分布式监控系统开发【day38】:报警模块解析(六)
一、负责把达到报警条件的trigger进行分析 ,并根据 action 表中的配置来进行报警
1、目录结构

2、功能如下
- 1、找到trigger的关联动作,
- 2、收到的数据传给trigger_msg就是trigger_data
- 3、trigger_id') == None怎么会等于None
- 4、每个action都可以直接包含多个主机或主机组
3、实现代码
class ActionHandler(object):
'''
负责把达到报警条件的trigger进行分析 ,并根据 action 表中的配置来进行报警
''' def __init__(self,trigger_data,alert_counter_dic):
self.trigger_data = trigger_data
#self.trigger_process()
self.alert_counter_dic = alert_counter_dic def record_log(self,action_obj,action_operation,host_id,trigger_data):
"""record alert log into DB"""
models.EventLog.objects.create(
event_type = 0,
host_id=host_id,
trigger_id = trigger_data.get('trigger_id'),
log = trigger_data
)
二、报警发送邮件内容
1、实现代码
def action_email(self,action_obj,action_operation_obj,host_id,trigger_data):
'''
sending alert email to who concerns.
:param action_obj: 触发这个报警的action对象
:param action_operation_obj: 要报警的动作对象
:param host_id: 要报警的目标主机
:param trigger_data: 要报警的数据
:return:
''' print("要发报警的数据:",self.alert_counter_dic[action_obj.id][host_id])
print("action email:",action_operation_obj.action_type,action_operation_obj.notifiers,trigger_data)
notifier_mail_list = [obj.email for obj in action_operation_obj.notifiers.all()]
subject = '级别:%s -- 主机:%s -- 服务:%s' %(trigger_data.get('trigger_id'),
trigger_data.get('host_id'),
trigger_data.get('service_item')) send_mail(
subject,
action_operation_obj.msg_format,
settings.DEFAULT_FROM_EMAIL,
notifier_mail_list,
)
2、邮件截图类似于下图

三、分析trigger并报警
1、为什么tigger里关联了template,template里又关联了主机,那action还要直接关联主机呢?
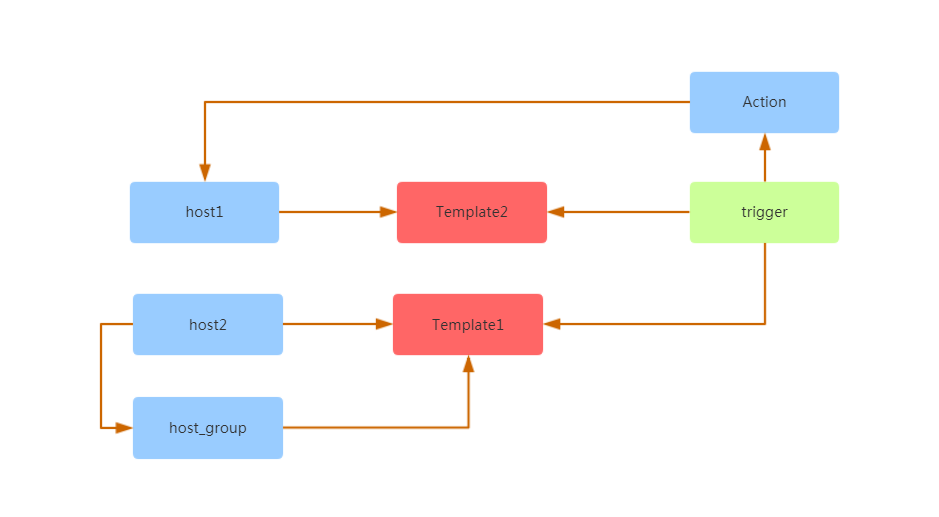
那是因为一个trigger可以被多个template关联,这个trigger触发了,不一定是哪个tempalte里的主机导致的
2、功能如下
1、第一次被 触,先初始化一个action counter dic
2、这个主机第一次触发这个action的报警
你不是触发一次我报一次,我是到了触发时间触发才报警,
3、如果达到报警触发interval次数,就记数+1
4、该报警了
- 报完警后更新一下报警时间 ,这样就又重新计算alert interval了
- 打印离下次触发报警的时间还有[%s]s" %
3、实现代码
def trigger_process(self):
'''
分析trigger并报警
:return:
'''
print('Action Processing'.center(50,'-')) if self.trigger_data.get('trigger_id') == None: #trigger id == None
print(self.trigger_data)
if self.trigger_data.get('msg'):
print(self.trigger_data.get('msg')) #既然没有trigger id,直接报警给管理 员
else:
print("\033[41;1mInvalid trigger data %s\033[0m" % self.trigger_data) else:#正经的trigger 报警要触发了
print("\033[33;1m%s\033[0m" %self.trigger_data) trigger_id = self.trigger_data.get('trigger_id')
host_id = self.trigger_data.get('host_id')
trigger_obj = models.Trigger.objects.get(id=trigger_id)
actions_set = trigger_obj.action_set.select_related() #找到这个trigger所关联的action list
print("actions_set:",actions_set)
matched_action_list = set() # 一个空集合
for action in actions_set:
#每个action 都 可以直接 包含多个主机或主机组,
# 为什么tigger里关联了template,template里又关联了主机,那action还要直接关联主机呢?
#那是因为一个trigger可以被多个template关联,这个trigger触发了,不一定是哪个tempalte里的主机导致的
for hg in action.host_groups.select_related():
for h in hg.host_set.select_related():
if h.id == host_id:# 这个action适用于此主机
matched_action_list.add(action)
if action.id not in self.alert_counter_dic: #第一次被 触,先初始化一个action counter dic
self.alert_counter_dic[action.id] = {}
print("action, ",id(action))
if h.id not in self.alert_counter_dic[action.id]: # 这个主机第一次触发这个action的报警
self.alert_counter_dic[action.id][h.id] = {'counter': 0, 'last_alert': time.time()}
# self.alert_counter_dic.setdefault(action,{h.id:{'counter':0,'last_alert':time.time()}})
else:
#如果达到报警触发interval次数,就记数+1
if time.time() - self.alert_counter_dic[action.id][h.id]['last_alert'] >= action.interval:
self.alert_counter_dic[action.id][h.id]['counter'] += 1
#self.alert_counter_dic[action.id][h.id]['last_alert'] = time.time() else:
print("没达到alert interval时间,不报警",action.interval,
time.time() - self.alert_counter_dic[action.id][h.id]['last_alert'])
#self.alert_counter_dic.setdefault(action.id,{}) for host in action.hosts.select_related():
if host.id == host_id: # 这个action适用于此主机
matched_action_list.add(action)
if action.id not in self.alert_counter_dic: # 第一次被 触,先初始化一个action counter dic
self.alert_counter_dic[action.id] = {}
if h.id not in self.alert_counter_dic[action.id]: #这个主机第一次触发这个action的报警
self.alert_counter_dic[action.id][h.id] ={'counter': 0, 'last_alert': time.time()}
#self.alert_counter_dic.setdefault(action,{h.id:{'counter':0,'last_alert':time.time()}})
else:
# 如果达到报警触发interval次数,就记数+1
if time.time() - self.alert_counter_dic[action.id][h.id]['last_alert'] >= action.interval:
self.alert_counter_dic[action.id][h.id]['counter'] += 1
#self.alert_counter_dic[action.id][h.id]['last_alert'] = time.time()
else:
print("没达到alert interval时间,不报警", action.interval,
time.time() - self.alert_counter_dic[action.id][h.id]['last_alert']) print("alert_counter_dic:",self.alert_counter_dic)
print("matched_action_list:",matched_action_list)
for action_obj in matched_action_list:#
if time.time() - self.alert_counter_dic[action_obj.id][host_id]['last_alert'] >= action_obj.interval:
#该报警 了
print("该报警了.......",time.time() - self.alert_counter_dic[action_obj.id][host_id]['last_alert'],action_obj.interval)
for action_operation in action_obj.operations.select_related().order_by('-step'):
if action_operation.step > self.alert_counter_dic[action_obj.id][host_id]['counter']:
#就
print("##################alert action:%s" %
action_operation.action_type,action_operation.notifiers) action_func = getattr(self,'action_%s'% action_operation.action_type)
action_func(action_obj,action_operation,host_id,self.trigger_data) #报完警后更新一下报警时间 ,这样就又重新计算alert interval了
self.alert_counter_dic[action_obj.id][host_id]['last_alert'] = time.time()
self.record_log(action_obj,action_operation,host_id,self.trigger_data)
# else:
# print("离下次触发报警的时间还有[%s]s" % )
分布式监控系统开发【day38】:报警模块解析(六)的更多相关文章
- Python之路,Day20 - 分布式监控系统开发
Python之路,Day20 - 分布式监控系统开发 本节内容 为什么要做监控? 常用监控系统设计讨论 监控系统架构设计 监控表结构设计 为什么要做监控? –熟悉IT监控系统的设计原理 –开发一个 ...
- 分布式监控系统开发【day37】:需求讨论(一)
本节内容 为什么要做监控? 常用监控系统设计讨论 监控需求讨论 如何实现监控服务器的水平扩展? 监控系统架构设计 一.为什么要做监控? 熟悉IT监控系统的设计原理 开发一个简版的类Zabbix监控系统 ...
- Python之分布式监控系统开发
为什么要做监控? –熟悉IT监控系统的设计原理 –开发一个简版的类Zabbix监控系统 –掌握自动化开发项目的程序设计思路及架构解藕原则 常用监控系统设计讨论 Zabbix Nagios 监控系统需求 ...
- day26 分布式监控系统开发
本节内容 为什么要做监控? 常用监控系统设计讨论 监控系统架构设计 监控表结构设计 为什么要做监控? –熟悉IT监控系统的设计原理 –开发一个简版的类Zabbix监控系统 –掌握自动化开发项目的程序设 ...
- 分布式监控系统开发【day38】:报警阈值程序逻辑解析(三)
一.需求讨论 1.请问如何解决延迟问题 1000台机器,每1分钟循环一次但是刚好第一次循环第一秒刚处理完了,结果还没等到第二分钟又出问题,你那必须等到第二次循环,假如我这个服务很重要必须实时知道,每次 ...
- 分布式监控系统开发【day38】:主机存活检测程序解析(七)
一.目录结构 二.入口 1.文件MonitorServer.py import os import sys if __name__ == "__main__": os.enviro ...
- 分布式监控系统开发【day38】:报警自动升级代码解析及测试(八)
一.报警自动升级代码解析 发送邮件代码 def action_email(self,action_obj,action_operation_obj,host_id,trigger_data): ''' ...
- 分布式监控系统开发【day38】:监控trigger表结构设计(一)
一.需求讨论 1.zabbix触发器的模板截图 1.zabbix2.4.7 2.zabbix3.0 2.模板与触发器关联的好处 好处就是可以批量处理,比如我说我有1000机器都要监控cpu.内存.IO ...
- 分布式监控系统开发【day38】:报警策略队列处理(五)
一.目录结构 二.报警策略队列处理 1.入口MonitorServer import os import sys if __name__ == "__main__": os.env ...
随机推荐
- 转:sql server锁知识及锁应用
sql server锁(lock)知识及锁应用 提示:这里所摘抄的关于锁的知识有的是不同sql server版本的,对应于特定版本时会有问题. 一 关于锁的基础知识 (一). 为什么要引入锁 当多个用 ...
- CF_#478_Div.2_Hag's Khashba
做的正儿八经的计算几何题不多,慢慢来吧. 题目描述: http://codeforces.com/contest/975/problem/E 大意就是说给你一个凸多边形,一开始1,2两点有钉子固定在墙 ...
- nginx主配置文件详解
#定义Nginx运行的用户和用户组user www www; #nginx进程数,建议设置为等于CPU总核心数.worker_processes 8; #全局错误日志定义类型,[ debug | in ...
- JDBC获得连接时报connection refused
1,检查数据库服务器的IP是否正确. 2,检查用户名密码是否正确. 3,检查SID,获selecte instance_name from v$instance;
- supervisor management kafka zookeeper
# cat kafka.ini [program:kafka] command=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/ ...
- appium设置会话时间,可以超长时。Open Application
- leetcode 263. Ugly Number 、264. Ugly Number II 、313. Super Ugly Number 、204. Count Primes
263. Ugly Number 注意:1.小于等于0都不属于丑数 2.while循环的判断不是num >= 0, 而是能被2 .3.5整除,即能被整除才去除这些数 class Solution ...
- 全解史上最快的JOSN解析库 - alibaba Fastjson
JSON,全称:JavaScript Object Notation,作为一个常见的轻量级的数据交换格式,应该在一个程序员的开发生涯中是常接触的.简洁和清晰的层次结构使得 JSON 成为理想的数据交换 ...
- jmeter学习记录--07--jmeter元件
通过jmeter元件可以模拟负载.参数化.设置关联.设置检查点.设置集合点.控制场景运行.监控测试结果等. 1.逻辑控制器:比如foreach控制器,查询到了订单并要对每个订单进行出库操作,以订单号作 ...
- spring boot 表单验证
1 设置某个字段的取值范围 1.1 取值范围验证:@Min,@Max ① 实例类的属性添加注解@Min ② Controller中传入参数使用@Valid注解 1.2 不能为空验证:@NotNull ...