sklearn学习7-----决策树(tree)
1、使用示例
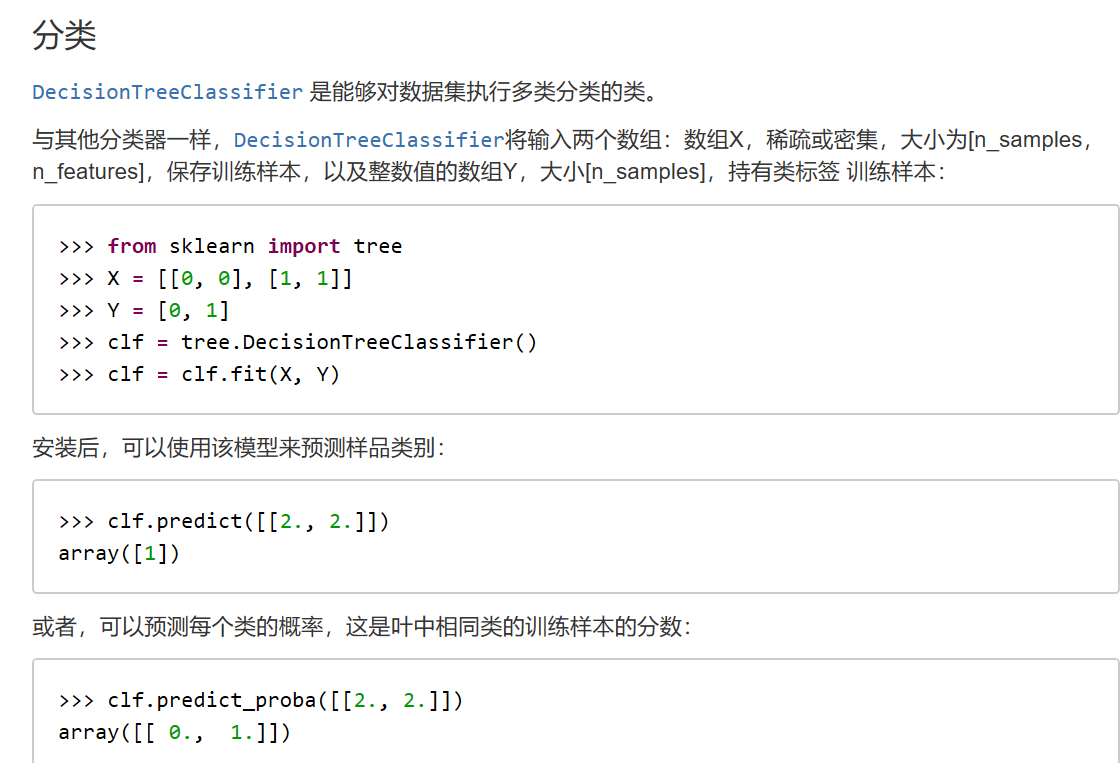
2、树模型参数:【很多参数都是用来限制树过于庞大,即担心其过拟合】
# 1.criterion gini or entropy:用什么作为衡量标准 ( 熵值或者Gini系数 )。
# 2.splitter best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中(数据量大的时候)【当特征过大时,从头开始遍历会过慢,一般选默认值best)】
# 3.max_features int or None(所有),optional(default=None) , log2,sqrt,N 特征小于50的时候一般使用所有的 【通常使用默认值None】
# 4.max_depth int or None:默认值为None。数据少或者特征少的时候可以不管这个值,如果模型样本量多,特征也多的情况下,可以尝试限制下树的深度
# 5.min_samples_split 如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分,如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
# 6.min_samples_leaf 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,如果样本量不大,不需要管这个值,大些如10W可是尝试下5
# 7.min_weight_fraction_leaf 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
# 8.max_leaf_nodes 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点数。 如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
# 9.class_weight 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多, 导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重。如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
# 10.min_impurity_split 这个值限制了决策树的增长,如果某节点的不纯度,(基尼系数,信息增益,均方差,绝对差)小于这个阈值。则该节点不再生成子节点。即为叶子节点 。
sklearn学习7-----决策树(tree)的更多相关文章
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
- Sklearn库例子——决策树分类
Sklearn上关于决策树算法使用的介绍:http://scikit-learn.org/stable/modules/tree.html 1.关于决策树:决策树是一个非参数的监督式学习方法,主要用于 ...
- sklearn学习总结(超全面)
https://blog.csdn.net/fuqiuai/article/details/79495865 前言sklearn想必不用我多介绍了,一句话,她是机器学习领域中最知名的python模块之 ...
- SKlearn中分类决策树的重要参数详解
学习机器学习童鞋们应该都知道决策树是一个非常好用的算法,因为它的运算速度快,准确性高,方便理解,可以处理连续或种类的字段,并且适合高维的数据而被人们喜爱,而Sklearn也是学习Python实现机器学 ...
- sklearn 学习之分类树
概要 基于 sklearn 包自带的 iris 数据集,了解一下分类树的各种参数设置以及代表的意义. iris 数据集介绍 iris 数据集包含 150 个样本,对应数据集的每行数据,每行数据包含 ...
- sklearn 学习 第一篇:分类
分类属于监督学习算法,是指根据已有的数据和标签(分类)进行学习,预测未知数据的标签.分类问题的目标是预测数据的类别标签(class label),可以把分类问题划分为二分类和多分类问题.二分类是指在两 ...
- sklearn笔记:决策树
概述 sklearn中决策树的类都在 tree 这个模块下.这个模块总共包含五个类: tree.DecisionTreeClassifier:分类树 tree.DecisionTreeRegresso ...
- 浅谈树模型与集成学习-从决策树到GBDT
引言 神经网络模型,特别是深度神经网络模型,自AlexNet在Imagenet Challenge 2012上的一鸣惊人,无疑是Machine Learning Research上最靓的仔,各种进 ...
- sklearn学习笔记3
Explaining Titanic hypothesis with decision trees decision trees are very simple yet powerful superv ...
随机推荐
- 发现被坑了,从来没看到说java的Date一旦实例化时间就不会变了
java中使用Date对象获取系统当前时间,然而我就没看到哪篇教程告诉我说Date创建对象之后其中的时间是不会变的!!! 一开始我写了类似于下边这样的代码,希望每隔一段时间显示一次时间 Date d= ...
- C++继承与组合
转自https://blog.csdn.net/caoyan_12727/article/details/52337297 类的组合和继承一样,是软件重用的重要方式.组合和继承都是有效地利用已有类的资 ...
- mysql 每个月创建新表
1.CREATE DEFINER=`root`@`%` PROCEDURE `aa`()BEGIN SET @sqlstr = CONCAT('create table cdrpbx10_',DATE ...
- OSI层次介绍
1.应用层:为应用软件提供接口,使应用程序能够使用网络服务. 2.表示层:①数据的解码和编码,②数据的加密和解密,③数据的压缩和解压缩. 3.会话层:建立.维护.管理应用程序之间的会话. 功能:对话控 ...
- Python 不同列表时间测试
import timeit import threading def test1(): l = [] for i in range(1000): l = l + [i] def test2(): l ...
- nmon分析文件各sheet含义
sheet名称sheet含义 SYS_SUMM系统汇总,蓝线为cpu占有率变化情况,粉线为磁盘IO的变化情况: AAA关于操作系统以及nmon本身的一些信息: BBBB系统外挂存储容量以及存储类型: ...
- nodejs-Sream
Stream 是一个抽象接口,Node 中有很多对象实现了这个接口.例如,对http 服务器发起请求的request 对象就是一个 Stream,还有stdout(标准输出). Node.js,Str ...
- 洛谷 U5737 纸条
U5737 纸条 题目背景 明明和牛牛是一对要好的朋友,他们经常上课也想讲话,但是他们的班级是全校纪律最好的班级,所以他们只能通过传纸条的方法来沟通.但是他们并不能保证每次传纸条老师都无法看见,所以他 ...
- MySQL DROP TABLE操作以及 DROP 大表时的注意事项
语法: 删表 DROP TABLE Syntax DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name] ... [RESTRICT | CA ...
- 关于C++构造函数一二
关于构造函数的调用顺序: 1.继承关系 2.从属关系 3.static声明的从属关系 关于拷贝构造函数的声明: classname(const classname & rhs) #includ ...