[Erlang 0116] 当我们谈论Erlang Maps时,我们谈论什么 Part 1

Record的痛点
7> rd(person,{name,id}).
person
8> #person{}.
#person{name = undefined,id = undefined}
9> P=person.
person
10> #P{}.
* 1: syntax error before: P
10>
http://stackoverflow.com/questions/4103731/is-it-possible-to-use-record-name-as-a-parameter-in-erlang
10> N=name.
name
11> #person{N="zen"}.
* 1: field 'N' is not an atom or _ in record person
12>
Eshell V6.0 (abort with ^G)
1> rd(foo,{a,b,c}).
foo
2> rd(a,{f,m}).
a
3> rd(f,{id,name}).
f
4> #foo{a=#a{f=#f{id=2002,name="zen"},m=1984},b=1234,c=2465}.
#foo{a = #a{f = #f{id = 2002,name = "zen"},m = 1984},
b = 1234,c = 2465}
5> D=v(4).
#foo{a = #a{f = #f{id = 2002,name = "zen"},m = 1984},
b = 1234,c = 2465}
6> D#foo.a#a.f#f.name.
"zen"
原因何在?
This parse transform can be used to reduce compile-time dependencies in large systems.In the old days, before records, Erlang programmers often wrote access functions for tuple data. This was tedious and error-prone. The record syntax made this easier, but since records were implemented fully in the pre-processor, a nasty compile-time dependency was introduced.
This module automates the generation of access functions for records. While this method cannot fully replace the utility of pattern matching, it does allow a fair bit of functionality on records without the need for compile-time dependencies.

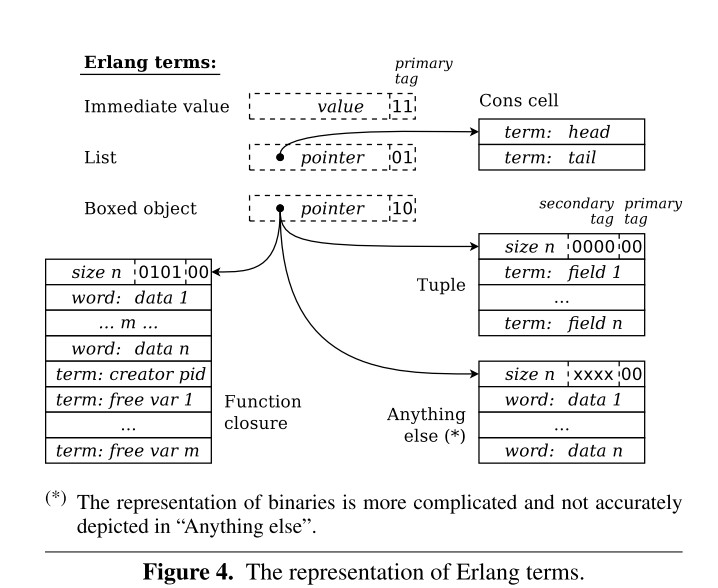
01 = Cons cell (list)
10 = Boxed (tuple, float, bignum, binary, external pid/port, exterrnal/internal ref ...)
11 = Immediate (the rest - secondary tag present)
– 0001 = Binary match state (internal type)
– 001x = Bignum (needs more than 28 bits)
– 0100 = Ref
– 0101 = Fun
– 0110 = Float
– 0111 = Export fun (make_fun/3)
– 1000 - 1010 = Binaries
– 1100 - 1110 = External entities (Pids, Ports and Refs)
#define BIN_MATCHSTATE_SUBTAG (0x1 << _TAG_PRIMARY_SIZE)
#define POS_BIG_SUBTAG (0x2 << _TAG_PRIMARY_SIZE) /* BIG: tags 2&3 */
#define NEG_BIG_SUBTAG (0x3 << _TAG_PRIMARY_SIZE) /* BIG: tags 2&3 */
#define _BIG_SIGN_BIT (0x1 << _TAG_PRIMARY_SIZE)
#define REF_SUBTAG (0x4 << _TAG_PRIMARY_SIZE) /* REF */
#define FUN_SUBTAG (0x5 << _TAG_PRIMARY_SIZE) /* FUN */
#define FLOAT_SUBTAG (0x6 << _TAG_PRIMARY_SIZE) /* FLOAT */
#define EXPORT_SUBTAG (0x7 << _TAG_PRIMARY_SIZE) /* FLOAT */
#define _BINARY_XXX_MASK (0x3 << _TAG_PRIMARY_SIZE)
#define REFC_BINARY_SUBTAG (0x8 << _TAG_PRIMARY_SIZE) /* BINARY */
#define HEAP_BINARY_SUBTAG (0x9 << _TAG_PRIMARY_SIZE) /* BINARY */
#define SUB_BINARY_SUBTAG (0xA << _TAG_PRIMARY_SIZE) /* BINARY */
#define MAP_SUBTAG (0xB << _TAG_PRIMARY_SIZE) /* MAP */
#define EXTERNAL_PID_SUBTAG (0xC << _TAG_PRIMARY_SIZE) /* EXTERNAL_PID */
#define EXTERNAL_PORT_SUBTAG (0xD << _TAG_PRIMARY_SIZE) /* EXTERNAL_PORT */
#define EXTERNAL_REF_SUBTAG (0xE << _TAG_PRIMARY_SIZE) /* EXTERNAL_REF */
Types:
ETERM **array;
int arrsize;
Creates an Erlang tuple from an array of Erlang terms.
array is an array of Erlang terms.
arrsize is the number of elements in array.
- 快速查询 O(1), 编译期间完成了对key的索引,对于小数据量存取相当快 (~50 values),
- 没有过多额外的内存消耗,只有Value和name 2+ N个字 (name + size+ N)
- 函数头完成匹配
http://www.cnblogs.com/me-sa/archive/2012/03/24/you-win-yourself-zen-this-is-the-50-erlang-article-go-on.html
http://www.cnblogs.com/me-sa/archive/2012/04/28/2474892.html
http://www.cnblogs.com/me-sa/archive/2012/06/06/2538941.html
[Erlang 0116] 当我们谈论Erlang Maps时,我们谈论什么 Part 1的更多相关文章
- [Erlang 0117] 当我们谈论Erlang Maps时,我们谈论什么 Part 2
声明:本文讨论的Erlang Maps是基于17.0-rc2,时间2014-3-4.后续Maps可能会出现语法或函数API上的有所调整,特此说明. 前情提要: [Erlang 0116] 当我们谈论E ...
- 当我们谈论Erlang Maps时,我们谈论什么 Part 2
声明:本文讨论的Erlang Maps是基于17.0-rc2,时间2014-3-4.兴许Maps可能会出现语法或函数API上的有所调整,特此说明. 前情提要: [Erlang 0116] 当我们谈论E ...
- 当我们谈论Erlang Maps时,我们谈论什么 Part 1
Erlang 添加 Maps数据类型并非非常突然,由于这个提议已经进行了2~3年之久,仅仅只是Joe Armstrong老爷子近期一篇文章Big changes to Erlang掀起不小了 ...
- [Erlang 0121] 当我们谈论Erlang Maps时,我们谈论什么 Part 3
Erlang/OTP 17.0 has been released http://www.erlang.org/download/otp_src_17.0.readme Erlang/OTP ...
- Erlang基础 -- 介绍 -- 历史及Erlang并发
前言 最近在总结一些Erlang编程语言的基础知识,拟系统的介绍Erlang编程语言,从基础到进阶,然后再做Erlang编程语言有意思的库的分析. 其实,还是希望越来越多的人关注Erlang,使用Er ...
- 话题讨论&征文--谈论大数据时我们在谈什么 获奖名单发布
从社会发展趋势的角度,非常明显大数据会是眼下肉眼可及的视野范围里能看到的最大趋势之中的一个.从传统IT 业到互联网.互联网到移动互联网,从以智能手机和Pad 为主要终端载体的移动互联网到可穿戴设备的移 ...
- [Erlang 0109] From Elixir to Erlang Code
Elixir代码最终编译成为erlang代码,这个过程是怎样的?本文通过一个小测试做下探索. 编译一旦完成,你就看到了真相 Elixir代码组织方式一方面和Erlang一样才用非常 ...
- [Erlang 0128] Term sharing in Erlang/OTP 下篇
继续昨天的话题,昨天提到io:format对数据共享的间接影响,如果是下面两种情况恐怕更容易成为"坑", 呃,恰好我都遇到过; 如果是测试代码是下面这样,得到的结果会是怎样?猜! ...
- [Erlang 0127] Term sharing in Erlang/OTP 上篇
之前,在 [Erlang 0126] 我们读过的Erlang论文 提到过下面这篇论文: On Preserving Term Sharing in the Erlang Virtual Machine ...
随机推荐
- ADO.NET Entity Framework 在哪些场景下使用?
在知乎回答了下,顺手转回来. Enity Framework已经是.NET下最主要的ORM了.而ORM从一个Mapping的概念开始,到现在已经得到了一定的升华,特别是EF等对ORM框架面向对象能力的 ...
- 再次学习 java 类的编译
做JAVA开发的都知道myeclipse, 我们在myeclipse中新建一个类,然后保存, 如何正常的话,那么在项目指定的目录(也就是项目的output目录)就会生成同名的class文件, 可是,我 ...
- 搭建一个简单的mybatis框架
一.Mybatis介绍 MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.MyBatis可以 ...
- 巧用javascript对象属性,向事件绑定的匿名函数内传递循环控制变量的值
遇到一个需要向匿名函数传递循环控制变量的问题,我受到园子里这篇文章的启发[笔记]js获取当前点击元素的索引,解决了这个问题.现在把代码贴出来,以防止自己忘记. if ($('#labModal').l ...
- 学习ASP.NET Core,你必须了解无处不在的“依赖注入”
ASP.NET Core的核心是通过一个Server和若干注册的Middleware构成的管道,不论是管道自身的构建,还是Server和Middleware自身的实现,以及构建在这个管道的应用,都需要 ...
- 读书笔记--SQL必知必会13--创建高级联结
13.1 使用表别名 SQL可以对列名.计算字段和表名起别名. 缩短SQL语句 允许在一条SELECT语句中多次使用相同的表. 注意:表别名只在查询执行中使用,不返回到客户端. MariaDB [sq ...
- 编写高质量代码:改善Java程序的151个建议(第4章:字符串___建议56~59)
建议56:自由选择字符串拼接方法 对一个字符串拼接有三种方法:加号.concat方法及StringBuilder(或StringBuffer ,由于StringBuffer的方法与StringBuil ...
- GO语言之channel
前言: 初识go语言不到半年,我是一次偶然的机会认识了golang这门语言,看到他简洁的语法风格和强大的语言特性,瞬间有了学习他的兴趣.我是很看好go这样的语言的,一方面因为他有谷歌主推,另一方面他确 ...
- webapi的学习资料
猿教程_-webapi教程-WebAPI教程 猿教程_-webapi教程-Web API概述 猿教程_-webapi教程-新建Web Api项目 猿教程_-webapi教程-测试Web API 猿教程 ...
- .Net语言 APP开发平台——Smobiler学习日志:快速实现应用中的图片、声音等文件上传功能
最前面的话:Smobiler是一个在VS环境中使用.Net语言来开发APP的开发平台,也许比Xamarin更方便 样式一 一.目标样式 我们要实现上图中的效果,需要如下的操作: 1.从工具栏上的&qu ...