reshape2 数据操作 数据融合( cast)
我们在做数据分析的时候,对数据进行操作也是一项极其重要的内容,这里我们同样介绍强大包reshape2,其中的几个函数,对数据进行操作cast和melt两个函数绝对少不了。
首先是cast,把长型数据转换成你想要的任何宽型数据,
dcast(data, formula, fun.aggregate = NULL, ..., margins = NULL, subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data))
acast(data, formula, fun.aggregate = NULL, ..., margins = NULL, subset = NULL, fill = NULL, drop = TRUE, value.var = guess_value(data))
参数:
data 要进行转换的数据框
formula 用于转换的公式
fun.aggregate 聚合函数,表达式为:行变量~列变量~三维变量~......,另外,.表示后面没有数据列,…表示之前或之后的所有数据列
margins 用于添加边界汇总数据
subset 用于添加过滤条件,需要载入plyr包
其他三个参数,用到的情况相对较少。
下面来看些具体的例子
先构建一个数据集
x<-data.frame(id=1:6,
name=c("wang","zhang","li","chen","zhao","song"),
shuxue=c(89,85,68,79,96,53),
yuwen=c(77,68,86,87,92,63))
x
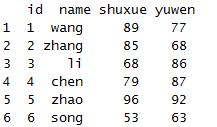
先使用melt函数对数据进行融化操作。
library(reshape2)
x1<-melt(x,id=c("id","name")) x1

可以看到数据已经变成了长型数据(melt函数后面详细介绍)。
接下来就是对数据进行各种变型操作了。
acast(x1,id~variable)

dcast(x1,id~variable)

从以上两个执行结果来看,可以看出acast和dcast的区别
这里acast输出结果省略了id这个列,而dcast则输出id列
acast(x1,id~name~variable)
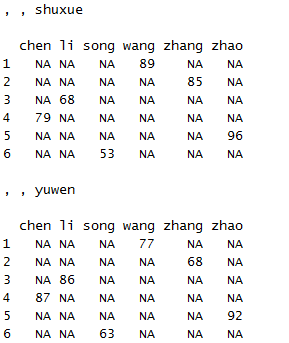
三维的情况下acast输出的是一个数组,而dcast则报错,因为dcast输出结果为数据框。
dcast(x1,id~variable,mean,margins=T)

可以看到,边缘多了两列汇总数据是对行列求平均的结果。
dcast(x1,id~variable,mean,margins=c("id"))
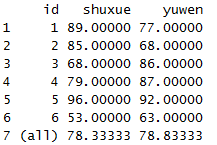
只对列求平均值,当然也可以只对行求平均值,把id改成variable就可以了。
library(plyr)
dcast(x1,id~variable,mean,subset=.(id==1|id==3))
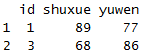
这里subset的筛选功能强大可以进行各种各样的筛选操作,类似filter的作用。
dcast(x1,id+name~variable)
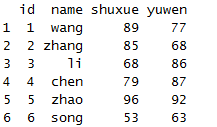
数据还原成原来的样子了。
dcast(x1,variable~name)
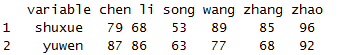
对行列进行对调。
acast(x1,variable~id+name)

到这里,我们已经着实体会了cast的强大,数据几乎可以转换成任何形式。
跟excel中的数据透视表功能类似。
reshape2 数据操作 数据融合( cast)的更多相关文章
- reshape2 数据操作 数据融合 (melt)
前面一篇讲了cast,想必已经见识到了reshape2的强大,当然在使用cast时配合上melt这种强大的揉数据能力才能表现的淋漓尽致. 下面我们来看下,melt这个函数以及它的特点. melt(da ...
- dplyr 数据操作 数据排序 (arrange)
在R中,我们在整理数据时,经常需要对数据排序,以便数据增强数据的可读性. 下面我们来看下dplyr中的,arrange函数 arrange(.data, ...) 跟filter()类似,arrang ...
- dplyr 数据操作 数据过滤 (filter)
在R的使用过程中我们几乎都绕不开Hadley Wickham 开发的几个包,前面说过的ggplot2.reshape2以及即将要讲的dplyr 因为这几个包可以非常轻易的使我们从复杂的数据操作中逃离, ...
- HIVE之 DDL 数据定义 & DML数据操作
DDL数据库定义 创建数据库 1)创建一个数据库,数据库在 HDFS 上的默认存储路径是/user/hive/warehouse/*.db. hive (default)> create dat ...
- pandas模块的数据操作
数据操作 数据操作最重要的一步也是第一步就是收集数据,而收集数据的方式有很多种,第一种就是我们已经将数据下载到了本地,在本地通过文件进行访问,第二种就是需要到网站的API处获取数据或者网页上爬取数据, ...
- Appium+python自动化(三十)- 实现代码与数据分离 - 数据配置-yaml(超详解)
简介 本篇文章主要介绍了python中yaml配置文件模块的使用让其完成数据和代码的分离,宏哥觉得挺不错的,于是就义无反顾地分享给大家,也给大家做个参考.一起跟随宏哥过来看看吧. 思考问题 前面我们配 ...
- SQL不同服务器数据库之间的数据操作整理(完整版)
---------------------------------------------------------------------------------- -- Author : htl25 ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作(二)
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
- 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据操作
http://www.cnblogs.com/wgp13x/p/4934521.html 内容一样,样式好的版本. 使用Hive或Impala执行SQL语句,对存储在Elasticsearch中的数据 ...
随机推荐
- 用js使得输入框input只能输入数字
JS判断只能是数字和小数点1.文本框只能输入数字代码(小数点也不能输入)<input onkeyup="this.value=this.value.replace(/\D/g, ...
- 隐藏或删除指定的html元素
<div id="Contain"> <div>好好学习<div> <div>天天向上<div> <div> ...
- windows下的畸形目录和文件的创建与删除
畸形目录的创建 md c:\a..\ 删除畸形目录 rd /s /q c:\a..\ 创建畸形文件 1 echo text> \\.\c:\aux..txt 读取畸形文件 type \\.\c: ...
- 想要见识外太空?一款VR头显就能帮你实现梦想
除了宇航员,我们中的大多数人一生都没有机会前往地球之外的宇宙空间,只能在图片和纪录片中感受浩瀚宇宙的震撼. 美国肯尼迪航天中心和BrandVR合作推出的VR头显 而NASA在VR中的投资,创造的新的V ...
- 剑指offer ------ 刷题总结
面试题3 -- 搜索二维矩阵 写出一个高效的算法来搜索 m × n矩阵中的值. 这个矩阵具有以下特性: 1. 每行中的整数从左到右是排序的. 2. 每行的第一个数大于上一行的最后一个整数. publi ...
- ng动态显示和隐藏
<!DOCTYPE html><html><head><meta charset="utf-8"><script src=&q ...
- empty,is_null,isset返回值的比较
empty,is_null,isset返回值的比较: 变量 empty is_null isset$a="& ...
- VS2010 编译 sqlite3 生成动态库和链接库
如果想以dll的方式使用sqlite而新建空的dll工程,添加sqlite源文件,会发现能生成dll,但缺乏lib函数信息映射库,单独使用dll文件是比较麻烦的,而网上多数做法是通过lib.exe手动 ...
- NGINX----源码阅读一(main函数)
1.ngx_debug_init(); 初始化debug函数,一般为空. 2.ngx_strerror_init(): 将系统错误码+错误信息,以ngx_str_t数组保存. 3.ngx_get_op ...
- CodeForces 675D Tree Construction
递归,$RMQ$. 因为$n$较大,可以采用递归建树的策略. 对每一个点标一个$id$.然后按照$v$从小到大排序,每一段$[L,R]$的根节点就是$id$最小的那个. 因为二叉搜索树可能是一条链,所 ...