深度学习(一)——CNN算法流程
深度学习(一)——CNN(卷积神经网络)算法流程
参考:http://dataunion.org/11692.html
0 引言
20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks-简称CNN)。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。 K.Fukushima在1980年提出的新识别机是卷积神经网络的第一个实现网络。随后,更多的科研工作者对该网络进行了改进。其中,具有代表性的研究成果是Alexander和Taylor提出的“改进认知机”,该方法综合了各种改进方法的优点并避免了耗时的误差反向传播。
一般地,CNN的基本结构包括两层:
1)特征提取层:每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;
2)特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。
此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。
1 神经网络结构
如图为单层神经网络:
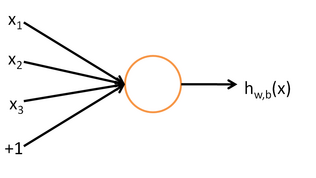
其计算表达式如下:
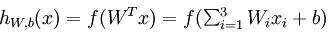
其中,该单元也可以被称作是Logistic回归模型。当将多个单元组合起来并具有分层结构时,就形成了神经网络模型如下图所示:
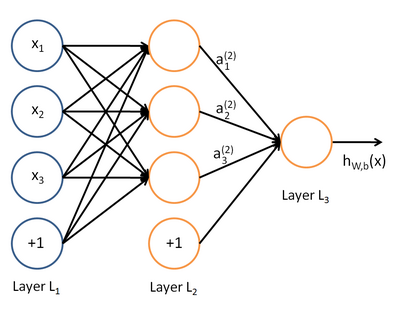
则其表达式如下所示
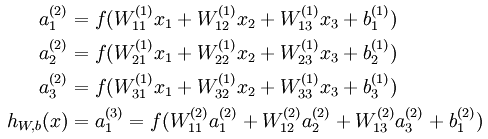
如此一层一层的加上去,最终就形成了深度神经网络。而本文的卷积神经网络就是一种深度神经网络。
2 卷积神经网络
卷积神经网络CNN的结构一般包含这几个层(如图1):
1)输入层:用于数据的输入
2)卷积层:使用卷积核进行特征提取和特征映射
3)激励层:由于卷积也是一种线性运算,因此需要增加非线性映射
4)池化层:进行下采样,对特征图稀疏处理,减少数据运算量。
5)全连接层:通常在CNN的尾部进行重新拟合,减少特征信息的损失
参考:https://blog.csdn.net/love__live1/article/details/79481052
在卷积神经网络中,有几个特别重要的改进思路和技术,为了降低神经网络节点,来提高学习效率,具体如下所述:
2.1 局部感知
卷积神经网络有两种神器可以降低参数数目,第一种神器叫做局部感知野。一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。如下图所示:左图为全连接,右图为局部连接。

在上右图中,假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的千分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。
2.2 参数共享
但其实这样的话参数仍然过多,那么就启动第二级神器,即权值共享。在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
怎么理解权值共享呢?我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更直观一些,当从一个大尺寸图像中随机选取一小块,比如说 8×8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8×8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8×8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
如下图所示,展示了一个33的卷积核在55的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。

2.3 多卷积核
上面所述只有100个参数时,表明只有1个100*100的卷积核,显然,特征提取是不充分的,我们可以添加多个卷积核,比如32个卷积核,可以学习32种特征。在有多个卷积核时,如下图所示:

上图右,不同颜色表明不同的卷积核。每个卷积核都会将图像生成为另一幅图像。比如两个卷积核就可以将生成两幅图像,这两幅图像可以看做是一张图像的不同的通道。如下图所示,下图有个小错误,即将w1改为w0,w2改为w1即可。下文中仍以w1和w2称呼它们。
下图展示了在四个通道上的卷积操作,有两个卷积核,生成两个通道。其中需要注意的是,四个通道上每个通道对应一个卷积核,先将w2忽略,只看w1,那么在w1的某位置(i,j)处的值,是由四个通道上(i,j)处的卷积结果相加然后再取激活函数值得到的。


所以,在上图由4个通道卷积得到2个通道的过程中,参数的数目为4×2×2×2个,其中4表示4个通道,第一个2表示生成2个通道,最后的2×2表示卷积核大小。
2.4 Down-pooling
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) × (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 892 × 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。

至此,卷积神经网络的基本结构和原理已经阐述完毕。
2.5 多层卷积
在实际应用中,往往使用多层卷积,然后再使用全连接层进行训练,多层卷积的目的是一层卷积学到的特征往往是局部的,层数越高,学到的特征就越全局化。
深度学习(一)——CNN算法流程的更多相关文章
- 深度学习 目标检测算法 SSD 论文简介
深度学习 目标检测算法 SSD 论文简介 一.论文简介: ECCV-2016 Paper:https://arxiv.org/pdf/1512.02325v5.pdf Slides:http://w ...
- [转] 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
转自知乎上看到的一篇很棒的文章:用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文 ...
- 深度学习入门: CNN与LSTM(RNN)
1. 理解深度学习与CNN: 台湾李宏毅教授的入门视频<一天搞懂深度学习>:https://www.bilibili.com/video/av16543434/ 其中对CNN算法的矩阵卷积 ...
- 深度学习之 cnn 进行 CIFAR10 分类
深度学习之 cnn 进行 CIFAR10 分类 import torchvision as tv import torchvision.transforms as transforms from to ...
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- 【深度学习】CNN 中 1x1 卷积核的作用
[深度学习]CNN 中 1x1 卷积核的作用 最近研究 GoogLeNet 和 VGG 神经网络结构的时候,都看见了它们在某些层有采取 1x1 作为卷积核,起初的时候,对这个做法很是迷惑,这是因为之前 ...
- 用深度学习(CNN RNN Attention)解决大规模文本分类问题 - 综述和实践
https://zhuanlan.zhihu.com/p/25928551 近来在同时做一个应用深度学习解决淘宝商品的类目预测问题的项目,恰好硕士毕业时论文题目便是文本分类问题,趁此机会总结下文本分类 ...
- 基于候选区域的深度学习目标检测算法R-CNN,Fast R-CNN,Faster R-CNN
参考文献 [1]Rich feature hierarchies for accurate object detection and semantic segmentation [2]Fast R-C ...
随机推荐
- 我在MySQL免安装版使用过程中遇到的问题记录【二】
跟上次问题不一样!这次是重新安装MySQL免安装版,各种文件搞对了还是错了也不清楚. 现在是:下载完安装包之后,按照现在的下方的代码,创建一个my-default.ini文件并放入下代码: [mysq ...
- webpack根据开发与生产环境配置不同变量--webpack.DefinePlugin
webpack有一个DefinePlugin接口,可以实现根据开发与生产环境配置不同变量.范例如下: 需求:开发环境请求baseUrl = '':生产环境请求 baseUrl = 'http://lo ...
- php中print、echo、print_r、var_dump的区别
echo,print,print_r,var_dump区别 print只能接收一个字符串:print有返回值1(可在表达式中使用) e.g print 'string 1' e.g if($exp & ...
- python 测试登录接口只返回response200的问题
但是使用postman测试是有json串的 后来发现postman传参是用的raw格式,raw的格式相当于json 而这里的data其实是form-data格式,需要用json的格式
- Codeforces1056E.Check Transcription(枚举+Hash)
题目链接:传送门 题目: E. Check Transcription time limit per test seconds memory limit per test megabytes inpu ...
- python 三种 安装包的方法
1.pycharm安装第三方库 然后点+搜索库安装. 注意 : 有时候点+会出现下图提示:Nothing to show,这就需要在点加号前点一下绿色圈圈的conda标志. 点+号出现下图的内容才是正 ...
- 2.7 while 、for 循环控制语句
一.while语句: 在程序中,需要重复性的做某件事: 1.1.1 while: public class Test{ public static void main(String[] args){ ...
- Classloader精简重点
如果想学习classloader的具体内容,请goodu JVM 在运行时会产生三个ClassLoader,Bootstrap ClassLoader.Extension ClassLoader和 A ...
- 基于C++的牛顿切线法演示
牛顿切线法 中心思想: 利用目标函数二阶泰勒多项式的最优解作为函数的近似最优解.如果新的近似最优解满足计算精度,则终止计算,否则将函数在新点展开成二阶泰勒多项式,用新的泰勒多项式的最优解作为函数的近似 ...
- admin-7
Admin07 root tmooc 还原三台虚拟机[root@room9pc13 ~]# rht-vmctl reset classroom[root@room9pc13 ~]# rht-vmctl ...