MySQL在高内存、IO利用率上的几个优化点
以下优化都是基于CentOS系统下的一些MySQL优化整理,有不全或有争议的地方望继续补充完善。
一、mysql层面优化
1. innodb_flush_log_at_trx_commit 设置为2
设置0是事务log(ib_logfile0、ib_logfile1)每秒写入到log buffer,1是时时写,2是先写文件系统的缓存,每秒再刷进磁盘,和0的区别是选2即使mysql崩溃也不会丢数据。
2. innodb_write_io_threads=16(该参数需要在配置文件中添加,重启mysql实例起效)
脏页写的线程数,加大该参数可以提升写入性能.mysql5.5以上才有。
3. innodb_max_dirty_pages_pct 最大脏页百分数
当系统中 脏页 所占百分比超过这个值,INNODB就会进行写操作以把页中的已更新数据写入到磁盘文件中。默认75,一般现在流行的SSD硬盘很难达到这个比例。可依据实际情况在75-80之间调节
4. innodb_io_capacity=5000
从缓冲区刷新脏页时,一次刷新脏页的数量。根据磁盘IOPS的能力一般建议设置如下:
SAS 200
SSD 5000
PCI-E 10000-50000
5. innodb_flush_method=O_DIRECT(该参数需要重启mysql实例起效)
控制innodb数据文件和redo log的打开、刷写模式。有三个值:fdatasync(默认),O_DSYNC,O_DIRECT。
fdatasync模式:写数据时,write这一步并不需要真正写到磁盘才算完成(可能写入到操作系统buffer中就会返回完成),真正完成是flush操作,buffer交给操作系统去flush,并且文件的元数据信息也都需要更新到磁盘。
O_DSYNC模式:写日志操作是在write这步完成,而数据文件的写入是在flush这步通过fsync完成。
O_DIRECT模式:数据文件的写入操作是直接从mysql innodb buffer到磁盘的,并不用通过操作系统的缓冲,而真正的完成也是在flush这步,日志还是要经过OS缓冲。
三种模式如下图:
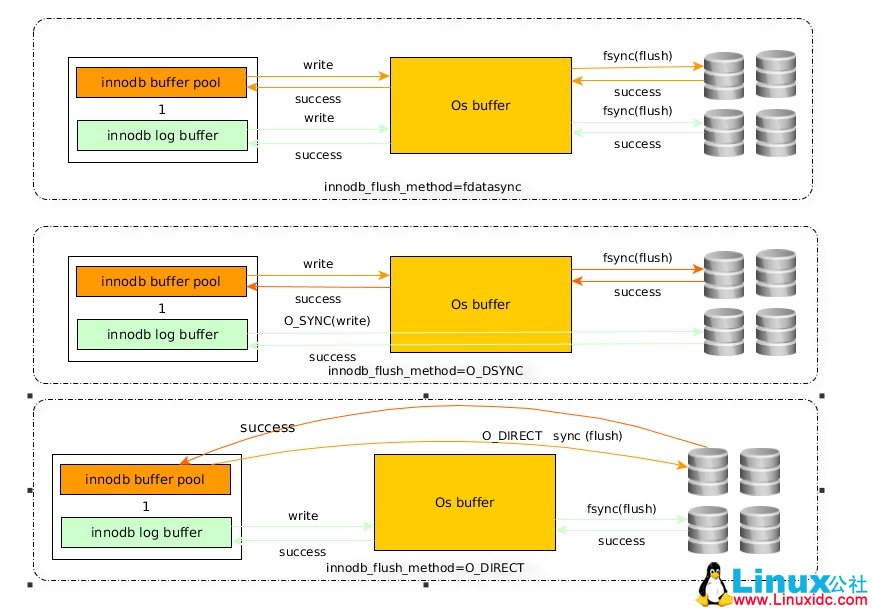
通过图可以看出O_DIRECT相比fdatasync的优点是避免了双缓冲,本身innodb buffer pool就是一个缓冲区,不需要再写入到系统的buffer,但是有个缺点是由于是直接写入到磁盘,所以相比fdatasync的顺序读写的效率要低些。
在大量随机写的环境中O_DIRECT要比fdatasync效率更高些,顺序写多的话,还是默认的fdatasync更高效。
6. innodb_adaptive_flushing 设置为 ON (使刷新脏页更智能)
影响每秒刷新脏页的数目。规则由原来的“大于innodb_max_dirty_pages_pct时刷新100个脏页到磁盘”变为 “通过buf_flush_get_desired_flush_reate函数判断重做日志产生速度确定需要刷新脏页的最合适数目”;即使脏页比例小于 innodb_max_dirty_pages_pct时也会刷新一定量的脏页。
7. innodb_adaptive_flushing_method 设置为 keep_average
影响checkpoint,更平均的计算调整刷脏页的速度,进行必要的flush.(该变量为mysql衍生版本Percona Server下的一个变量,原生mysql不存在)
8. innodb_stats_on_metadata=OFF
关掉一些访问information_schema库下表而产生的索引统计。
当重启mysql实例后,mysql会随机的io取数据遍历所有的表来取样来统计数据,这个实际使用中用的不多,建议关闭.
9. innodb_change_buffering=all
当更新/插入的非聚集索引的数据所对应的页不在内存中时(对非聚集索引的更新操作通常会带来随机IO),会将其放到一个insert buffer中,当随后页面被读到内存中时,会将这些变化的记录merge到页中。当服务器比较空闲时,后台线程也会做merge操作。
由于主要用到merge的优势来降低io,但对于一些场景并不会对固定的数据进行多次修改,此处则并不需要把更新/插入操作开启change_buffering,如果开启只是多余占用了buffer_pool的空间和处理能力。这个参数要依据实际业务环境来配置。
10. innodb_old_blocks_time=1000
使Block在old sublist中停留时间长为1s,不会被转移到new sublist中,避免了Buffer Pool被污染BP可以被认为是一条长链表。被分成young 和 old两个部分,其中old默认占37%的大小(由innodb_old_blocks_pct 配置)。靠近顶端的Page表示最近被访问。靠近尾端的Page表示长时间未被访问。而这两个部分的交汇处成为midpoint。每当有新的Page需要加载到BP时,该page都会被插入到midpoint的位置,并声明为old-page。当old部分的page,被访问到时,该page会被提升到链表的顶端,标识为young。
由于table scan的操作是先load page,然后立即触发一次访问。所以当innodb_old_blocks_time =0 时,会导致table scan所需要的page不读的作为young page被添加到链表顶端。而一些使用较为不频繁的page就会被挤出BP,使得之后的SQL会产生磁盘IO,从而导致响应速度变慢。
这时虽然mysqldump访问的page会不断加载在LRU顶端,但是高频度的热点数据访问会以更快的速度把page再次抢占到LRU顶端。从而导致mysqldump加载入的page会被迅速刷下,并立即被evict(淘汰)。因此,time=0或1000对这种压力环境下的访问不会造成很大影响,因为dump的数据根本抢占不过热点数据。不只dump,当大数据操作的时候也是如此。
二、mysql系统层面优化
1.关闭 numa=off,或修改策略为interleave(交织分配内存)防止意外的swap
numa策略引入了node的概念,每个物理CPU都被视为一个node,而每个node都有一个local memory,相对这个node之外的其它node都属于外部访问。
NUMA的内存分配策略有localalloc(默认)、preferred、membind、interleave。
localalloc规定进程从当前node上请求分配内存;
preferred比较宽松地指定了一个推荐的node来获取内存,如果被推荐的node上没有足够内存,进程可以尝试别的node。
membind可以指定若干个node,进程只能从这些指定的node上请求分配内存。
interleave规定进程从指定的若干个node上以Round-roll算法交织地请求分配内存。
每个进程(或线程)都会分配一个优先node,对于系统默认的localalloc策略会有一个问题,对于mysql这种几乎占满整个系统内存的应用来说,很容就把某个node的资源给占满,若Linux又把一个大的资源分配到这个已经占满资源的node时,会资源不足,造成内存数据于磁盘进行交换,或者摒弃buffer_pool里的活跃数据。在实际测试中发现比如有node0、node1 两个物理node,当系统负载很高的时候,node0资源被占满,node1虽然仍有部分空闲内存,但是系统即使进行内存到磁盘交换也不会去利用node1上的空闲资源。
因此建议对于像mysql这样的单实例的庞大复杂的进程来说,关闭numa或者设置策略为交织分配内存更合理。但对于一个机器上有多少个实例,可以每个实例绑定一个CPU核上。然后就可以充分利用numa的特性,更高效。
2.增加本地端口,以应对大量连接
echo ‘1024 65000′ > /proc/sys/net/ipv4/ip_local_port_range
该参数指定端口的分配范围,该端口是向外访问的限制。mysql默认监听的3306端口即使有多个请求链接,也不会有影响。但是由于mysql是属于高内存、高cpu、高io应用,不建议把多少应用于mysql混搭在同一台机器上。即使业务量不大,也可以通过降低单台机器的配置,多台机器共存来实现更好。
3.增加队列的链接数
echo ‘1048576’ > /proc/sys/net/ipv4/tcp_max_syn_backlog
建立链接的队列的数越大越好,但是从另一个角度想,实际环境中应该使用连接池更合适,避免重复建立链接造成的性能消耗。使用连接池,链接数会从应用层面更可控些。
4.设置链接超时时间
echo ’10’ > /proc/sys/net/ipv4/tcp_fin_timeout
该参数主要为了降低TIME_WAIT占用的资源时长。尤其针对http短链接的服务端或者mysql不采用连接池效果比较明显。
三、其它层面优化的考虑
对于高DAU的业务mysql实例来说,建议不要吝惜内存,使用128G或更高内存,innodb很好的利用了内存的优势来提高mysql的性能,我们就要给予他足够的空间来发挥他的性能。磁盘IO性能远不及内存的处理速度,这个无可厚非,所做的优化尽量的把需求IO的操作阻拦到内存直接返回给客户端。
当然内存再高也不能把所有的数据都缓存到内存中,在实际的大部分业务中还是依赖随机IO居多,更如现今比较火的手游,更是高随��写入的业务类型,各个云厂商也都默认提供SSD甚至需求更高的PCIe Flash存储设备。通过提高磁盘的IO性能也是其次的选择。
另业务如果足够大,单台机器必然无法支撑,就要考虑分库,分表,大部分产品公司所做的还是按业务划分库。如果一项业务也大到单台机器无法承受,那就需要分表和分库来操作了。其实不管业务是否会做大,当开始建立工程的时候都应该要做到支持可分库、可分表(尽量避免使用表的自增ID作为业务ID使用)、可分业务(尽量避免事务操作,甚至允许在业务上有些可接受的牺牲,否则后期很难划分业务),否则只有面临重构的尴尬场面。这样做的好处是即使有些错误的设计预想不周,由于业务的各种原因无时间重构,也可以通过扩展、迁移的方式来降低单点造成的影响程度,然后后期再慢慢优化。
有一点一定要注意,“杀手级”sql语句的存在会让以上所有优化全部作废。比如上千万表数据的无索引搜索、排序、计算。所以必须开启慢查询日志排查所有慢查询语句。
MySQL在高内存、IO利用率上的几个优化点的更多相关文章
- mysql在高内存、IO利用率上的几个优化点 (sync+fsync) 猎豹移动技术博客
http://dev.cmcm.com/archives/107 Posted on 2014年10月16日 by liuding | 7条评论 以下优化都是基于CentOS系统下的一些优化整理,有不 ...
- Java线上应用故障排查之二:高内存占用
搞Java开发的,经常会碰到下面两种异常: 1.java.lang.OutOfMemoryError: PermGen space 2.java.lang.OutOfMemoryError: Java ...
- 通过修改my.ini配置文件来解决MySQL 5.6 内存占用过高的问题
打开后台进程发现mysql占用的内存达到400+M. 修改一下my.ini这个配置文件的配置选项是可以限制MySQL5.6内存占用过高这一问题的,具体修改选项如下: performance_schem ...
- java线上应用故障排查之二:高内存占用【转】
前一篇介绍了线上应用故障排查之一:高CPU占用,这篇主要分析高内存占用故障的排查. 搞Java开发的,经常会碰到下面两种异常: 1.java.lang.OutOfMemoryError: PermGe ...
- 如何做到MySQL的高可用?
本课时的主题是“MySQL 高可用”,主要内容包含: 什么是高可用性 MySQL 如何提升 MTBF MySQL 如何降低 MTTR 避免单点失效 基础软硬件避免单点 MySQL 高可用架构选型 故障 ...
- Mysql在高并发情况下,防止库存超卖而小于0的解决方案
背景: 本人上次做申领campaign的PHP后台时,因为项目上线后某些时段同时申领的人过多,导致一些专柜的存货为负数(<0),还好并发量不是特别大,只存在于小部分专柜而且一般都是-1的状况,没 ...
- 【mysql】高可用集群之MMM
一.复制的常用拓扑结构 复制的体系结构有以下一些基本原则: (1) 每个slave只能有一个master: (2) 每个slave只能有一个唯一的服务器ID: (3) 每个maste ...
- TCMalloc优化MySQL、Nginx内存管理
TCMalloc的全称为Thread-Caching Malloc,是谷歌开发的开源工具google-perftools中的一个成员. 与标准的glibc库的Malloc相比,TCMalloc库在内存 ...
- CENTOS 修改MYSQL文件到内存盘
# 必须说明的是: # 0 内存盘的特性是断电就丢数据. # 1 对数据时效性要求高的自己做主从 # 2 重启or关机必须导出数据和开机加载数据. # 3 最好弄个脚本 开关机自己调用. # 4 简单 ...
随机推荐
- 瀑布流布局(等宽不等高jQuery)
在百度上看见的好多都是引用Masonry插件 ,之后我自己尝试了一个没有使用插件的 <body> <div id="main"> <div cla ...
- VS2013 中 CString类型转换为LPCSTR类型
HWND hWnd = ::FindWindow(NULL, L"XXXXXXX"); if (hWnd != NULL) { DWORD dwReadBytes; unsigne ...
- Python----unittest discover()方法与执行顺序
一.Unittest discover()可以根据不同的功能创建不同的测试文件,甚至是不同的测试目录,测试文件中还可以将不同的小功能划分为不同的测试类,在类下编写测试用例,让整体结构更加清晰一般是通过 ...
- Git版本库管理
Step 1 查看哪些历史提交过文件占用空间较大 使用以下命令可以查看占用空间最多的五个文件: git rev-list --objects --all | grep "$(git veri ...
- day 10 函数命名空间、函数嵌套和作用域
1. day 09 内容复习 # 函数 # 可读性强 复用性强 # def 函数名(): # 函数体 #return 返回值 # 所有的函数 只定义不调用就一定不执行 #先定义后调用 #函数名() # ...
- Java的四个标记接口:Serializable、Cloneable、RandomAccess和Remote接口
一.概述 标记接口是一些没有属性和方法的接口,也是一种设计思想.Java中的一个标记接口表示的的是一种类的特性,实现了该标记接口的类则具有该特性.如实现了Serializable接口的类,表示这个类的 ...
- java判断一个字符串是否为空,isEmpty和isBlank的区别
转载于:https://blog.csdn.net/liusa825983081/article/details/78246792 实际应用中,经常会用到判断字符串是否为空的逻辑 比较简单的就是用 S ...
- 4ci
- C#中枚举的使用
一.什么是枚举类型 枚举类型(也称为枚举):该类型可以是除 char以外的任何整型(重点). 枚举元素的默认基础类型为 int.准许使用的枚举类型有 byte.sbyte.short.ushort.i ...
- [Linux] Configure iSCSI on Linux5 (both target and initiator)
********************************************************************************Target************** ...