node.js抓取数据(fake小爬虫)
在node.js中,有了 cheerio 模块、request 模块,抓取特定URL页面的数据已经非常方便。
一个简单的就如下
var request = require('request');
var cheerio = require('cheerio');
request(url,function(err,res){
if(err) return console.log(err);
var $ = cheerio.load(res.body.toString());
//解析页面内容
});
有了基本的流程,现在找个web地址(url)试试。就以博客园的搜索页为例。
通过搜索关键词 node.js

得到如下的URL:
http://zzk.cnblogs.com/s?t=b&w=node.js
点击第二页,URL如下:
http://zzk.cnblogs.com/s?t=b&w=node.js&p=2
分析URL,发现w= ?为要搜索的关键词 p= ?为页码。
借助 request 模块请求URL
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
});
现在URL有了,分析下URL对应的页面内容。

页面还是很有规律的。
标题 摘要 作者 发布时间 推荐次数 评论条数 浏览次数 文章链接
借助浏览器开发工具

发现 <div class="searchItem">...</div> 对应的是每篇文章
点开每一项,有如下内容
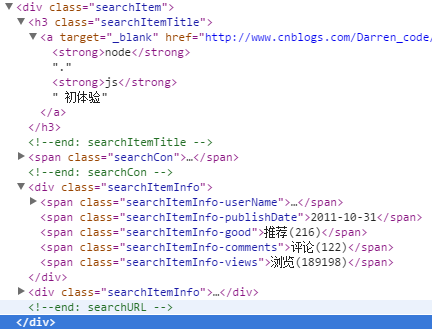
class="searchItemTitle" 包含的是文章标题、也包含了文章URL地址
class="searchItemInfo-userName" 包含的是作者
class="searchItemInfo-publishDate" 包含的是发布时间
class="searchItemInfo-views" 包含的是浏览次数
借助 cheerio 模块解析文章,抓取具体的内容
var request = require('request');
var cheerio = require('cheerio');
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
});
});
可以来运行下,看看是否正常抓取了数据。

现在有数据数据,可以保存到数据库。这里以mysql为例,其实用mongodb更方便。
借助 mysql 模块保存数据(假设数据库名为test,表为blog)。

var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
var key = 'node.js', page = 1;
var url = 'http://zzk.cnblogs.com/s?t=b&w='+ key +'&p='+ page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err,result){
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
});
运行下,看看数据是否保存到数据库了。
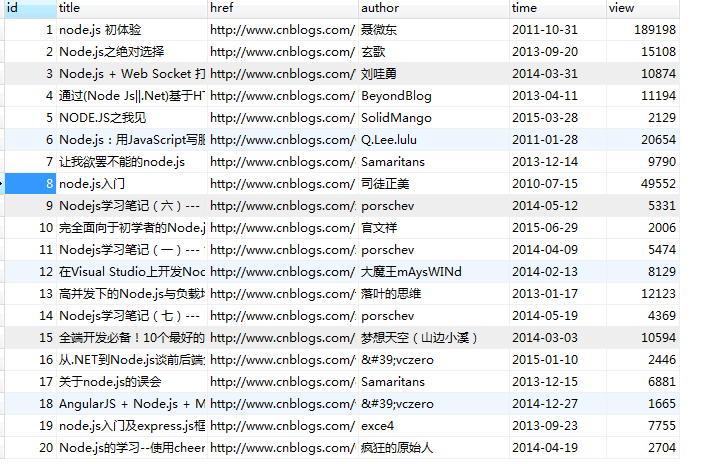
现在一个基本的抓取、保存都有了。但是呢 只抓取一次,而且只能抓取关键词为node.js 页码为1的URL页面。
改关键词为javascript,页码为1,清空blog表,再从新运行一次,看看表里是不是能保存javascript相关的数据。

现在去博客园搜索javascript,看看搜索到的结果和表里的内容能否对应。呵呵,不用看啦,肯定能对应啊~~
只能抓取一个页面的内容,肯定不能满足的,能自动抓取其他页的内容就更好了。
分析搜索页面,底部都有页码、下一页。

借助浏览器开发工具查看

我们发现最后一个a标签的内容有Next,表示下一页,看href有p=2,在第二分页p=3, ... 最后一页没有内容有Next的a标签了。
var nextA = $('.pager a').last(),
nextUrl = '';
if ($(nextA).text().indexOf('Next') > -1) {
nextUrl = nextA.attr('href');
page = nextUrl.slice(nextUrl.indexOf('p=') + 2);
//todo
} else {
db.end();
console.log('没有数据了...');
}
这里把程序代码做一点修改,封装成一个函数,完整如下:
var request = require('request');
var cheerio = require('cheerio');
var mysql = require('mysql');
var db = mysql.createConnection({
host: '127.0.0.1',
user: 'root',
password: '123456',
database: 'test'
});
db.connect();
function fetchData(key, page) {
var url = 'http://zzk.cnblogs.com/s?t=b&w=' + key + '&p=' + page;
request(url, function(err, res) {
if (err) return console.log(err);
var $ = cheerio.load(res.body.toString());
var arr = [];
//内容解析
$('.searchItem').each(function() {
var title = $(this).find('.searchItemTitle');
var author = $(this).find('.searchItemInfo-userName a');
var time = $(this).find('.searchItemInfo-publishDate');
var view = $(this).find('.searchItemInfo-views');
var info = {
title: $(title).find('a').text(),
href: $(title).find('a').attr('href'),
author: $(author).text(),
time: $(time).text(),
view: $(view).text().replace(/[^0-9]/ig, '')
};
arr.push(info);
//打印
console.log('============================= 输出开始 =============================');
console.log(info);
console.log('============================= 输出结束 =============================');
//保存数据
db.query('insert into blog set ?', info, function(err, result) {
if (err) throw err;
if (!!result) {
console.log('插入成功');
console.log(result.insertId);
} else {
console.log('插入失败');
}
});
});
//下一页
var nextA = $('.pager a').last(),
nextUrl = '';
if ($(nextA).text().indexOf('Next') > -1) {
nextUrl = nextA.attr('href');
page = nextUrl.slice(nextUrl.indexOf('p=') + 2);
setTimeout(function() {
fetchData(key, page);
}, 2000);
} else {
db.end();
console.log('没有数据了...');
}
});
}
fetchData('node.js', 1);
运行一下,开始抓数据了... 博客园搜索结果100个分页,每页20条数据,供2000条,程序间隔2秒抓取下一页,抓取一个搜索关键词2000条数据约3分20秒左右。
到此程序实现了抓取、保存数据。
如果是其他URL,需要重新解析页面内容,页面编码不是utf-8编码,需要转码,可以借助 iconv-lite 模块。
数据库有了数据,当然可以读取出来,比如按浏览次数多少排序输出来。
按需求,抓取数据,显示数据,助技术进步。
node.js抓取数据(fake小爬虫)的更多相关文章
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- Node.js 抓取电影天堂新上电影节目单及ftp链接
代码地址如下:http://www.demodashi.com/demo/12368.html 1 概述 本实例主要使用Node.js去抓取电影的节目单,方便大家使用下载. 2 node packag ...
- Node.js抓取网页
前几天四六级成绩出来(然而我没考),用Node.js做了一个模拟表单提交并抓取数据的Web 总结一下用到的知识,简单的网页抓取大概就是这个流程了 发送Get或Post请求 表单提交,首先弄到原网页提交 ...
- node.js 抓取网页数据
var $ = require('jquery'); var request = require('request'); request({ url: 'http:\\www.baidu.com',/ ...
- 使用node.js抓取有路网图书信息(原创)
之前写过使用python抓取有路网图书信息,见http://www.cnblogs.com/dyf6372/p/3529703.html. 最近想学习一下Node.js,所以想试试手,比较一下http ...
- python抓取数据 常见反爬虫 情况
1.报文头信息: User-Agent Accept-Language 防盗链 上referer 随机生成不同的User-Agent构造报头 2.加抓取等待时间 每抓取一页都让它随机休息几秒,加入此 ...
- node.js 抓取
http://blog.csdn.net/youyudehexie/article/details/11910465 http://www.tuicool.com/articles/z2YbAr ht ...
- 使用python抓取数据之菜鸟爬虫1
''' Created on 2018-5-27 @author: yaoshuangqi ''' #本代码获取百度乐彩网站上的信息,只获取最近100期的双色球 import urllib.reque ...
- node.js抓取网上图片保存到本地
用到两个模块,http和fs var http = require("http");var fs = require("fs"); var server = h ...
随机推荐
- Ubuntu Manpage: ajaxterm - Web based terminal written in python
Ubuntu Manpage: ajaxterm - Web based terminal written in python hardy (1) ajaxterm.1.gz Provided by: ...
- 【 D3.js 入门系列 --- 8 】 对话操作(事件)
本人的个人博客为: www.ourd3js.com csdn博客为: blog.csdn.net/lzhlzz 转载请注明出处,谢谢. 这一节介绍怎样进行对话的操作,如鼠标单击,鼠标滑过等. 对一个被 ...
- codeforces#253 D - Andrey and Problem里的数学知识
这道题是这种,给主人公一堆事件的成功概率,他仅仅想恰好成功一件. 于是,问题来了,他要选择哪些事件去做,才干使他的想法实现的概率最大. 我的第一个想法是枚举,枚举的话我想到用dfs,但是认为太麻烦. ...
- 服务器编程入门(2)IP协议详解
问题聚焦: IP协议是TCP/IP协议族的核心协议,也是socket网络编程的基础之一.这里从两个方面较为深入地探讨IP协议: 1,IP头部信息(指定IP通信的源端IP地址,目的端IP ...
- SAE微信公众号PHP SDK, token一直验证失败
用的是SAE,创建的是微信公众号PHP SDK框架,里面example文件夹下有server.php用来验证token的.但是问题来了,无论我怎么输入URL和token,一直告诉我token验证失败. ...
- hdu4705(树形dp)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4705 题意: 有一颗树, 选出3个点. 不在同一条路径上的集合数. 分析:这题主要能逆向思考下,用总的 ...
- POJ1470 Closest Common Ancestors 【Tarjan的LCA】
非常裸的模版题,只是Tarjan要好好多拿出来玩味几次 非常有点巧妙呢,tarjan,大概就是当前结点和它儿子结点的羁绊 WA了俩小时,,,原因是,这个题是多数据的(还没告诉你T,用scanf!=EO ...
- Failed to load libGL.so问题解决
Ubuntu 14.04下启动模拟设备Android 4.2.2的时候报错: failed to load libgl.so 先用locate 命令定位libGL库, 然后加入�一个链接就可以: de ...
- 经典回忆Effective C++ 1
c++ 联邦语言: typedef { unit C; unit Object-Oriented C++; unit Template C++; unit STL; }; notice: C++高效编 ...
- Knockout应用开发指南 第七章:Mapping插件
原文:Knockout应用开发指南 第七章:Mapping插件 Mapping插件 Knockout设计成允许你使用任何JavaScript对象作为view model.必须view model的一些 ...