elasticsearch index 之merge
merge是lucene的底层机制,merge过程会将index中的segment进行合并,生成更大的segment,提高搜索效率。segment是lucene索引的一种存储结构,每个segment都是一部分数据的完整索引,它是lucene每次flush或merge时候形成。每次flush就是将内存中的索引写出一个独立segment的过程。所以随着数据的不断增加,会形成越来越多的segment。因为segment是不可变的,删除操作不会改变segment内部数据,只是会在另外的地方记录某些数据删除,这样可能会导致segment中存在大量无用数据。搜索时,每个segment都需要一个reader来读取里面的数据,大量的segment会严重影响搜索效率。而merge过程,会将小的segment写到一起形成一个大的segment,减少其数量。同时重写过程会抛弃那些已经删除的数据。因此segment的merge是有利于查询效率的。
elasticsearch的merge其实就是lucene的merge机制。merge过程是lucene有一个后台线程,它会根据merge策略来决定是否进行merge,一旦merge的条件满足,就会启动后台merge。merge策略分为两种,这也是大多数大数据框架所采用的,segment的大小和segment中doc的数量。以这两个标准为基础实现了三种merge策略:TieredMergePolicy、LogDocMergePolicy 及LogByteSizeMergePolicy。elasticsearch这一部分就是对这三种合并策略的封装,并提供了对于的配置。它的实现方式如下所示:
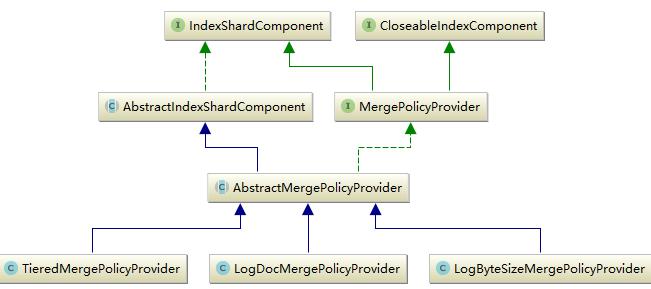
底层mergeprovider实现了对三种合并策略的初始化和配置,并通过getMergePolicy()方法对外提供。这三种合并策略中LogDocMergePolicy是根据doc数量进行合并,其它两种都是根据segment的大小,只是TieredMergePolicy合并过程是分层进行,它会把小于某一值的所有segment合并成一个大的segment,然后再一次进行。
以上是合并策略,除了合并策略还有一个要说的就是合并线程。前面说过,merge是通过独立线程完成的,lucene对于线程策略也有两种,一种是顺序,另外一种就是并发。顺序合并策略会阻止索引的进行,因此多数情况先不会使用,而并发合并则是和index过程同时进行,这样不会影响索引和搜索。elasticsearch同样通过provider的形式提供这两种合并线程配置。
总结:merge能够通过减少segment数量来提高搜索速度。但是merge的过程会对索引吞吐量及搜索速度有一定的影响,因此需要配置适当的合并策略参数。对于资源不足的环境,最好禁止自动merge,选择空闲时段手动进行merge。
,
elasticsearch index 之merge的更多相关文章
- elasticsearch index 之 put mapping
elasticsearch index 之 put mapping mapping机制使得elasticsearch索引数据变的更加灵活,近乎于no schema.mapping可以在建立索引时设 ...
- ElasticSearch Index操作源码分析
ElasticSearch Index操作源码分析 本文记录ElasticSearch创建索引执行源码流程.从执行流程角度看一下创建索引会涉及到哪些服务(比如AllocationService.Mas ...
- Elasticsearch Index模块
1. Index Setting(索引设置) 每个索引都可以设置索引级别.可选值有: static :只能在索引创建的时候,或者在一个关闭的索引上设置 dynamic:可以动态设置 1.1. S ...
- elasticsearch index tuning
一.扩容 tag_server当前使用ElasticSearch版本为5.6,此版本单个index的分片是固定的,一旦创建后不能更改. 1.扩容方法1,不适 ES6.1支持split index功能, ...
- elasticsearch index 之 engine
elasticsearch对于索引中的数据操作如读写get等接口都封装在engine中,同时engine还封装了索引的读写控制,如流量.错误处理等.engine是离lucene最近的一部分. engi ...
- Add mappings to an Elasticsearch index in realtime
Changing mapping on existing index is not an easy task. You may find the reason and possible solutio ...
- ElasticSearch Index API && Mapping
ElasticSearch NEST Client 操作Index var indexName="twitter"; var deleteIndexResponse = clie ...
- Elasticsearch index fields 重命名
reindex数据复制,重索引 POST _reindex { "source": { "index": "twitter" }, &quo ...
- elasticsearch index 之 create index(二)
创建索引需要创建索引并且更新集群index matedata,这一过程在MetaDataCreateIndexService的createIndex方法中完成.这里会提交一个高优先级,AckedClu ...
随机推荐
- Pycharm在创建py文件时,如何自动添加默认文件头注释?
PyCharm是一款很好用的编写Python工程的IDE,用PyCharm创建一个Python文件或者向工程添加一个.py文件时,为了更好的使所编写的代码在各操作环境更好的运行,我们往往需要在.py文 ...
- C语言基础-第六章
数组和字符串 1.一维数组 数组当中最简单的数据 声明: 类型说明符 数组名[常量表达式] int a[3];说明a的长度为3,那么给a赋值的语句是:a={1,2,3}; 2.多维数组 2.1 二维数 ...
- Angular2/Ionic2集成Promact/md2.md
最近想找一套比较完整的基于Material风格的Angular2的控件库,有两个选择一个是Angular官方的Material2,但是这套库的DatePicker控件目前只能支持年月日,不支持时分秒, ...
- MySQL服务正在启动或停止中,请稍候片刻后再试一次【解决方案】
相信有些小伙伴在使用数据库的过程中会经常频繁的启动和停止MySQL服务,有时候会出现“服务正在启动或停止中,请稍候片刻后再试一次.”这样的提示,如下图所示. 于是乎想办法去解决这个问题,但是发现连强制 ...
- php实现自动加载类
PHP 实现自动加载类:
- perl模块
查看perl模块安装目录:find `perl -e ‘print “@INC”‘` -name ‘*.pm’ -print 为什么要写或要模块呢?简言之:代码重用,更多见于写一组工具集,有很多地方是 ...
- javascript与DOM节点的结合使用
文档对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展标志语言的标准编程接口.在网页上,组织页面(或文档)的对象被组织在一个树形结构中,用来表示文档中对象 ...
- 在启动php时,无法启动此程序,由于计算机中丢失MSVCR110.dll的解决方法
在启动php时,运行RunHiddenconsole.exe php-cgi.exe -b 127.0.0.1:9000 -c时,出现错误:无法启动此程序,由于计算机中丢失MSVCR110.dll 方 ...
- 轻松学习之Linux教程四 神器vi程序编辑器攻略
本系列文章由@超人爱因斯坦出品,转载请注明出处. 文章链接: http://hpw123.net/a/Linux/Linuxjichu/2014/1026/93. ...
- RandomStringUtils生成随机数
org.apache.commons.lang.RandomStringUtils; //产生5位长度的随机字符串,中文环 ...