2010-8-26 一.各文件及文件夹的定义 /bin:bin是binary(二进制)的缩写.存放必要的命令 存放增加的用户程序. /bin分区,存放标准系统实用程序. /boot: ...
随机推荐
- 【Intellij IDEA】eclipse项目导入
intellij idea中文资料网上比较少,对于eclipse的项目如何导入intellij idea也没有完整的说明,本人在这里整理下,方便更多人加入到intellij idea的阵容里. 直接上 ...
- string method and regular expresions
<!doctype html> <!DOCTYPE html> <html> <head> <meta charset="utf-8&q ...
- 2110 ACM Crisis of HDU 母函数
题目:http://acm.hdu.edu.cn/showproblem.php?pid=2110 题意:分出1/3的价值,有几种可能? 思路:母函数 与之前的题目2079相似,复习笔记再来写代码: ...
- 信息系统项目管理师EV、PV、AC、BAC、CV、SV、EAC、ETC、CPI、SPI概念说明
挣值常用名词: AC [Actual Cost] 实际成本:完成工作的实际成本是多少? [96版的ACWP] PV [Planned Value] 计划值: 应该完成多少工作? [96版的BCWS] ...
- Spring 的 AOP 进行事务管理的一些问题
AspectJ AOP事务属性的配置(隔离级别.传播行为等): <tx:advice id="myAdvice" transaction-manager="mtTx ...
- [模板][P3803]多项式乘法
Description: FFT真的容易忘,所以就放到上面来了 #include<bits/stdc++.h> using namespace std; const int mxn=4e6 ...
- python学习—几个简单小程序
1. 输出1到100的偶数 #!/usr/bin/env python # -*- coding:utf-8 -*- #定义初始值 start=1 while True: #判断start的值若其为5 ...
- BZOJ3537 : [Usaco2014 Open]Code Breaking
考虑容斥,枚举哪些串必然出现,那么贡献为$(-1)^{选中的串数}$. 设$f[i][j]$表示$i$的子树内,$i$点往上是$j$这个串的贡献之和,那么总状态数为$O(n+m)$,用map存储$f$ ...
- PAT基础6-10
6-10 阶乘计算升级版 (20 分) 本题要求实现一个打印非负整数阶乘的函数. 函数接口定义: void Print_Factorial ( const int N ); 其中N是用户传入的参数,其 ...
- JAVA自学笔记25
JAVA自学笔记25 1.GUI 1)图形用户接口,以图形的方式,来显示计算机操作的界面,更方便更直观 2)CLI 命令行用户接口,就是常见的Dos,操作不直观 3) 类Dimension 类内封装单 ...