elasticsearch index 之merge
merge是lucene的底层机制,merge过程会将index中的segment进行合并,生成更大的segment,提高搜索效率。segment是lucene索引的一种存储结构,每个segment都是一部分数据的完整索引,它是lucene每次flush或merge时候形成。每次flush就是将内存中的索引写出一个独立segment的过程。所以随着数据的不断增加,会形成越来越多的segment。因为segment是不可变的,删除操作不会改变segment内部数据,只是会在另外的地方记录某些数据删除,这样可能会导致segment中存在大量无用数据。搜索时,每个segment都需要一个reader来读取里面的数据,大量的segment会严重影响搜索效率。而merge过程,会将小的segment写到一起形成一个大的segment,减少其数量。同时重写过程会抛弃那些已经删除的数据。因此segment的merge是有利于查询效率的。
elasticsearch的merge其实就是lucene的merge机制。merge过程是lucene有一个后台线程,它会根据merge策略来决定是否进行merge,一旦merge的条件满足,就会启动后台merge。merge策略分为两种,这也是大多数大数据框架所采用的,segment的大小和segment中doc的数量。以这两个标准为基础实现了三种merge策略:TieredMergePolicy、LogDocMergePolicy 及LogByteSizeMergePolicy。elasticsearch这一部分就是对这三种合并策略的封装,并提供了对于的配置。它的实现方式如下所示:
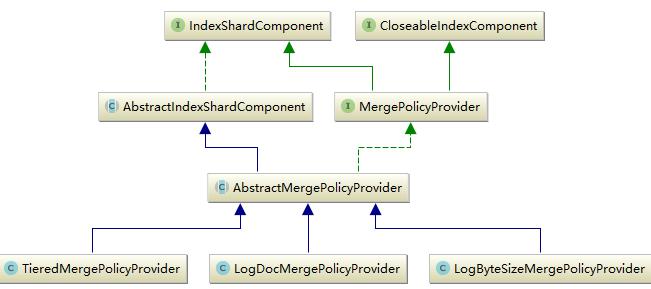
底层mergeprovider实现了对三种合并策略的初始化和配置,并通过getMergePolicy()方法对外提供。这三种合并策略中LogDocMergePolicy是根据doc数量进行合并,其它两种都是根据segment的大小,只是TieredMergePolicy合并过程是分层进行,它会把小于某一值的所有segment合并成一个大的segment,然后再一次进行。
以上是合并策略,除了合并策略还有一个要说的就是合并线程。前面说过,merge是通过独立线程完成的,lucene对于线程策略也有两种,一种是顺序,另外一种就是并发。顺序合并策略会阻止索引的进行,因此多数情况先不会使用,而并发合并则是和index过程同时进行,这样不会影响索引和搜索。elasticsearch同样通过provider的形式提供这两种合并线程配置。
总结:merge能够通过减少segment数量来提高搜索速度。但是merge的过程会对索引吞吐量及搜索速度有一定的影响,因此需要配置适当的合并策略参数。对于资源不足的环境,最好禁止自动merge,选择空闲时段手动进行merge。
,
elasticsearch index 之merge的更多相关文章
- elasticsearch index 之 put mapping
elasticsearch index 之 put mapping mapping机制使得elasticsearch索引数据变的更加灵活,近乎于no schema.mapping可以在建立索引时设 ...
- ElasticSearch Index操作源码分析
ElasticSearch Index操作源码分析 本文记录ElasticSearch创建索引执行源码流程.从执行流程角度看一下创建索引会涉及到哪些服务(比如AllocationService.Mas ...
- Elasticsearch Index模块
1. Index Setting(索引设置) 每个索引都可以设置索引级别.可选值有: static :只能在索引创建的时候,或者在一个关闭的索引上设置 dynamic:可以动态设置 1.1. S ...
- elasticsearch index tuning
一.扩容 tag_server当前使用ElasticSearch版本为5.6,此版本单个index的分片是固定的,一旦创建后不能更改. 1.扩容方法1,不适 ES6.1支持split index功能, ...
- elasticsearch index 之 engine
elasticsearch对于索引中的数据操作如读写get等接口都封装在engine中,同时engine还封装了索引的读写控制,如流量.错误处理等.engine是离lucene最近的一部分. engi ...
- Add mappings to an Elasticsearch index in realtime
Changing mapping on existing index is not an easy task. You may find the reason and possible solutio ...
- ElasticSearch Index API && Mapping
ElasticSearch NEST Client 操作Index var indexName="twitter"; var deleteIndexResponse = clie ...
- Elasticsearch index fields 重命名
reindex数据复制,重索引 POST _reindex { "source": { "index": "twitter" }, &quo ...
- elasticsearch index 之 create index(二)
创建索引需要创建索引并且更新集群index matedata,这一过程在MetaDataCreateIndexService的createIndex方法中完成.这里会提交一个高优先级,AckedClu ...
随机推荐
- Kali linux 2016.2(Rolling)中的Nmap的端口扫描功能
不多说,直接上干货! 如下,是使用Nmap对主机202.193.58.13进行一次端口扫描的结果,其中使用 root@kali:~# nmap -sS -Pn 202.193.58.13 Starti ...
- Spring控制反转容器的使用例子
详细代码如下: spring-config.xml <?xml version="1.0" encoding="UTF-8"?> <beans ...
- c# IndexOf()用法
IndexOf()用法 查找字符串中字符或者字符串首次出现的位置,返回的是索引值; str1.indexOf('字');//查找“字”在字符串中首次出现的索引值 str1.indexOf(" ...
- CDH5.14操作指南
1.Cdh 5.14介绍 2.版本发布概要 3.安装要求 4.Cloudera Manager介绍 5.Cloudera 安装 6.Cloudera 管理 7.Cloudera Navigator C ...
- 【Henu ACM Round#20 D】 Devu and Partitioning of the Array
[链接] 我是链接,点我呀:) [题意] 在这里输入题意 [题解] 一开始所有的数字单独成一个集合. 然后用v[0]和v[1]记录集合的和为偶数和奇数的集合它们的根节点(并查集 然后先让v[0]的大小 ...
- 【Codeforces Round #422 (Div. 2) D】My pretty girl Noora
[题目链接]:http://codeforces.com/contest/822/problem/D [题意] 有n个人参加选美比赛; 要求把这n个人分成若干个相同大小的组; 每个组内的人数是相同的; ...
- Git学习总结(6)——作为一名程序员这些代码托管工具你都知道吗?
作为一名程序员这些代码托管工具你都知道吗? 作为一名优秀的开发者,大家都会用到代码托管,我本人用的是github,确实github里面有很多很多开源的项目,所以我们目前的创业项目程序员客栈www.pr ...
- What is x86 Conforming Code Segment?
SRC=Microprocessor Based Systems SRC=Computer Architecture: A Quantitative Approach
- 洛谷 P3199 [HNOI2009]最小圈
P3199 [HNOI2009]最小圈 题目背景 如果你能提供题面或者题意简述,请直接在讨论区发帖,感谢你的贡献. 题目描述 对于一张有向图,要你求图中最小圈的平均值最小是多少,即若一个圈经过k个节点 ...
- Windows远程登录Linux
本文以Ubuntu Kylin1404为例,说明如何通过Windows远程登录Linux. 首先,要确保Ubuntu上SSH服务执行正常.默认情况下,Ubuntu已装有SSHclient.比方输入ss ...