MyIASM和Innodb引擎详解
MyIASM 和 Innodb引擎详解
Innodb引擎
Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别,关于数据库事务与其隔离级别的内容请见数据库事务与其隔离级别这篇文章。该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于MySQL后台的完整数据库系统,MySQL运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当SELECT COUNT(*) FROM TABLE时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表。
名词解析:
ACID
A事务的原子性(Atomicity):指一个事务要么全部执行,要么不执行.也就是说一个事务不可能只执行了一半就停止了.比如你从取款机取钱,这个事务可以分成两个步骤:1划卡,2出钱.不可能划了卡,而钱却没出来.这两步必须同时完成.要么就不完成.
C事务的一致性(Consistency):指事务的运行并不改变数据库中数据的一致性.例如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随之改变.
I独立性(Isolation):事务的独立性也有称作隔离性,是指两个以上的事务不会出现交错执行的状态.因为这样可能会导致数据不一致.
D持久性(Durability):事务的持久性是指事务执行成功以后,该事务所对数据库所作的更改便是持久的保存在数据库之中,不会无缘无故的回滚.
MyIASM引擎
MyIASM是MySQL默认的引擎,但是它没有提供对数据库事务的支持,也不支持行级锁和外键,因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。不过和Innodb不同,MyIASM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyIASM也是很好的选择。
两种引擎的选择
大尺寸的数据集趋向于选择InnoDB引擎,因为它支持事务处理和故障恢复。数据库的大小决定了故障恢复的时间长短,InnoDB可以利用事务日志进行数据恢复,这会比较快。主键查询在InnoDB引擎下也会相当快,不过需要注意的是如果主键太长也会导致性能问题,关于这个问题我会在下文中讲到。大批的INSERT语句(在每个INSERT语句中写入多行,批量插入)在MyISAM下会快一些,但是UPDATE语句在InnoDB下则会更快一些,尤其是在并发量大的时候。
Index——索引
索引(Index)是帮助MySQL高效获取数据的数据结构。MyIASM和Innodb都使用了树这种数据结构做为索引。下面我接着讲这两种引擎使用的索引结构,讲到这里,首先应该谈一下B-Tree和B+Tree。
MyIASM引擎的索引结构
MyISAM引擎的索引结构为B+Tree,其中B+Tree的数据域存储的内容为实际数据的地址,也就是说它的索引和实际的数据是分开的,只不过是用索引指向了实际的数据,这种索引就是所谓的非聚集索引。如下图所示:
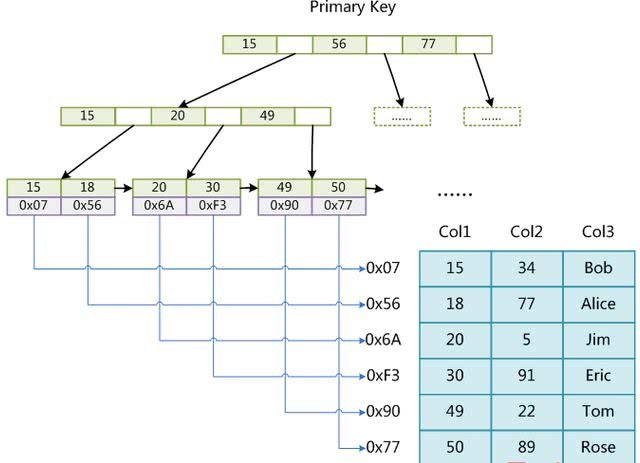
这里设表一共有三列,假设我们以Col1为主键,则上图是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
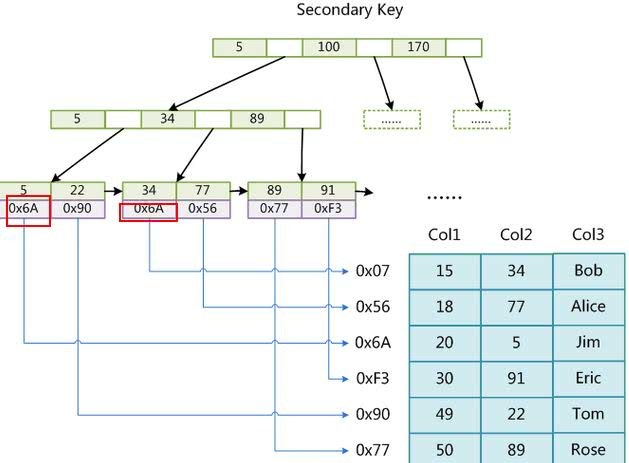
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
Innodb引擎的索引结构
与MyISAM引擎的索引结构同样也是B+Tree,但是Innodb的索引文件本身就是数据文件,即B+Tree的数据域存储的就是实际的数据,这种索引就是聚集索引。这个索引的key就是数据表的主键,因此InnoDB表数据文件本身就是主索引。
并且和MyISAM不同,InnoDB的辅助索引数据域存储的也是相应记录主键的值而不是地址,所以当以辅助索引查找时,会先根据辅助索引找到主键,再根据主键索引找到实际的数据。所以Innodb不建议使用过长的主键,否则会使辅助索引变得过大。建议使用自增的字段作为主键,这样B+Tree的每一个结点都会被顺序的填满,而不会频繁的分裂调整,会有效的提升插入数据的效率。
两者区别:
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
上图是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:
这里以英文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
了解不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调(可能是指“非递增”的意思)的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调(可能是指“非递增”的意思)的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
MyIASM和Innodb引擎详解的更多相关文章
- 如何查看mysql数据库的引擎/MySQL数据库引擎详解
一般情况下,mysql会默认提供多种存储引擎,你可以通过下面的查看: 看你的mysql现在已提供什么存储引擎:mysql> show engines; 看你的mysql当前默认的存储引擎:mys ...
- MySQL数据库的各种存储引擎详解
原文来自:MySQL数据库的各种存储引擎详解 MySQL有多种存储引擎,每种存储引擎有各自的优缺点,大家可以择优选择使用: MyISAM.InnoDB.MERGE.MEMORY(HEAP).BDB ...
- 【mysql】mysql innodb 配置详解
MySQL innodb 配置详解 innodb_buffer_pool_size:这是InnoDB最重要的设置,对InnoDB性能有决定性的影响.默认的设置只有8M,所以默认的数据库设置下面Inno ...
- InnoDB参数详解
1.查询5.5版本的InnoDB参数并注释:[root@localhost etc]# grep -i innodb my.cnf; t_innodb; otherwise, slaves may d ...
- mysql的innodb数据库引擎详解
http://www.jb51.net/softjc/158474.html 这篇文章主要介绍了mysql的innodb数据库引擎,需要的朋友可以参考下 一.mysql体系结构和存储引擎 1. ...
- MySQL基础篇(05):逻辑架构图解和InnoDB存储引擎详解
本文源码:GitHub·点这里 || GitEE·点这里 一.MySQL逻辑架构 1.逻辑架构图 基于下面的逻辑架构图,可以大致熟悉MySQL各个架构组件之间的协同工作关系. 很经典的C/S架构风格, ...
- MySQL数据库系列(三)- MySQL常用引擎MyISAM和InnoDB区别详解
概述 InnoDB:在MySQL 5.5及之后的版本,InnoDB是MySQL默认的事务型引擎,也是最重要和使用最广泛的存储引擎.它被设计成为大量的短期事务,短期事务大部分情况下是正常提交的,很少被回 ...
- MySQL数据库引擎详解
作为Java程序员,MySQL数据库大家平时应该都没少使用吧,对MySQL数据库的引擎应该也有所了解,这篇文章就让我详细的说说MySQL数据库的Innodb和MyIASM两种引擎以及其索引结构.也来巩 ...
- 自动化集成:Kubernetes容器引擎详解
前言:该系列文章,围绕持续集成:Jenkins+Docker+K8S相关组件,实现自动化管理源码编译.打包.镜像构建.部署等操作:本篇文章主要描述Kubernetes引擎用法. 一.基础简介 Kube ...
随机推荐
- Linux svn checkout时候总报设备上没有空间
详细报错信息:svn: 不能打开文件“weibosearch2.0.0/.svn/lock”: 设备上没有空间 但是df -h查看磁盘[root@picdata-1-2 data]# df -h文件系 ...
- Aooms_微服务基础开发平台实战_001_开篇
一.引子 “ 微服务”近年来很火的一个词,如今的热度不亚于当年的SSH组合,各种开发框架.中间件.容器.概念层出不穷. 比如:dubbo.motan.zookeeper.springboot.spri ...
- 【转】ASP.NET MVC实现权限控制
这篇分享一下 ASP.NET MVC权限控制.也就是说某一用户登录之后,某一个用户是否有权限访问Controller,Action(操作),视图等 想实现这些功能,需要在数据库创建好几个表:[User ...
- @Html.DropDownListFor 下拉框绑定(选择默认值)
首先先构建绑定下拉框的数据源 private void GetSalesList() { var userList = _rmaExpressAppService.GetUserList(); Tem ...
- php 使用Glob() 查找文件技巧
定义和用法 glob() 函数返回匹配指定模式的文件名或目录. 该函数返回一个包含有匹配文件 / 目录的数组.如果出错返回 false. 参数 描述 file 必需.规定检索模式. size 可选.规 ...
- python学习笔记(十 一)、GUI图形用户界面
python图形用户界面就是包含按钮.输入框.选择框等组件的窗口.主要依赖与工具包进行代码编写.python GUI工具包并发互斥的,你可以选择多个工具包进行安装,有极大选择空间.每个工具包都有不同用 ...
- JestClient 使用教程,教你完成大部分ElasticSearch的操作。
本篇文章代码实现不多,主要是教你如何用JestClient去实现ElasticSearch上的操作. 授人以鱼不如授人以渔. 一.说明 1.elasticsearch版本:6.2.4 . jdk版本: ...
- 使用Jenkins自动发布Windows服务项目
不同于发布Web项目,自动发布Windows服务项目需要解决以下几个问题: 如何远程停止和开启服务?需要在发布前停止服务,在发布完成后开启服务. 如何上传编译文件到目标服务器? 问题1:如何远程停止和 ...
- Serialization
title: Serialization date: 2018-03-26 15:18:26 tags: [JAVA,Read] categories: other --- 概述 程序运行时,变量的内 ...
- Laravel5.5 邮件驱动使用 SMTP 驱动实现邮件发送
laravel5.5 邮件驱动 Laravel 支持多种邮件驱动,包括 smtp.Mailgun.Maildrill.Amazon SES.mail 和 sendmail.Mailgun . Mail ...