更快的memcpy
更快的memcpy
写代码有时候和笃信宗教一样,一旦信仰崩溃,是最难受的事情。早年我读过云风的一篇《VC 对 memcpy 的优化》,以及《Efficiency geek 2: copying data in C/C++, optimisation》,所以我是坚信很难能写出比C运行时库更快的memcpy的。但最近有两个事情,让我对这个坚信产生了怀疑。
第一个个是最近在看lz4的代码,lz4可能是目前最快的内存压缩算法,部分评测他比snappy还要快点(lz4的实现后面专文剖析)。研究他的代码,发现他其中有个重要的和其他代码不同地方就是他的内存拷贝采用的是一个宏,而不是使用memcpy。其内部直接使用uint64_t转换指针进行拷贝赋值,个人估计这是他加快处理速度的一个地方。其拷贝代码大意如下,其实现不在乎字长溢出的部分。

1 //你要保证dst有足够的空间,其要求空间很可能比sz大,都是8字节补齐的。
2 #define ZEN_TEST_FAST_COPY(dst,src,sz) {\
3 char *_cpy_dst = dst; \
4 const char *_cpy_src = src; \
5 size_t _cpy_size = sz;\
6 do \
7 { \
8 ZBYTE_TO_UINT64(_cpy_dst) = ZBYTE_TO_UINT64(_cpy_src); \
9 _cpy_dst += sizeof(uint64_t); \
10 _cpy_src += sizeof(uint64_t); \
11 }while( _cpy_size > sizeof(uint64_t) && (_cpy_size -= sizeof(uint64_t))); \
12 }
第二个是看了一篇文章《哪个memcpy更快?》。发现里面说Linux标准库的memcpy比较不堪。这个有点颠覆了。原文代码有个问题是,其在最开始对非取整的部分进行了操作。但如果memcpy的dst,src参数地址是对齐的,这样明显不利于加快速度。我改进的代码如下:
1 void *ZEN_OS::fast_memcpy(void *dst, const void *src, size_t sz)
2 {
3 void *r = dst;
4
5 //先进行uint64_t长度的拷贝,一般而言,内存地址都是对齐的,
6 size_t n = sz & ~(sizeof(uint64_t) - 1);
7 uint64_t *src_u64 = (uint64_t *) src;
8 uint64_t *dst_u64 = (uint64_t *) dst;
9
10 while (n)
11 {
12 *dst_u64++ = *src_u64++;
13 n -= sizeof(uint64_t);
14 }
15
16 //将没有非8字节字长取整的部分copy
17 n = sz & (sizeof(uint64_t) - 1);
18 uint8_t *src_u8 = (uint8_t *) src;
19 uint8_t *dst_u8 = (uint8_t *) dst;
20 while (n-- )
21 {
22 (*dst_u8++ = *src_u8++);
23 }
24
25 return r;
26 }
文章代码里面还有个一个类似函数,区别在于,其在每次循环拷贝了2次uint64_t字长的数据。为了行文方便我们称之为fast_memcpy[2]把。
1 while (n)
2 {
3 *dst_u64++ = *src_u64++;
4 *dst_u64++ = *src_u64++;
5 n -= sizeof(uint64_t)*2;
6 }
为了搞明白到底如何,只有自己测试一下。测试拷贝了8,16……64K,1M,4M字节的数据。在LINUX 64 (GCC 4.3 O3优化),Windows7 X64(Visual 2010 realse),Windwos7 win32(realse)的环境进行了测试,测试采用高精度定时器采集数据。。
第一组测试以字节对齐数据进行,无聊的数据就不贴了,直接上图。如果把最慢的速度比作100%,其他人作为和他的相对比率绘制图片,线条一直在下面的肯定更好一些:
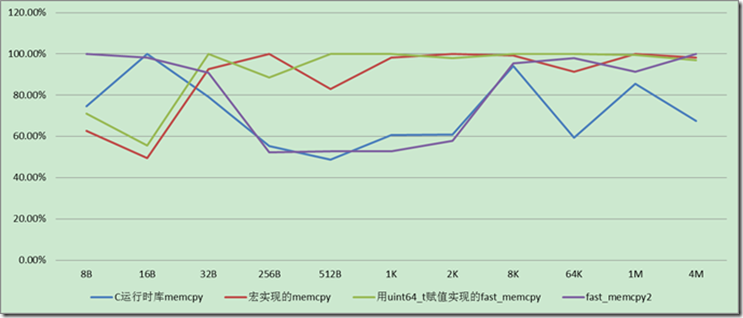
Linux 64位下(GCC 4.3 OS优化),字节对齐情况下拷贝速度对比,如下图,
Windows7 X64,Visaul C++ 2010 Realse, 字节对齐情况下拷贝速度,如下图
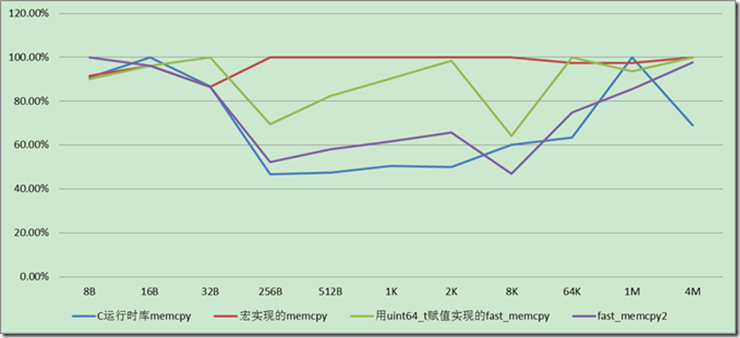
看上面的比较图片就会知道memcpy在对齐清下,memcpy在任何时候都是不错的选择。
但内存拷贝还有另外一种常见情况,就是字节无法对齐的情况,而lz4作为一个压缩算法,可能恰恰要经常面对无法对齐的情况,所以我针对这种情况也做了一下测试。
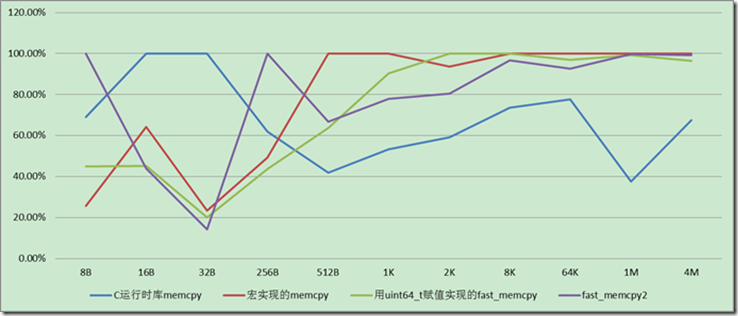
Linux 64位下(GCC 4.3 OS优化),字节非对齐情况下拷贝速度,如下图,
Windows7 X64,Visaul C++ 2010 Realse, 字节非对齐情况下拷贝速度,如下图,宏的拷贝
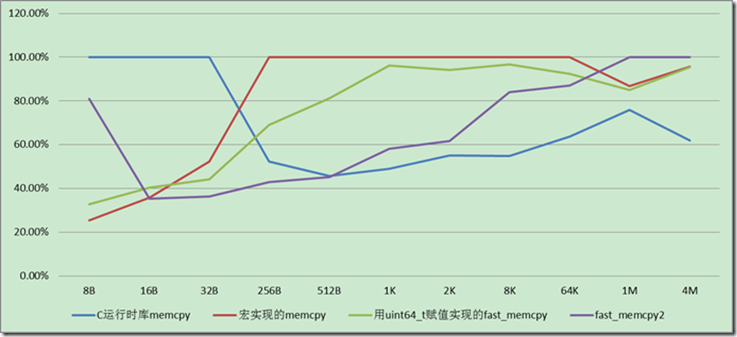
在字节不对齐的情况下,并且拷贝的内存长度小于256字节,用8字节的赋值方式速度会稍微优于memcpy,这可能也是lz4采用这个方法的原因。如果拷贝的尺寸更大的不对齐时,memcpy还是更好的选择。而考虑到lz4大部分情况面对的拷贝字节,应该小于256字节。所以他采用宏拷贝的方式理论上是可以获得一些优势。
结论:
在字节对齐的情况下,memcpy在任何时候几乎都是最优的选择。
确实有些方法在特定条件下比memcpy快一点。但如果你不知道如何选择,默认还是选择memcpy为好。同理也适应memset函数。
Windows 平台上,如果数据长度达到1M或者4M,Windows的下的表现要好于Linxu平台,特别是在64位的平台上。(当然Linux测试环境是虚拟机,是否有一定影响?),可能的原因为止,和frostburn掰扯估计Windows下指令优化也许有过GCC之处。
写出比运行时库memcpy更快函数,这本身就是一个比较扯淡的事情,你的对手有编译器优化,代码运行优化,指令优化等多种手段。《哪个memcpy更快?》一文应该是有缪误的。当然他可能有他的背景(没有开优化?),作者可能并没有说清。
参考文档以及背景阅读:
《VC 对 memcpy 的优化》 云风解释的VC对于各种拷贝长度,编译器做的优化。
《Efficiency geek 2: copying data in C/C++, optimisation》作者对一些Geek的方法做了评估,当然第一篇memset部分写的更为详细一些。有些Geek作法大家可以看看。《各种版本的memcpy(底层优化)》一问解释一些数据拷贝的优化方法。《Optimizing Memcpy improves speed》这个里面提到的memcpy也不是我们所说的C运行时库的memcpy,但此文也解释了一些的提速数据拷贝方法。
《哪个memcpy更快?》误导我的文章,我认为他所述的东东应该有个特殊场景。或者他说的C库的memcpy和我理解就不是一个东东?
《C/C++ tip: How to copy memory quickly》文章也说明了这个问题,他的结论和我们一样。
【本文作者是雁渡寒潭,本着自由的精神,你可以在无盈利的情况完整转载此文 档,转载时请附上BLOG链接:http://www.cnblogs.com/fullsail/,否则每字一元,每图一百不讲价。对Baidu文库和360doc加价一倍】
更快的memcpy的更多相关文章
- 扯扯淡,写个更快的memcpy
写代码有时候和笃信宗教一样,一旦信仰崩溃,是最难受的事情.早年我读过云风的一篇<VC 对 memcpy 的优化>,以及<Efficiency geek 2: copying data ...
- 精通Web Analytics 2.0 (9) 第七章:失败更快:爆发测试与实验的能量
精通Web Analytics 2.0 : 用户中心科学与在线统计艺术 第七章:失败更快:爆发测试与实验的能量 欢迎来到实验和测试这个棒极了的世界! 如果Web拥有一个超越所有其他渠道的巨大优势,它就 ...
- 假如 UNION ALL 里面的子句 有 JOIN ,那个执行更快呢
比如: select id, name from table1 where name = 'x' union all select id, name from table2 where name = ...
- 【译】更快的方式实现PHP数组去重
原文:Faster Alternative to PHP’s Array Unique Function 概述 使用PHP的array_unique()函数允许你传递一个数组,然后移除重复的值,返回一 ...
- ubuntu 12.04 LTS 如何使用更快的更新源
装好ubuntu系统后的第一见事就是替换自带的更新源,原因是系统自带的源有些在中国访问不了,可以访问的速度又特别慢.幸好国内的一些公司和大学提供了速度不错的更新源.下面介绍如何使用更快的更新源 方法/ ...
- php提供更快的文件下载
在微博上偶然看到一篇介绍php更快下载文件的方法,其实就是利用web服务器的xsendfile特性,鸟哥的博客中只说了apache的实现方式,我找到了介绍nginx实现方式的文章,整理一下! let' ...
- CSS 和 JS 动画哪个更快
基于Javascript的动画暗中同CSS过渡效果一样,甚至更加快,这怎么可能呢?而Adobe和Google持续发布的富媒体移动网站的性能可媲美本地应用,这又怎么可能呢? 本文逐一遍览了基于Javas ...
- 为什么get比post更快
引言 get和post在面试过程中一般都会问到,一般的区别: 1.post更安全(不会作为url的一部分,不会被缓存.保存在服务器日志.以及浏览器浏览记录中) 2.post发送的数据量更大(get有u ...
- CSS VS JS动画,哪个更快[译]
英文原文:https://davidwalsh.name/css-js-animation 原作者Julian Shapiro是Velocity.js的作者,Velocity.js是一个高效易用的js ...
随机推荐
- java抽象类和接口的区别(转载)
1.Java接口和Java抽象类最大的一个区别,就在于Java抽象类可以提供某些方法的部分实现,而Java接口不可以,这大概就是Java抽象类唯一的优点吧,但这个优点非常有用. 如果向一个抽象类里加入 ...
- libvlc media player in C# (part 1)
原文 http://www.helyar.net/2009/libvlc-media-player-in-c/ There seems to be a massive misconception ab ...
- Guava之简介
1.介绍 Guava最初是在2007年作为“Google Collection Library” 出现的,这个项目在处理Java集合时提供了一些有用的工具,Google的这个guava项目已经成为了 ...
- 使用Windows2003创建AD服务器 - 进阶者系列 - 学习者系列文章
Windows 2003的AD功能不是很强,但是还是提供了不错的功能.下面简要介绍下Windows 2003的AD配置说明. 1. 从添加删除Windows组件安装AD功能项 2. 完成安装.这里 ...
- 非接触式电子音乐控制器CHIMAERA
本篇文章,我将介绍个有意思的设备. 她就是Chimaera,一个基于电磁场效应的非接触式电子音乐控制器. <弹奏Chimaera的声音> 霍尔效应传感器阵列及其周围部件组成了一个连续的2D ...
- 【转】在PC上测试移动端网站和模拟手机浏览器的5大方法
查了很多资料,尝试了大部分方法,下面将这一天的努力总结下分享给大家,也让大家免去看那么多文章,以下介绍的方法,都是本人亲自测试成功的方法,测试环境winxp. 一.Chrome*浏览器 chrome模 ...
- c#多线程随记回顾
C#多线程随记回顾 1.创建多线程方式知道的有三种: ---手动创建Thread.使用线程池.使用task任务 ---手动创建Thread,分两种带参数和不带参数的帮助委托器 eg: //帮助器委托 ...
- (蓝牙)网络编程中,使用InputStream read方法读取数据阻塞的解决方法
问题如题,这个问题困扰了我好几天,今天终于解决了,感谢[1]. 首先,我要做的是android手机和电脑进行蓝牙通信,android发一句话,电脑端程序至少就要做到接受到那句话.android端发送信 ...
- [Usaco2008 Open] Clear And Present Danger 寻宝之路[最短路][水]
Description 农夫约翰正驾驶一条小艇在牛勒比海上航行. 海上有N(1≤N≤100)个岛屿,用1到N编号.约翰从1号小岛出发,最后到达N号小岛.一 张藏宝图上说,如果他的路程上 ...
- [Usaco2008 Nov]Guarding the Farm 保卫牧场[DFS]
Description The farm has many hills upon which Farmer John would like to place guards to ensure the ...