node.js抓取数据(fake小爬虫)
在node.js中,有了 cheerio 模块、request 模块,抓取特定URL页面的数据已经非常方便。
一个简单的就如下
var request = require('request');
var cheerio = require('cheerio');
request(url,function(err,res){
if(err) return console.log(err);
var $ = cheerio.load(res.body.toString());
//解析页面内容
});
有了基本的流程,现在找个web地址(url)试试。就以博客园的搜索页为例。
通过搜索关键词 node.js

得到如下的URL:
http://zzk.cnblogs.com/s?t=b&w=node.js
点击第二页,URL如下:
http://zzk.cnblogs.com/s?t=b&w=node.js&p=2
分析URL,发现w= ?为要搜索的关键词 p= ?为页码。
借助 request 模块请求URL
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
});
现在URL有了,分析下URL对应的页面内容。

页面还是很有规律的。
标题 摘要 作者 发布时间 推荐次数 评论条数 浏览次数 文章链接
借助浏览器开发工具

发现 <div class="searchItem">...</div> 对应的是每篇文章
点开每一项,有如下内容
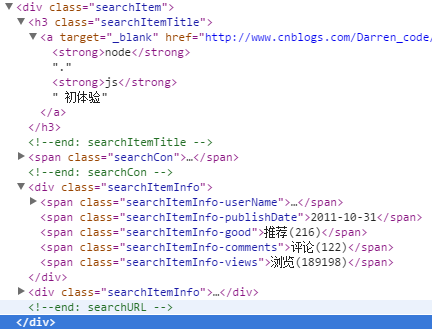
class="searchItemTitle" 包含的是文章标题、也包含了文章URL地址
class="searchItemInfo-userName" 包含的是作者
class="searchItemInfo-publishDate" 包含的是发布时间
class="searchItemInfo-views" 包含的是浏览次数
借助 cheerio 模块解析文章,抓取具体的内容
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
});
});
可以来运行下,看看是否正常抓取了数据。

现在有数据数据,可以保存到数据库。这里以mysql为例,其实用mongodb更方便。
借助 mysql 模块保存数据(假设数据库名为test,表为blog)。

var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err,result){
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
});
运行下,看看数据是否保存到数据库了。
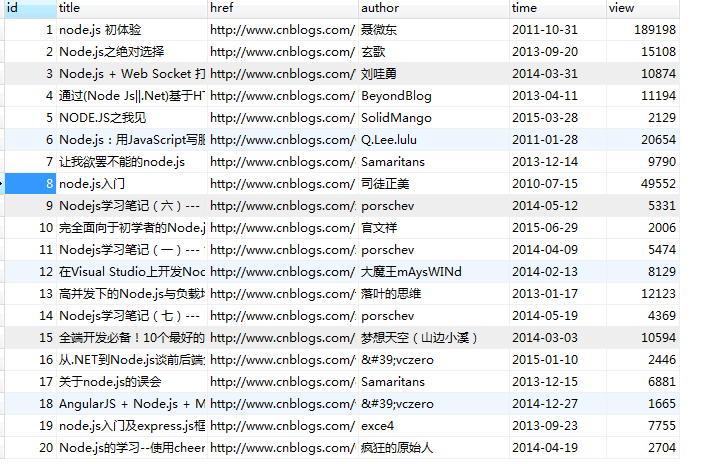
现在一个基本的抓取、保存都有了。但是呢 只抓取一次,而且只能抓取关键词为node.js 页码为1的URL页面。
改关键词为javascript,页码为1,清空blog表,再从新运行一次,看看表里是不是能保存javascript相关的数据。

现在去博客园搜索javascript,看看搜索到的结果和表里的内容能否对应。呵呵,不用看啦,肯定能对应啊~~
只能抓取一个页面的内容,肯定不能满足的,能自动抓取其他页的内容就更好了。
分析搜索页面,底部都有页码、下一页。

借助浏览器开发工具查看

我们发现最后一个a标签的内容有Next,表示下一页,看href有p=2,在第二分页p=3, ... 最后一页没有内容有Next的a标签了。
var nextA = $('.pager a').last(),
nextUrl = '';
if ($(nextA).text().indexOf('Next') > -1) {
nextUrl = nextA.attr('href');
page = nextUrl.slice(nextUrl.indexOf('p=') + 2);
//todo
} else {
db.end();
console.log('没有数据了...');
}
这里把程序代码做一点修改,封装成一个函数,完整如下:
var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
function fetchData(key, page) {
var url = 'http://zzk.cnblogs.com/s?t=b&w=' + key + '&p=' + page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err, result) {
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
//下一页
var nextA = $('.pager a').last(),
nextUrl = '';
if ($(nextA).text().indexOf('Next') > -1) {
nextUrl = nextA.attr('href');
page = nextUrl.slice(nextUrl.indexOf('p=') + 2);
setTimeout(function() {
fetchData(key, page);
}, 2000);
} else {
db.end();
console.log('没有数据了...');
}
});
}
fetchData('node.js', 1);
运行一下,开始抓数据了... 博客园搜索结果100个分页,每页20条数据,供2000条,程序间隔2秒抓取下一页,抓取一个搜索关键词2000条数据约3分20秒左右。
到此程序实现了抓取、保存数据。
如果是其他URL,需要重新解析页面内容,页面编码不是utf-8编码,需要转码,可以借助 iconv-lite 模块。
数据库有了数据,当然可以读取出来,比如按浏览次数多少排序输出来。
按需求,抓取数据,显示数据,助技术进步。
node.js抓取数据(fake小爬虫)的更多相关文章
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- Node.js 抓取电影天堂新上电影节目单及ftp链接
代码地址如下:http://www.demodashi.com/demo/12368.html 1 概述 本实例主要使用Node.js去抓取电影的节目单,方便大家使用下载. 2 node packag ...
- Node.js抓取网页
前几天四六级成绩出来(然而我没考),用Node.js做了一个模拟表单提交并抓取数据的Web 总结一下用到的知识,简单的网页抓取大概就是这个流程了 发送Get或Post请求 表单提交,首先弄到原网页提交 ...
- node.js 抓取网页数据
var $ = require('jquery'); var request = require('request'); request({ url: 'http:\\www.baidu.com',/ ...
- 使用node.js抓取有路网图书信息(原创)
之前写过使用python抓取有路网图书信息,见http://www.cnblogs.com/dyf6372/p/3529703.html. 最近想学习一下Node.js,所以想试试手,比较一下http ...
- python抓取数据 常见反爬虫 情况
1.报文头信息: User-Agent Accept-Language 防盗链 上referer 随机生成不同的User-Agent构造报头 2.加抓取等待时间 每抓取一页都让它随机休息几秒,加入此 ...
- node.js 抓取
http://blog.csdn.net/youyudehexie/article/details/11910465 http://www.tuicool.com/articles/z2YbAr ht ...
- 使用python抓取数据之菜鸟爬虫1
''' Created on 2018-5-27 @author: yaoshuangqi ''' #本代码获取百度乐彩网站上的信息,只获取最近100期的双色球 import urllib.reque ...
- node.js抓取网上图片保存到本地
用到两个模块,http和fs var http = require("http");var fs = require("fs"); var server = h ...
随机推荐
- VLine2.0——仿阿里巴巴VIPABC真人视频在线教育(基于Flash支持一对多多对多Web在线视频)
感兴趣的朋友可与我联系:acsebt@qq.com 一.登陆页 二.功能页
- Java设置的读书笔记和集合框架Collection API
一个.CollectionAPI 集合是一系列对象的聚集(Collection). 集合在程序设计中是一种重要的数据接口.Java中提供了有关集合的类库称为CollectionAPI. 集合实际上是用 ...
- bzoj(矩阵快速幂)
题意:定义Concatenate(1,N)=1234567……n.比如Concatenate(1,13)=12345678910111213.给定n和m,求Concatenate(1,n)%m. (1 ...
- [置顶] Firefox OS 学习——manifest.webapp结构分析
在Firefox OS 学习——Gaia 编译分析 这篇文章多次提到manifest.webapp文件,对于做过android app 开发的人来说,都很熟悉Android.mk 和Manifest ...
- Cocos2d-x教程(28)-ttf 字体库的使用
欢迎增加 Cocos2d-x 交流群: 193411763 转载请注明原文出处:http://blog.csdn.net/u012945598/article/details/37650843 通常为 ...
- SVN更改登录用户(转)
一) 原地址:http://www.ixna.net/articles/2606 //证书缓存 $ svn list https://host.example.com/repos/project Er ...
- POJ 1184 聪明的打字员
简直难到没朋友. 双向bfs + 剪枝. 剪枝策略: 对于2--5位置上的数,仅仅有当光标在相应位置时通过swap ,up.down来改变.那么当当前位置没有达到目标状态时,left和right无意义 ...
- U9文件与文件系统的压缩和打包
1.在Linux的环境中,压缩文件的扩展名大多为:*.tar,*.tar.gz,*.tgz,*.bz2. 2.gzip可以说是应用最广的压缩命令了.目前gzip可以揭开compress,zip和gzi ...
- freemarker导出word带图片
导出word带图片 如果你需要在word中添加图片,那你就在第一步制作模板时,加入一张图片占位,然后打开xml文档,可以看到如下的一片base64编码后的代码: <w:binData w:nam ...
- C++ Primer 学习笔记_44_STL实践与分析(18)--再谈迭代器【下】
STL实践与分析 --再谈迭代器[下] 三.反向迭代器[续:习题] //P355 习题11.19 int main() { vector<int> iVec; for (vector< ...