Secondary Namenode - What it really do?
原文链接:http://blog.madhukaraphatak.com/secondary-namenode---what-it-really-do/
Secondary Namenode is one of the poorly named component in Hadoop. By its name, it gives a sense that its a backup for the Namenode.But in reality its not. Lot of beginners in Hadoop get confused about what exactly SecondaryNamenode does and why its present in HDFS.So in this blog post I try to explain the role of secondary namenode in HDFS.
By its name, you may assume that it has something to do with Namenode and you are right. So before we dig into Secondary Namenode lets see what exactly Namenode does.
Namenode
Namenode holds the meta data for the HDFS like Namespace information, block information etc. When in use, all this information is stored in main memory. But these information also stored in disk for persistence storage.
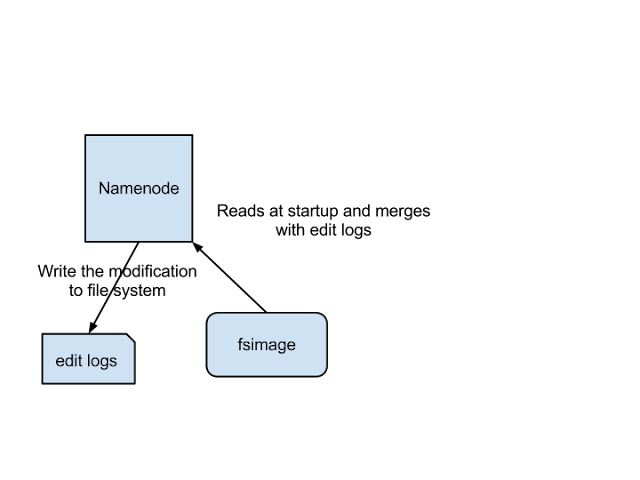
The above image shows how Name Node stores information in disk.
Two different files are
- fsimage - Its the snapshot of the filesystem when namenode started
- Edit logs - Its the sequence of changes made to the filesystem after namenode started
Only in the restart of namenode , edit logs are applied to fsimage to get the latest snapshot of the file system. But namenode restart are rare in production clusters which means edit logs can grow very large for the clusters where namenode runs for a long period of time. The following issues we will encounter in this situation.
- Editlog become very large , which will be challenging to manage it
- Namenode restart takes long time because lot of changes has to be merged
- In the case of crash, we will lost huge amount of metadata since fsimage is very old
So to overcome this issues we need a mechanism which will help us reduce the edit log size which is manageable and have up to date fsimage ,so that load on namenode reduces . It’s very similar to Windows Restore point, which will allow us to take snapshot of the OS so that if something goes wrong , we can fallback to the last restore point.
So now we understood NameNode functionality and challenges to keep the meta data up to date.So what is this all have to with Seconadary Namenode?
Secondary Namenode
Secondary Namenode helps to overcome the above issues by taking over responsibility of merging editlogs with fsimage from the namenode.
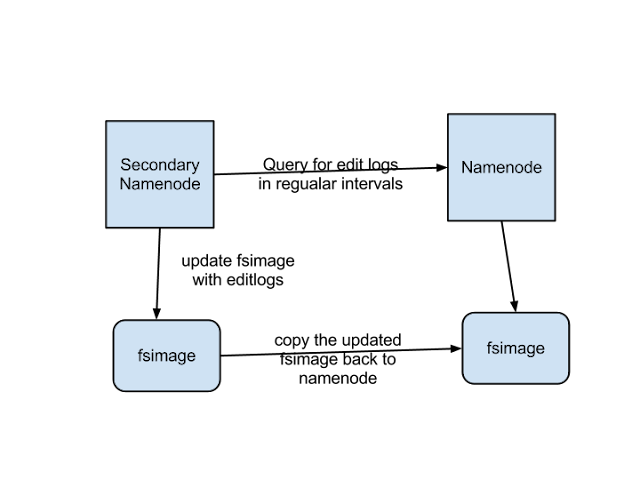
The above figure shows the working of Secondary Namenode
- It gets the edit logs from the namenode in regular intervals and applies to fsimage
- Once it has new fsimage, it copies back to namenode
- Namenode will use this fsimage for the next restart,which will reduce the startup time
Secondary Namenode whole purpose is to have a checkpoint in HDFS. Its just a helper node for namenode.That’s why it also known as checkpoint node inside the community.
So we now understood all Secondary Namenode does puts a checkpoint in filesystem which will help Namenode to function better. Its not the replacement or backup for the Namenode. So from now on make a habit of calling it as a checkpoint node.
Secondary Namenode - What it really do?的更多相关文章
- Secondary NameNode:的作用?
前言 最近刚接触Hadoop, 一直没有弄明白NameNode和Secondary NameNode的区别和关系.很多人都认为,Secondary NameNode是NameNode的备份,是为了防止 ...
- Hadoop之Secondary NameNode
NameNode存储文件系统的变化作为log追加在本地的一个文件里:这个文件是edits.当一个NameNode启动时,它从一个映像文件:FsImage,读取HDFS的状态,使用来自edits日志文件 ...
- 解读Secondary NameNode的功能
1.概述 最近有朋友问我Secondary NameNode的作用,是不是NameNode的备份?是不是为了防止NameNode的单点问题?确实,刚接触Hadoop,从字面上看,很容易会把Second ...
- Secondary NameNode 的作用
https://blog.csdn.net/xh16319/article/details/31375197 很多人都认为,Secondary NameNode是NameNode的备份,是为了防止Na ...
- (转)Secondary NameNode的作用
在Hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一.从它的名字上看,它给人的感觉就像是NameNode的备份.但它实际上却不是.很多Hadoop的初学者都很疑惑,S ...
- 010 secondary namenode(同步元数据和日志)
1.格式化 首先格式化之后只剩下一个根目录. 格式化后会出现元数据 集群启动之后,元数据放在内存中的(消耗内存中) 格式化后会产生镜像文件fsimage,元数据存储 启动的时候namenode会读取镜 ...
- Secondary NameNode究竟是做什么的
Secondary NameNode:它究竟有什么作用? 在hadoop中,有一些命名不好的模块,Secondary NameNode是其中之一.从它的名字上看,它给人的感觉就像是NameNode的备 ...
- Hadoop- NameNode和Secondary NameNode元数据管理机制
元数据的存储机制 A.内存中有一份完整的元数据(内存meta data) B.磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中) C.用于衔接内存metadata ...
- NameNode && Secondary NameNode工作机制
NameNode && Secondary NameNode工作机制 1)工作流程 2) fsimage和edits NameNode是HDFS的大脑,它维护着整个文件系统的目录树, ...
随机推荐
- WITH (NOLOCK)浅析
SQL Server 中WITH (NOLOCK)浅析 2014-08-30 11:58 by 潇湘隐者, 503 阅读, 2 评论, 收藏, 编辑 概念介绍 开发人员喜欢在SQL脚本中使用WITH( ...
- asp.net mvc使用validate.js验证 若name属性包含特殊字符则加上双引号即可
rules: { "Can.CName": { required: true, ...
- 查询select
--------------select查询-------------------查询所有信息(方法一)select * from stuinfo --*号代表所有列--查询所有信息(方法二)sele ...
- Varnish缓存服务
Varnish缓存服务详解及应用实现 1.varnish的基本介绍 Varnish 的作者Poul-Henning Kamp是FreeBSD的内核开发者之一,他认为现在的计算机比起1975年已 ...
- SQL Server 2014 新特性:IO资源调控
谈谈我的微软特约稿:<SQL Server 2014 新特性:IO资源调控> 2014-07-01 10:19 by 听风吹雨, 570 阅读, 16 评论, 收藏, 收藏 一.本文所涉及 ...
- HBase Maven 工程模块梳理
HBase Maven 工程各个 Model 功能说明: github 地址:git://git.apache.org/hbase.git 版本:2.0.0-SNAPSHOT hbase-annota ...
- android通过程序收起通知栏
1. 添加权限 <uses-permission android:name="android.permission.EXPAND_STATUS_BAR" /> 2. ...
- [RM 状态机详解3]RMContainer状态机详解
摘要 RMContainer是RM内部维护的Container状态.事实上,在RM的调度器中,会维护着一个liveContainers列表,保存着所有存活着的Container信息.图1显示RMCon ...
- 从异步更新进度想起的事儿——IProgress
今天,在群里向大家请教了这样一个问题:“两个对象(类.窗体或什么)之间,要完成比较频繁的报告进度更新都有哪些好的方式”,Somebody 跳出来给出了个“IProgress”,没了解过,后面围绕着它讨 ...
- 用django搭建一个简易blog系统(翻译)(一)
Django 入门 原始网址: http://www.creativebloq.com/netmag/get-started-django-7132932 代码:https://github.com/ ...