java利用url实现网页内容的抓取
闲来无事,刚学会把git部署到远程服务器,没事做,所以简单做了一个抓取网页信息的小工具,里面的一些数值如果设成参数的话可能扩展性能会更好!希望这是一个好的开始把,也让我对字符串的读取掌握的更加熟练了,值得注意的是JAVA1.8 里面在使用String拼接字符串的时候,会自动把你要拼接的字符串用StringBulider来处理,大大优化了String 的性能,闲话不多说,show my XXX code~
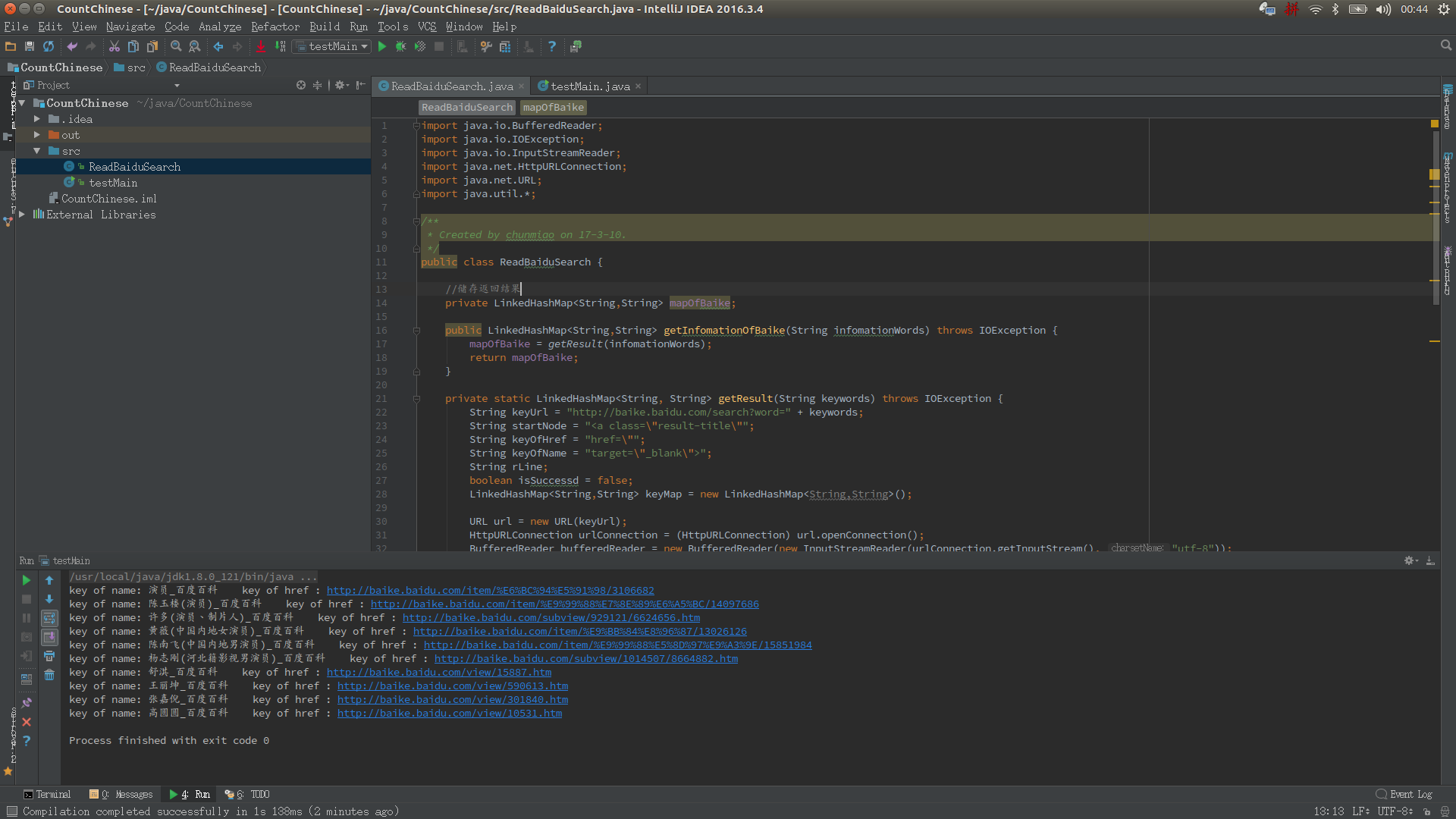
运行效果:
首先打开百度百科,搜索词条,比如“演员”,再按F12查看源码
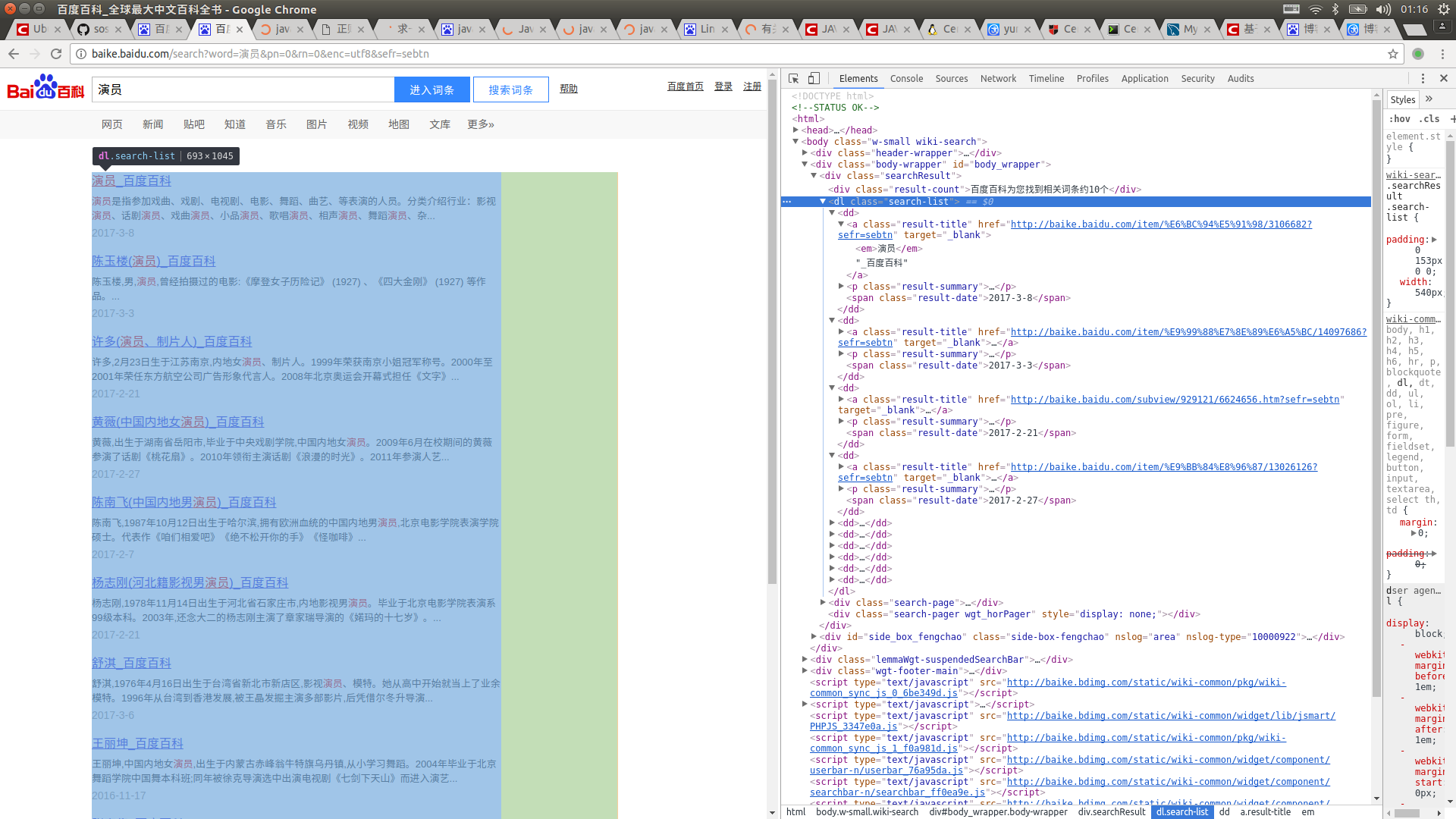
然后抓取你想要的标签,注入LinkedHashMap里面就ok了,很简单是吧!看看代码罗
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.*; /**
* Created by chunmiao on 17-3-10.
*/
public class ReadBaiduSearch { //储存返回结果
private LinkedHashMap<String,String> mapOfBaike; //获取搜索信息
public LinkedHashMap<String,String> getInfomationOfBaike(String infomationWords) throws IOException {
mapOfBaike = getResult(infomationWords);
return mapOfBaike;
} //通过网络链接获取信息
private static LinkedHashMap<String, String> getResult(String keywords) throws IOException {
//搜索的url
String keyUrl = "http://baike.baidu.com/search?word=" + keywords;
//搜索词条的节点
String startNode = "<dl class=\"search-list\">";
//词条的链接关键字
String keyOfHref = "href=\"";
//词条的标题关键字
String keyOfTitle = "target=\"_blank\">"; String endNode = "</dl>"; boolean isNode = false; String title; String href; String rLine; LinkedHashMap<String,String> keyMap = new LinkedHashMap<String,String>(); //开始网络请求
URL url = new URL(keyUrl);
HttpURLConnection urlConnection = (HttpURLConnection) url.openConnection();
InputStreamReader inputStreamReader = new InputStreamReader(urlConnection.getInputStream(),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader); //读取网页内容
while ((rLine = bufferedReader.readLine()) != null){
//判断目标节点是否出现
if(rLine.contains(startNode)){
isNode = true;
}
//若目标节点出现,则开始抓取数据
if (isNode){
//若目标结束节点出现,则结束读取,节省读取时间
if (rLine.contains(endNode)) {
//关闭读取流
bufferedReader.close();
inputStreamReader.close();
break;
}
//若值为空则不读取
if (((title = getName(rLine,keyOfTitle)) != "") && ((href = getHref(rLine,keyOfHref)) != "")){
keyMap.put(title,href);
}
}
}
return keyMap;
} //获取词条对应的url
private static String getHref(String rLine,String keyOfHref){
String baikeUrl = "http://baike.baidu.com";
String result = "";
if(rLine.contains(keyOfHref)){
//获取url
for (int j = rLine.indexOf(keyOfHref) + keyOfHref.length();j < rLine.length()&&(rLine.charAt(j) != '\"');j ++){
result += rLine.charAt(j);
}
//获取的url中可能不含baikeUrl,如果没有则在头部添加一个
if(!result.contains(baikeUrl)){
result = baikeUrl + result;
}
}
return result;
} //获取词条对应的名称
private static String getName(String rLine,String keyOfTitle){
String result = "";
//获取标题内容
if(rLine.contains(keyOfTitle)){
result = rLine.substring(rLine.indexOf(keyOfTitle) + keyOfTitle.length(),rLine.length());
//将标题中的内容含有的标签去掉
result = result.replaceAll("<em>|</em>|</a>|<a>","");
}
return result;
} }
现在都好晚了,去睡觉了...
java利用url实现网页内容的抓取的更多相关文章
- 【JAVA系列】Google爬虫如何抓取JavaScript的?
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[JAVA系列]Google爬虫如何抓取Java ...
- java平台利用jsoup开发包,抓取优酷视频播放地址与图片地址等信息。
/******************************************************************************************** * aut ...
- 使用java开源工具httpClient及jsoup抓取解析网页数据
今天做项目的时候遇到这样一个需求,需要在网页上展示今日黄历信息,数据格式如下 公历时间:2016年04月11日 星期一 农历时间:猴年三月初五 天干地支:丙申年 壬辰月 癸亥日 宜:求子 祈福 开光 ...
- HtmlUnitDriver 网页内容动态抓取
#抓取内容 WebDriver driver = new HtmlUnitDriver(false); driver.get(url); String html = driver.getPageSou ...
- java网络爬虫实现信息的抓取
转载请注明出处:http://blog.csdn.NET/lmj623565791/article/details/23272657 今天公司有个需求,需要做一些指定网站查询后的数据的抓取,于是花了点 ...
- java利用URL发送get和post请求
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import ...
- python3下scrapy爬虫(第四卷:初步抓取网页内容之抓取网页里的指定数据延展方法)
上卷中我运用创建HtmlXPathSelector 对象进行抓取数据: 现在咱们再试一下其他的方法,先试一下我得最爱XPATH 看下结果: 直接打印出结果了 我现在就正常拼下路径 只求打印结果: 现在 ...
- python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接 现在我再新建个爬虫文件,名称设置为crawler2 做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrap ...
- 网络爬虫:利用selenium,pyquery库抓取并处理京东上的图片并存储到使用mongdb数据库进行存储
一,环境的搭建已经简单的工具介绍 1.selenium,一个用于Web应用程序测试的工具.其特点是直接运行在浏览器中,就像真正的用户在操作一样.新版本selenium2集成了 Selenium 1.0 ...
随机推荐
- 在LINUX上创建GIT服务器
转载 如果使用git的人数较少,可以使用下面的步骤快速部署一个git服务器环境. 1. 生成 SSH 公钥 每个需要使用git服务器的工程师,自己需要生成一个ssh公钥进入自己的~/.ssh目录,看有 ...
- (一)Lua脚本语言入门
今天开始自己的Lua语言学习,Lua脚本语言,是介于应用程序和开发其应用程序的底层编程语言之间,,它很方便调用其它语言,它只是在载入时对其进行编译,而不像我们写的单片机程序是预编译的,先编译好然后写入 ...
- Python用类实现串以及对串的方法进行单元测试
串是一种常见的数据结构,这里使用Python定义类来实现相应的方法.先看代码,再对相关知识进行讲解. # coding=utf-8 __all__=['ADTString'] class ADTStr ...
- 你不知道的document.write
使用document.write向文档输出写内容; document.write用法:document.write("要输出的内容"); 其实document.write()有两种 ...
- 微端游戏启动器launcher的制作(序篇)
公司要做一个游戏接入腾讯QQ游戏大厅,腾讯要求制作一个launcher,公司之前并没有接入过腾讯,所以大家其实都不懂,而我又是新人,所以刚拿到这个任务的时候整个人就是一个大写的懵逼.在网上查找了不少的 ...
- JAVA内存关注总结,作为个程序员需要对自己系统的每块内存做到了如指掌
服务器的JAVA进程使用的内存是否正常 服务器中,JAVA进程的内存占用= JVM内存+ JAVA堆最大内存大小(Xmx)+JAVA堆外内存大小+栈区( 线程数* Xss) 最需要关注: 1., 服务 ...
- 在Ubuntu12.0至14.04版本之间用Apache搭建网站运行环境
为了顺利安装各种软件,先更新下系统. apt-get update 安装Apache服务 apt-get install apache2 -y 安装php apt-get install php5 - ...
- angular实现跨域
angular.js 自带jsonp,实现跨域,下面来实搜索框的下拉列表,使用百度和360分别尝试一下 百度:url截取之后红色部分需替换 :https://sp0.baidu.com/5a1Fazu ...
- vs2010 入门程序
#include <stdio.h> int main(){ printf("hello world!\n"); getchar(); //此处避免执行完程序自动退出 ...
- CreateWindow的出错解决
CreateWindow返回NULL,而且GetLastError()也返回0,代码如下: WNDCLASSEX wc = { sizeof( WNDCLASSEX ), CS_CLASSDC, N ...