std::copy性能分析与memmove机器级实现
复制数据的快速方法std::copy
C++复制数据各种方法大家都会,很多时候我们都会用到std::copy这个STL函数,这个效率确实很不错,比我们一个一个元素复制或者用迭代器复制都来的要快很多。
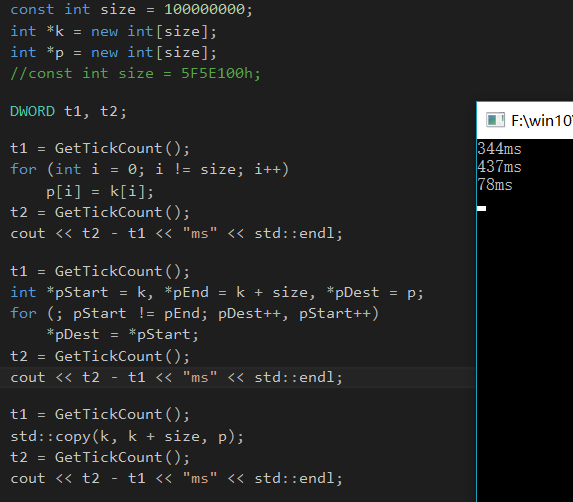
const int size = ;
int *k = new int[size];
int *p = new int[size];
//const int size = 5F5E100h; DWORD t1, t2; t1 = GetTickCount();
for (int i = ; i != size; i++)
p[i] = k[i];
t2 = GetTickCount();
cout << t2 - t1 << "ms" << std::endl; t1 = GetTickCount();
int *pStart = k, *pEnd = k + size, *pDest = p;
for (; pStart != pEnd; pDest++, pStart++)
*pDest = *pStart;
t2 = GetTickCount();
cout << t2 - t1 << "ms" << std::endl; t1 = GetTickCount();
std::copy(k, k + size, p);
t2 = GetTickCount();
cout << t2 - t1 << "ms" << std::endl;
for (int i = ; i != size; i++)
00F0A8B1 mov dword ptr [ebp-54h],
00F0A8B8 jmp main+0A3h (0F0A8C3h)
00F0A8BA mov eax,dword ptr [ebp-54h]
00F0A8BD add eax,
00F0A8C0 mov dword ptr [ebp-54h],eax
00F0A8C3 cmp dword ptr [ebp-54h],5F5E100h
00F0A8CA je main+0C0h (0F0A8E0h)
p[i] = k[i];
00F0A8CC mov eax,dword ptr [ebp-54h]
00F0A8CF mov ecx,dword ptr [p]
00F0A8D2 mov edx,dword ptr [ebp-54h]
00F0A8D5 mov esi,dword ptr [k]
00F0A8D8 mov edx,dword ptr [esi+edx*]
00F0A8DB mov dword ptr [ecx+eax*],edx
00F0A8DE jmp main+9Ah (0F0A8BAh)
int *pStart = k, *pEnd = k + size, *pDest = p;
00F0A944 mov eax,dword ptr [k]
00F0A947 mov dword ptr [pStart],eax
00F0A94A mov eax,dword ptr [k]
00F0A94D add eax,17D78400h
00F0A952 mov dword ptr [pEnd],eax
00F0A955 mov eax,dword ptr [p]
00F0A958 mov dword ptr [pDest],eax
for (; pStart != pEnd; pDest++, pStart++)
00F0A95B jmp main+14Fh (0F0A96Fh)
00F0A95D mov eax,dword ptr [pDest]
00F0A960 add eax,
00F0A963 mov dword ptr [pDest],eax
00F0A966 mov ecx,dword ptr [pStart]
00F0A969 add ecx,
00F0A96C mov dword ptr [pStart],ecx
00F0A96F mov eax,dword ptr [pStart]
00F0A972 cmp eax,dword ptr [pEnd]
00F0A975 je main+163h (0F0A983h)
*pDest = *pStart;
00F0A977 mov eax,dword ptr [pDest]
00F0A97A mov ecx,dword ptr [pStart]
00F0A97D mov edx,dword ptr [ecx]
00F0A97F mov dword ptr [eax],edx
00F0A981 jmp main+13Dh (0F0A95Dh)
template<class _InIt,
class _OutIt> inline
_OutIt _Copy_memmove(_InIt _First, _InIt _Last,
_OutIt _Dest)
{ // implement copy-like function as memmove
const char * const _First_ch = reinterpret_cast<const char *>(_First);
const char * const _Last_ch = reinterpret_cast<const char *>(_Last);
char * const _Dest_ch = reinterpret_cast<char *>(_Dest);
const size_t _Count = _Last_ch - _First_ch;
_CSTD memmove(_Dest_ch, _First_ch, _Count);
return (reinterpret_cast<_OutIt>(_Dest_ch + _Count));
}
template<class _InIt,
class _OutIt> inline
_OutIt _Copy_unchecked1(_InIt _First, _InIt _Last,
_OutIt _Dest, _General_ptr_iterator_tag)
{ // copy [_First, _Last) to [_Dest, ...), arbitrary iterators
for (; _First != _Last; ++_Dest, (void)++_First)
*_Dest = *_First;
return (_Dest);
}
template<class _InIt,
class _OutIt> inline
_OutIt _Copy_unchecked1(_InIt _First, _InIt _Last,
_OutIt _Dest, _Trivially_copyable_ptr_iterator_tag)
{ // copy [_First, _Last) to [_Dest, ...), pointers to trivially copyable
return (_Copy_memmove(_First, _Last, _Dest));
}
template<class _InIt,
class _OutIt> inline
_OutIt _Copy_unchecked(_InIt _First, _InIt _Last,
_OutIt _Dest)
{ // copy [_First, _Last) to [_Dest, ...)
// note: _Copy_unchecked is called directly elsewhere in the STL
return (_Copy_unchecked1(_First, _Last,
_Dest, _Ptr_copy_cat(_First, _Dest)));
}
template<class _InIt,
class _OutIt> inline
_OutIt _Copy_no_deprecate1(_InIt _First, _InIt _Last,
_OutIt _Dest, input_iterator_tag, _Any_tag)
{ // copy [_First, _Last) to [_Dest, ...), arbitrary iterators
return (_Rechecked(_Dest,
_Copy_unchecked(_First, _Last, _Unchecked_idl0(_Dest))));
}
template<class _InIt,
class _OutIt> inline
_OutIt _Copy_no_deprecate1(_InIt _First, _InIt _Last,
_OutIt _Dest, random_access_iterator_tag, random_access_iterator_tag)
{ // copy [_First, _Last) to [_Dest, ...), random-access iterators
_CHECK_RANIT_RANGE(_First, _Last, _Dest);
return (_Rechecked(_Dest,
_Copy_unchecked(_First, _Last, _Unchecked(_Dest))));
}
template<class _InIt,
class _OutIt> inline
_OutIt _Copy_no_deprecate(_InIt _First, _InIt _Last,
_OutIt _Dest)
{ // copy [_First, _Last) to [_Dest, ...), no _SCL_INSECURE_DEPRECATE_FN warnings
_DEBUG_RANGE_PTR(_First, _Last, _Dest);
return (_Copy_no_deprecate1(_Unchecked(_First), _Unchecked(_Last),
_Dest, _Iter_cat_t<_InIt>(), _Iter_cat_t<_OutIt>()));
}
template<class _InIt,
class _OutIt> inline
_OutIt copy(_InIt _First, _InIt _Last,
_OutIt _Dest)
{ // copy [_First, _Last) to [_Dest, ...)
_DEPRECATE_UNCHECKED(copy, _Dest);
return (_Copy_no_deprecate(_First, _Last, _Dest));
}
return (_Copy_no_deprecate1(_Unchecked(_First), _Unchecked(_Last),
_Dest, _Iter_cat_t<_InIt>(), _Iter_cat_t<_OutIt>()));
template<class _Iter>
using _Iter_cat_t = typename iterator_traits<_Iter>::iterator_category;
input_iterator_tag //输入迭代器,单向一次一步移动,读取一次output_iterator_tag //输出迭代器,单向一次一步移动,涂写一次forward_iterator_tag //向前迭代器,单向一次一步移动,多次读写,继承自输入迭代器bidirectional_iterator_tag //双向迭代器,双向一次一步移动,多次读写,继承自向前迭代器random_access_iterator_tag //随机迭代器,任意位置多次读写,继承自双向迭代器
template<class _Source,
class _Dest> inline
_General_ptr_iterator_tag _Ptr_copy_cat(const _Source&, const _Dest&)
{ // return pointer copy optimization category for arbitrary iterators
return {};
}
template<class _Source,
class _Dest> inline
conditional_t<is_trivially_assignable<_Dest&, _Source&>::value,
typename _Ptr_cat_helper<remove_const_t<_Source>, _Dest>::type,
_General_ptr_iterator_tag>
_Ptr_copy_cat(_Source * const&, _Dest * const&)
{ // return pointer copy optimization category for pointers
return {};
}
_CSTD memmove(_Dest_ch, _First_ch, _Count);
当源内存的首地址等于目标内存的首地址时,不进行任何拷贝当源内存的首地址大于目标内存的首地址时,实行正向拷贝当源内存的首地址小于目标内存的首地址时,实行反向拷贝
这三个指令每一次执行都会将源地址到目的地址的数据的复制目标地址由di决定(对于movsb,movsw是di,movsd是edi),每执行一次,根据DF的值+1(DF == 0)或者-1(DF ==1)源地址由si决定(对于movsb,movsw是si,movsd是esi),每执行一次,根据DF的值+1(DF == 0)或者-1(DF ==1)
__asm
{
mov esi, dword ptr[k];
mov edi, dword ptr[p];
mov ecx, 5F5E100h;
rep movsd;
};
好吧,其实上面是memcpy。如果要实现memmove,还需要多进行一些判断,就像memmove要求的那样
事实上,我们只要单步调试就可以看到memmove执行的代码了,在VS里面看,的确是进行了汇编优化(注意VS编译器用的memmove的并不是在memmove.c定义的C的版本,而是在memcpy.asm的汇编版本),在我们的例子中,汇编代码如下:
ifdef MEM_MOVE
_MEM_ equ <memmove>
else ; MEM_MOVE
_MEM_ equ <memcpy>
endif ; MEM_MOVE % public _MEM_
_MEM_ proc \
dst:ptr byte, \
src:ptr byte, \
count:IWORD ; destination pointer
; source pointer
; number of bytes to copy OPTION PROLOGUE:NONE, EPILOGUE:NONE push edi ; save edi
push esi ; save esi ; size param/4 prolog byte #reg saved
.FPO ( , , $-_MEM_ , , , ) mov esi,[esp + 010h] ; esi = source
mov ecx,[esp + 014h] ; ecx = number of bytes to move
mov edi,[esp + 0Ch] ; edi = dest ;
; Check for overlapping buffers:
; If (dst <= src) Or (dst >= src + Count) Then
; Do normal (Upwards) Copy
; Else
; Do Downwards Copy to avoid propagation
; mov eax,ecx ; eax = byte count mov edx,ecx ; edx = byte count
add eax,esi ; eax = point past source end cmp edi,esi ; dst <= src ?
jbe short CopyUp ; no overlap: copy toward higher addresses cmp edi,eax ; dst < (src + count) ?
jb CopyDown ; overlap: copy toward lower addresses ;
; Buffers do not overlap, copy toward higher addresses. CopyUp:
cmp ecx, 020h
jb CopyUpDwordMov ; size smaller than 32 bytes, use dwords
cmp ecx, 080h
jae CopyUpLargeMov ; if greater than or equal to 128 bytes, use Enhanced fast Strings
bt __isa_enabled, __ISA_AVAILABLE_SSE2
jc XmmCopySmallTest
jmp Dword_align CopyUpLargeMov:
bt __favor, __FAVOR_ENFSTRG ; check if Enhanced Fast Strings is supported
jnc CopyUpSSE2Check ; if not, check for SSE2 support
rep movsb
mov eax,[esp + 0Ch] ; return original destination pointer
pop esi
pop edi
M_EXIT
因为我们的例子中没有重叠的内存区,而且大小也比128bytes要大,自然就进入了CopyUpLargeMov过程,我们可以很清楚地发现rep movsb了,memmove实现过程就是我们所想的那样。实际上memmove汇编版本还有其他大量的优化,有兴趣的朋友可以点进去memcpy.asm去看一看。
这样感觉很不错,用movsd指令以后我们可以很直观地发现我们已经减少了很多无谓的寄存器赋值操作(movsd指令还有被CPU进行加速的)我们接下来试下效果:

std::copy性能分析与memmove机器级实现的更多相关文章
- 系统级性能分析工具perf的介绍与使用
测试环境:Ubuntu16.04(在VMWare虚拟机使用perf top存在无法显示问题) Kernel:3.13.0-32 系统级性能优化通常包括两个阶段:性能剖析(performance pro ...
- 系统级性能分析工具perf的介绍与使用[转]
测试环境:Ubuntu16.04(在VMWare虚拟机使用perf top存在无法显示问题) Kernel:3.13.0-32 系统级性能优化通常包括两个阶段:性能剖析(performance pro ...
- 系统级性能分析工具 — Perf
从2.6.31内核开始,linux内核自带了一个性能分析工具perf,能够进行函数级与指令级的热点查找. perf Performance analysis tools for Linux. Perf ...
- 系统级性能分析工具 — Perf【转】
转自:https://blog.csdn.net/zhangskd/article/details/37902159 版权声明:本文为博主原创文章,转载请注明出处. https://blog.csdn ...
- CentOS6中OpenMP的运行时间或运行性能分析
OpenMp作为单机多核心共享内存并行编程的开发工具,具有编码简洁等,容易上手等特点. 关于OpenMP的入门,博主饮水思源(见参考资料)有了深入浅出,循序渐进的分析.做并行开发,做性能分析是永远逃避 ...
- DevTools 实现原理与性能分析实战
一.引言 从 2008 年 Google 释放出第一版的 Chrome 后,整个 Web 开发领域仿佛被注入了一股新鲜血液,渐渐打破了 IE 一家独大的时代.Chrome 和 Firefox 是 W3 ...
- Java 性能分析工具 , 第 3 部分: Java Mission Control
引言 本文为 Java 性能分析工具系列文章第三篇,这里将介绍如何使用 Java 任务控制器 Java Mission Control 深入分析 Java 应用程序的性能,为程序开发人员在使用 Jav ...
- 常用排序算法的python实现和性能分析
常用排序算法的python实现和性能分析 一年一度的换工作高峰又到了,HR大概每天都塞几份简历过来,基本上一天安排两个面试的话,当天就只能加班干活了.趁着面试别人的机会,自己也把一些基础算法和一些面试 ...
- 【转】一文掌握 Linux 性能分析之 CPU 篇
[转]一文掌握 Linux 性能分析之 CPU 篇 平常工作会涉及到一些 Linux 性能分析的问题,因此决定总结一下常用的一些性能分析手段,仅供参考. 说到性能分析,基本上就是 CPU.内存.磁盘 ...
随机推荐
- es6笔记3^_^object
一.destructuring ES6允许按照一定模式,从数组和对象中提取值,对变量进行赋值,这被称为解构Destructuring. //es5 if(1){ let cat = 'ken'; le ...
- (一)Hololens Unity 开发环境搭建(Mac BOOTCAMP WIN10)
(一)Hololens Unity 开发环境搭建(Mac BOOTCAMP WIN10) 系统要求 64位 Windows 10 除了家庭版的 都支持 ~ 64位CPU CPU至少是四核心以上~ 至少 ...
- 为什么python适合写爬虫?(python到底有啥好的?!)
我用c#,java都写过爬虫.区别不大,原理就是利用好正则表达式.只不过是平台问题.后来了解到很多爬虫都是用python写的.因为目前对python并不熟,所以也不知道这是为什么.百度了下结果: 1) ...
- 深入了解GCD
首先提出一些问题: dispatch_async 函数如何实现,分发到主队列和全局队列有什么区别,一定会新建线程执行任务么? dispatch_sync 函数如何实现,为什么说 GCD 死锁是队列导致 ...
- 怎么写cookie
html结构 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UT ...
- redisson实现分布式锁原理
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- 使用ViewPagerAdapter 页面引导适配器设置app启动页,引导页面的实现
一般的app第一次安装启动的时候,都会有一个启动页面和引导页的画面,然后才进入主程序.anndroid中的ViewPagerAdapter 是一个继承与PageAdapter的 页面引导适配器.由于我 ...
- 提升iOS审核通过率之“IPv6兼容测试”
作者:jingle 腾讯系统测试工程师 商业转载请联系腾讯WeTest授权,非商业转载请注明出处. 原文链接:http://wetest.qq.com/lab/view/285.html 一.背景 在 ...
- JVM 堆和栈的区别
栈内存: 程序在栈内存中运行 栈中存的是基本数据类型和堆中对象的引用 栈是运行时的单元 栈解决程序的运行问题,即程序如何执行,或者说如何处理数据 一个线程一个独立的线程栈 ...
- Linux学习之Linux目录及文件系统
以往的 Windows 一直是以存储介质为主的,主要以盘符(C 盘,D 盘...)及分区来实现文件管理,然后之下才是目录,目录就显得不是那么重要,除系统文件之外的用户文件放在任何地方任何目录也是没有多 ...