python 之路 day5 - 常用模块
- 模块介绍
- time &datetime模块
- random
- os
- sys
- shutil
- json & picle
- shelve
- xml处理
- yaml处理
- configparser
- hashlib
- subprocess
- logging模块
re正则表达式
一.模块,用一堆代码实现了某个功能的代码集合。
类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合。而对于一个复杂的功能来,可能需要多个函数才能完成(函数又可以在不同的.py文件中),n个 .py 文件组成的代码集合就称为模块。
如:os 是系统相关的模块;file是文件操作相关的模块
模块分为三种:
- 自定义模块
- 内置标准模块(又称标准库)
开源模块
二.time&datetime
import time
print(time.ctime()) #返回Thu Oct 18 10:29:26 2018时间格式
print(time.clock()) #返回处理器时间
print(time.altzone) #返回与UTC的时间差,中国在东八区UTC-8
print(time.asctime()) #返回Thu Oct 18 10:38:18 2018时间
print(time.localtime()) #返回本地时间 的struct time对象格式
print(time.asctime(time.localtime())) #返回Thu Oct 18 10:43:44 2018时间格式
print(time.gmtime(time.time())) #返回UTC时间的struct时间对象格式
print('分割线'.center(50,'-'))
#日期字符串 转成 时间戳
string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式
print(string_2_struct)
struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳
print(struct_2_stamp)
#时间戳转为字符串格式
print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式
print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
import datetime
print(datetime.datetime.now()) #返回2018-10-18 10:51:30.546491
print(datetime.date.fromtimestamp(time.time())) #时间戳转换成当前日期2018-10-18格式
print(datetime.datetime.now() )
print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分pc_time = datetime.datetime
格式对照表
%a 本地(locale)简化星期名称
%A 本地完整星期名称
%b 本地简化月份名称
%B 本地完整月份名称
%c 本地相应的日期和时间表示
%d 一个月中的第几天(01 - 31)
%H 一天中的第几个小时(24小时制,00 - 23)
%I 第几个小时(12小时制,01 - 12)
%j 一年中的第几天(001 - 366)
%m 月份(01 - 12)
%M 分钟数(00 - 59)
%p 本地am或者pm的相应符 一
%S 秒(01 - 61) 二
%U 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 三
%w 一个星期中的第几天(0 - 6,0是星期天) 三
%W 和%U基本相同,不同的是%W以星期一为一个星期的开始。
%x 本地相应日期
%X 本地相应时间
%y 去掉世纪的年份(00 - 99)
%Y 完整的年份%Z 时区的名字(如果不存在为空字符)
时间关系转换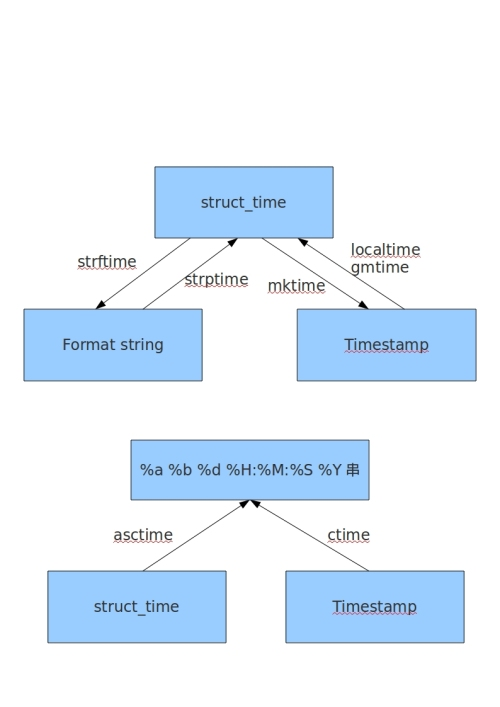
三.random模块
import random
checkcode = ''
for i in range(6):
current = random.randrange(0,6)
if current == i:
temp = chr(random.randint(65,90))
else:
temp = random.randint(0,9)
checkcode+=str(temp)
print(checkcode)
print(random.random()) #随机浮点数(0,1)
print(random.randint(0,9)) #随机整数
print(random.uniform(1,3)) #随机浮点数
print(random.choice([1,2,3])) #从序列类型中取一个元素
print(random.sample([1,2,3],2))#从序列类型中取元素,可以指定长度
a = [1,2,3,4,5]
print(random.shuffle(a))
四.OS模块
print(os.getcwd()) #获取当前工作目录,即当前python脚本工作的目录路径
#os.makedirs(r'D:a\b\c\d') #递归创建文件
#os.removedirs(r'D:a\b\c\d') #递归删除文件夹
print(os.curdir)
print(os.sep) #输出操作系统特定的路径分隔符,win下为"\",Linux下为"//"
print(os.linesep) #输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
print(os.pathsep) #输出用于分割文件路径的字符p
print(os.name) # 输出字符串指示当前使用平台 win->'nt'; Linux->'posix'
print(os.environ) #获取系统的环境变量
a = os.path.abspath(__file__)
print(a)
print(os.path.split(a))#将path分割成目录和文件名二元组返回
print(os.path.dirname(a))
print(os.path.isabs(a)) #如果path是绝对路径,返回True
#详细http://blog.51cto.com/egon09/1840425
五.sys模块
import sys
print(sys.argv) #命令行参数list,第一个元素时程序本身路径
#print(sys.exit(0)) #退出程序
print(sys.version) #获取Python解释程序的版本信息
print(sys.maxsize)
print(sys.path) #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
print(sys.platform) #返回操作系统平台名称
六.shutil模块
import shutil
f1 = open('笔记1',encoding='utf-8')
f2 = open('笔记2','w',encoding='utf-8')
shutil.copyfileobj(f1,f2) #将文件内容拷贝到另一个文件中,可以部分内容
#shutil.copyfile('笔记1','笔记2') #把笔记中的文件复制到笔记1中
#shutil.copymode('笔记1','笔记2') #仅拷贝权限。内容、组、用户均不变
shutil.copystat('笔记1','笔记2') #拷贝状态的信息,包括:mode bits, atime, mtime, flags
#详细http://www.cnblogs.com/wupeiqi/articles/4963027.html
七.json & picle模块
- json,用于字符串 和 python数据类型间进行转换(dump一次load一次)
- pickle,用于python特有的类型 和 python的数据类型间进行转换
pickle(只能在python中用,可以序列化函数,等一些复杂的数据类型,但是不能直接反序列化(如果需要的话要把序列化的函数复制到反序列化的程序中)
json序列化
import json
date = {
'a':123,
'b':456,
'c':789
}
f = open('text.text','w')
f.write(json.dumps(date)) #等价于json.dump(date,f)
f.close()
json反序列化
import json
f = open('text.text','r')
date = json.loads(f.read()) #等价于json.load(f)
print(date['a'])
f.close()
八.shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
import shelve
import datetime
d = shelve.open('abc')
print(d.get('info'))
d.close()
'''
info = {
'name':'eason',
'age' :22
}
d['info']= info
d.close
'''
九.xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
xml文件:
<?xml version="1.0"?><data> <country name="Liechtenstein"> <rank updated="yes">2</rank> <year>2008</year> <gdppc>141100</gdppc> <neighbor name="Austria" direction="E"/> <neighbor name="Switzerland" direction="W"/> </country> <country name="Singapore"> <rank updated="yes">5</rank> <year>2011</year> <gdppc>59900</gdppc> <neighbor name="Malaysia" direction="N"/> </country> <country name="Panama"> <rank updated="yes">69</rank> <year>2011</year> <gdppc>13600</gdppc> <neighbor name="Costa Rica" direction="W"/> <neighbor name="Colombia" direction="E"/> </country></data>读取xml文档:
import xml.etree.ElementTree as TE
tree = TE.parse("xmltext.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(child.tag,child.attrib)
for i in child:
print(i.tag,i.text,i.attrib)
#只遍历year文档
for node in root.iter('year'):
print(node.tag,node.text)
修改和删除xml文档:
import xml.etree.ElementTree as ETtree = ET.parse("xmltest.xml")root = tree.getroot()#修改for node in root.iter('year'): new_year = int(node.text) + 1 node.text = str(new_year) node.set("updated","yes")tree.write("xmltest.xml")#删除nodefor country in root.findall('country'): rank = int(country.find('rank').text) if rank > 50: root.remove(country)tree.write('output.xml')自己创建xml文档:
import xml.etree.ElementTree as ETnew_xml = ET.Element("namelist")name = ET.SubElement(new_xml,"name",attrib={"enrolled":"yes"})age = ET.SubElement(name,"age",attrib={"checked":"no"})sex = ET.SubElement(name,"sex")sex.text = '33'name2 = ET.SubElement(new_xml,"name",attrib={"enrolled":"no"})age = ET.SubElement(name2,"age")age.text = '19'et = ET.ElementTree(new_xml) #生成文档对象et.write("test.xml", encoding="utf-8",xml_declaration=True)ET.dump(new_xml) #打印生成的格式 十.yaml模块
Python也可以很容易的处理ymal文档格式,只不过需要安装一个模块,参考文档:http://pyyaml.org/wiki/PyYAMLDocumentation
十一.configparser模块
用于生成和修改常见配置文档,当前模块的名称在 python 3.x 版本中变更为 configparser。
来看一个好多软件的常见文档格式如下:
[DEFAULT]ServerAliveInterval = 45Compression = yesCompressionLevel = 9ForwardX11 = yes[bitbucket.org]User = hg[topsecret.server.com]Port = 50022ForwardX11 = no用python生成一个这样的文档:
import configparserconfig = configparser.ConfigParser()config["DEFAULT"] = {'ServerAliveInterval': '45', 'Compression': 'yes', 'CompressionLevel': '9'}config['bitbucket.org'] = {}config['bitbucket.org']['User'] = 'hg'config['topsecret.server.com'] = {}topsecret = config['topsecret.server.com']topsecret['Host Port'] = '50022' # mutates the parsertopsecret['ForwardX11'] = 'no' # same hereconfig['DEFAULT']['ForwardX11'] = 'yes'with open('example.ini', 'w') as configfile: config.write(configfile)读取
import configparser
conf = configparser.ConfigParser()
conf.read('example.ini')
print(conf.sections()) #打印节点除了default
print(conf.defaults()) #打印default
print(conf['bitbucket.org'] ['user'])
for key in conf['bitbucket.org']: #循环打印
print(key)
sec = conf.remove_section('bitbucket.org')
conf.write(open('example改写','w'))
十二.hashlib
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密
散列消息鉴别码,简称HMAC,是一种基于消息鉴别码MAC(Message Authentication Code)的鉴别机制。使用HMAC时,消息通讯的双方,通过验证消息中加入的鉴别密钥K来鉴别消息的真伪;
一般用于网络通信中消息加密,前提是双方先要约定好key,就像接头暗号一样,然后消息发送把用key把消息加密,接收方用key + 消息明文再加密,拿加密后的值 跟 发送者的相对比是否相等,这样就能验证消息的真实性,及发送者的合法性了。
import hashlib
m = hashlib.md5()
m.update(b'hello')
print(m.hexdigest()) #加密hello
m.update(b"it's me ")
print(m.hexdigest()) #加密hello+it's me
m2 = hashlib.md5() #验证上面m加密是否是hello+it's me
m2.update("helloit's me 丁".encode(encoding='utf-8')) #如果需要加密中文需要encode,并且不加b
print(m2.hexdigest())
print('分割线'.center(50,'-'))
import hmac #消息加密,速度比较快 #key不能是中文
h = hmac.new(b'eason',"你是250".encode(encoding='utf-8'))
print(h.hexdigest())
十五.re模块
正则表达式
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']'?' 匹配前一个字符1次或0次(如aaa?如果字符串中有aa可以匹配到,)'{m}' 匹配前一个字符m次'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC''(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的'\Z' 匹配字符结尾,同$'\d' 匹配数字0-9'\D' 匹配非数字'\w' 匹配[A-Za-z0-9]'\W' 匹配非[A-Za-z0-9]'s' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t''(?P<name>...)' 分组匹配 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}import re
#re.match()从字符串开头开始匹配
res = re.match('eason\d+','eason123grace321') #d+代表1个或多个数字
print(res.group())
res = re.match('.+','eason123grace321')
print(res.group())
#re.search()从整个文本开始匹配
res = re.search('G.+e','eason123Grace321')
print(res.group())
res = re.search('G.+e$','ason123Grace321e') #$符是匹配字符串结尾的字符
print(res.group())
res = re.search('G[a-zA-Z]+e','eason123GraDce321') #[a-zA-Z]只匹配英文字母包括大小写
print(res.group())
res = re.search('aal?','aalexaaa')
print(res.group())
res = re.search('aa?','aalexaaa')
print(res.group())
res = re.search('[0-9]{3}','a1b34c455') #{m}
print(res.group())
#re.findall()
res = re.findall('[0-9]{1,3}','a1b34c455') #{n,m}
res = re.search('ABC|abc','ABCabcABC').group() #|
print(res)
res = re.search('(abc){2}','aleabcabc').group() #分组
print(res)
res = re.search('\A[0-9]+[a-z]\Z','123a').group() #\A,\Z
print(res)
res = re.search('\D+','124a@').group() #匹配非数字
print(res)
res = re.search('\w+','124a@').group() #匹配非特殊字符
print(res)
res = re.search('\W+','124a@').group() #匹配特殊字符
print(res)
res = re.search('\s+','124a @').group() #匹配空格\n,\r\,t
print(res)
res = re.search('(?P<id>[0-9]+)','adf1234fdg#').groupdict()
print(res)
res = re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{4})",
"374181199306143242").groupdict("city") #抓取身份证号
#结果{'province': '3714', 'city': '81', 'birthday': '1993'}
print(res)
#re.split()分割
res = re.split('[0-9]+','asd1fd4gg4gbg') #将字符串按照其中的数字进行分割变成一个列表
print(res)
#re.sub 替换
res = re.sub('[0-9]+','|','abf13bkk4mkj5ff',count=2)
print(res)
python 之路 day5 - 常用模块的更多相关文章
- Python 之路 Day5 - 常用模块学习
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- Python之路,Day5 - 常用模块学习 (转载Alex)
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- 小白的Python之路 day5 random模块和string模块详解
random模块详解 一.概述 首先我们看到这个单词是随机的意思,他在python中的主要用于一些随机数,或者需要写一些随机数的代码,下面我们就来整理他的一些用法 二.常用方法 1. random.r ...
- 小白的Python之路 day5 shelve模块讲解
shelve模块讲解 一.概述 之前我们说不管是json也好,还是pickle也好,在python3中只能dump一次和load一次,有什么方法可以向dump多少次就dump多少次,并且load不会出 ...
- 小白的Python之路 day5 configparser模块的特点和用法
configparser模块的特点和用法 一.概述 主要用于生成和修改常见配置文件,当前模块的名称在 python 3.x 版本中变更为 configparser.在python2.x版本中为Conf ...
- 小白的Python之路 day5 hashlib模块
hashlib模块 一.概述 用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法 二.算法的演 ...
- 小白的Python之路 day5 logging模块
logging模块的特点及用法 一.概述 很多程序都有记录日志的需求,并且日志中包含的信息即有正常的程序访问日志,还可能有错误.警告等信息输出,python的logging模块提供了标准的日志接口,你 ...
- 小白的Python之路 day5 shutil模块
shutil模块 一.主要用途 高级的文件.文件夹.压缩包 等处理模块 二.常用方法详解 1.shutil.copyfileobj(fsrc, fdst) 功能:把一个文件的内容拷贝到另外一个文件中, ...
- 第六章:Python基础の反射与常用模块解密
本课主题 反射 Mapping 介绍和操作实战 模块介绍和操作实战 random 模块 time 和 datetime 模块 logging 模块 sys 模块 os 模块 hashlib 模块 re ...
随机推荐
- XVIII Open Cup named after E.V. Pankratiev. Grand Prix of Saratov
A. Three Arrays 枚举每个$a_i$,双指针出$b$和$c$的范围,对于$b$中每个预先双指针出$c$的范围,那么对于每个$b$,在对应$c$的区间加$1$,在$a$处区间求和即可. 树 ...
- c#常用数值范围汇总
short.MaxValue 32767 short.MinValue -32768 int.MaxValue 2147483647 int.MinValue -2147483648 long.Max ...
- HTML入门7
这篇来些可能用的比较少的,调试HTML 程序员调试代码常见,遇到问题一切正常,找出问题解决,满足 来了解下HTML调试, 在浏览器解析和显示之前HTML不会被编译成其他形式,只是解析而不是编译因此运行 ...
- js的一些
// 1 定时器参数问题 无限个参数 /*setTimeout(function(num1,num2,num3,num4){ alert(num1+num2+num3+num4) },1000,1,2 ...
- javascript自制函数图像生成器
出于某种目的想做这个东西,顺便可以提供给GMA的用户&&放在博客园. 实现上只是简单的描点,加上一个相邻两点连线的开关,完全没有技术含量.而且函数图像一旦多起来就会变卡. 瓶颈在隐函数 ...
- 动态规划-数位DPwindy
https://vjudge.net/contest/297216?tdsourcetag=s_pctim_aiomsg#problem/L #include<bits/stdc++.h> ...
- java 实现文件上传下载以及查看
项目的目录结构 代码 IOUtils.java package cn.edu.zyt.util; import java.io.IOException; import java.io.InputSt ...
- Ubuntu-1604-LTS在虚拟机设置分辨率
在虚拟机中安装ubuntu系统时,有时系统的界面并不同虚拟机展示的匹配,需要我们进行调整.不用那么多废话,直接看图:
- IIC稳定性.VBS
Sub Main Dim cnt Dim delay Dim time Dim atttime atttime = 20 delay = 3000 time = 50 crt.screen.Send ...
- oo第三次总结
一.(1)规格化设计的大致发展历史 20世纪60年代,随着大容量.高速度的计算机出现,以及大量语言的新增和软件的不可靠,爆发了所谓的“软件危机”.而针对这个问题,人们提出了规格化设计的解决方法.通过把 ...