转:linux 安装 Elasticsearch5.6.x 详细步骤以及问题解决方案
在网上有很多那种ES步骤和问题的解决 方案的,不过没有一个详细的整合,和问题的梳理;我就想着闲暇之余,来记录一下自己安装的过程以及碰到的问题和心得;有什么不对的和问题希望及时拍砖。
第一步:环境
linux 系统 Java 1.8.0_151 elasticsearch-5.6.3
第二步:下载
2.1 JDK的下载可以去官网上直接下载,再次声明一下不要下载最新版本 JAVA 9 版本本人在次已经踩过坑了
2.2 ES 去官网直接下载,本人使用的是 5.6.3 版本;因为版本的不同安装head插件的时候安装步骤不同;好像是从5.0 以后的版本安装head 插件的步骤就不一样了;下面会详细介绍。
第三步:安装
3.1安装JDK环境
前提:查看该系统是否安装过Java 环境,如果安装过将其卸载安装最新的版本,更换Java 的版本也可以这样去操作。
3.1.1 执行命令 rpm -qa|grep jdk 如果安装过将会列出相应的版本,如果没有什么都不会输出。如果安装过使用rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.2.el7_2.x86_64 使用这个命令需要注意的就是,列出多少个版本插件就要卸载几个插件;执行完成后;在使用 rpm -qa|grep jdk 去查看一下是否有遗漏的插件没有卸载。
3.1.2 直接将下载好的jdk-8u151-linux-x64.rpm 安装包 ;上传到自己创建好的JAVA文件下;cd 命令进入到JAVA文件下使用rpm 命令进行安装 rpm -ivh jdk-8u131-linux-x64.rpm 安装完成后执行 java -version 命令查看安装是否成功
3.1.3 查看安装目录命令,
命令一:which java
命令二:ls -lrt /usr/bin/java
命令三:ls -lrt /etc/alternatives/java
最后将会得出这样的目录 /usr/java/jdk1.8.0_151/jre/bin/java
3.1.4 配置环境变量,执行命令 vi /etc/profile;然后进入编辑模式,在文件的最后添加下面的配置,如图
JAVA_HOME=/usr/javajdk1.8.0_151
JRE_HOME=/usr/java/jdk1.8.0_151/jre
CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH

修改完配置后,使用Esc 键退出,输入:wq 保存并退出
3.1.5 执行命令 source /etc/profile 使用环境变量生效
3.1.6 验证环境变量是否生效,分别执行下面的命令echo $JAVA_HOME echo $CLASSPATH echo $PATH
OK,JDK就这样安装好了。
3.2安装ES
3.2.1 下载ES安装包elasticsearch-5.6.3.zip 在usr 目录下创建了es文件夹,将安装包上传到里面,解压 unzip elasticsearch-5.6.3.zip cd 进入 elasticsearch-5.6.3 文件里面
3.2.2 创建ES用户和组(创建elsearch用户组及elsearch用户),因为使用root用户执行ES程序,将会出现错误;所以这里需要创建单独的用户去执行ES 文件;命令如下:
命令一:groupadd elsearch
命令二:useradd elsearch -g elsearch
命令三:chown -R elsearch:elsearch elasticsearch-5.6.3 该命令是更改该文件夹下所属的用户组的权限
3.2.3 修改host 文件,执行命令 vi /etc/hosts ,如图

3.2.4 创建ES数据文件和日志文件,直接在root用户根目录一下创建就可以了
执行命令:mkdir /data
命令二:chown -R elsearch:elsearch /data/
命令三:su - elsearch 切换用户
命令四:mkdir -p es/data
命令五:mkdir -p es/logs
3.2.5 修改ES配置文件,使用cd命令进入到config 文件下,执行 vi elasticsearch.yml 命令,如图所示,本人没有配置集群,只是简单的配置了一下;详细说明可以参考官网;
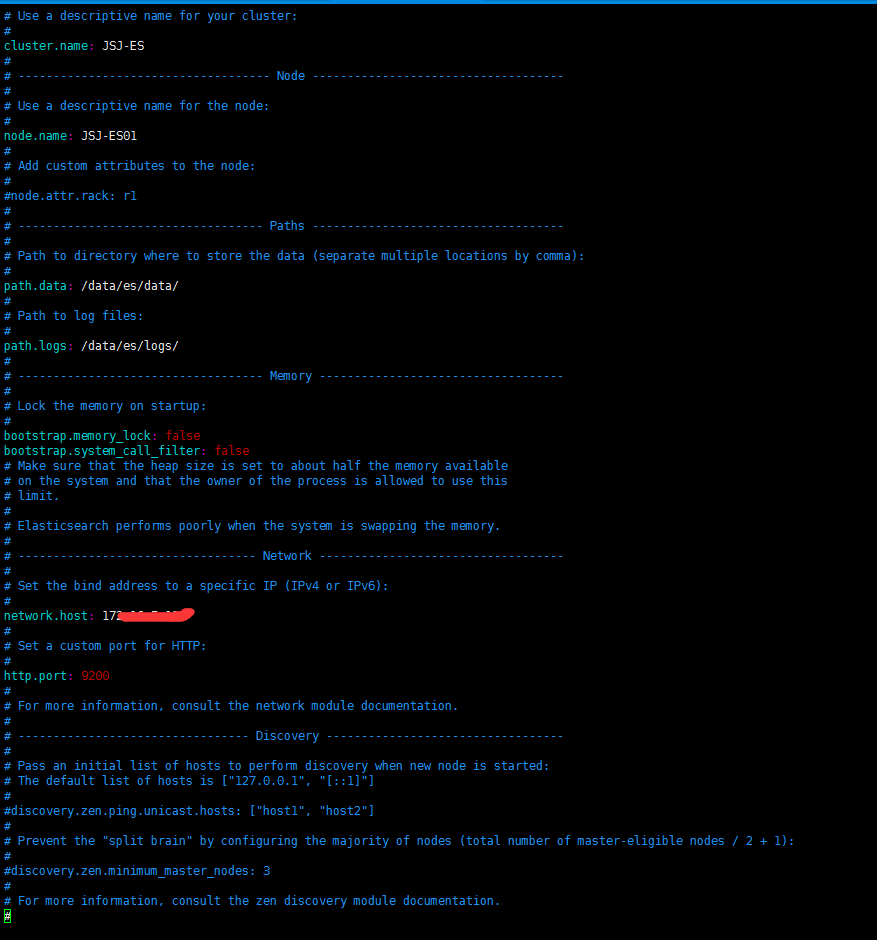
关于上面的警告都忽略了,然后直接就执行命令
3.2.6 执行ES文件,进入到bin 目录下执行 ./elasticsearch 命令就可以了,执行 ./elasticesrarch -d 是后台运行
如果没有什么问题话,就可以安全生成了;然后执行curl 'http://自己配置的IP地址:9200/' 命令,就出现下面的结果
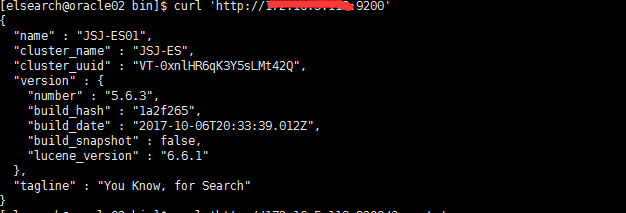
第四步:问题
4.1 1.[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] 意思是说你的进程不够用了
解决方案: 切到root 用户:进入到security目录下的limits.conf;执行命令 vim /etc/security/limits.conf 在文件的末尾添加下面的参数值:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
前面的*符号必须带上,然后重新启动就可以了。执行完成后可以使用命令 ulimit -n 查看进程数
第五步:安装head 插件
5.1 下载head安装包,下载地址:https://github.com/mobz/elasticsearch-head/archive/master.zip 这是接从git 上下载下来 ,然后上传到虚拟机上的;由于head 插件不能放在elasticsearch-5.6.3 文件夹里,head 插件需要单独放,单独去执行; 所 以在elasticsearch-5.6.3 同级目录下解压了 head 插件;解压出来的文件名字,如图

5.2 执行head 插件,需要node.js 的支持,所以,下面先安装一node.js
5.2.1 执行命令一:curl -sL https://rpm.nodesource.com/setup_8.x | bash -
命令二:yum install -y nodejs
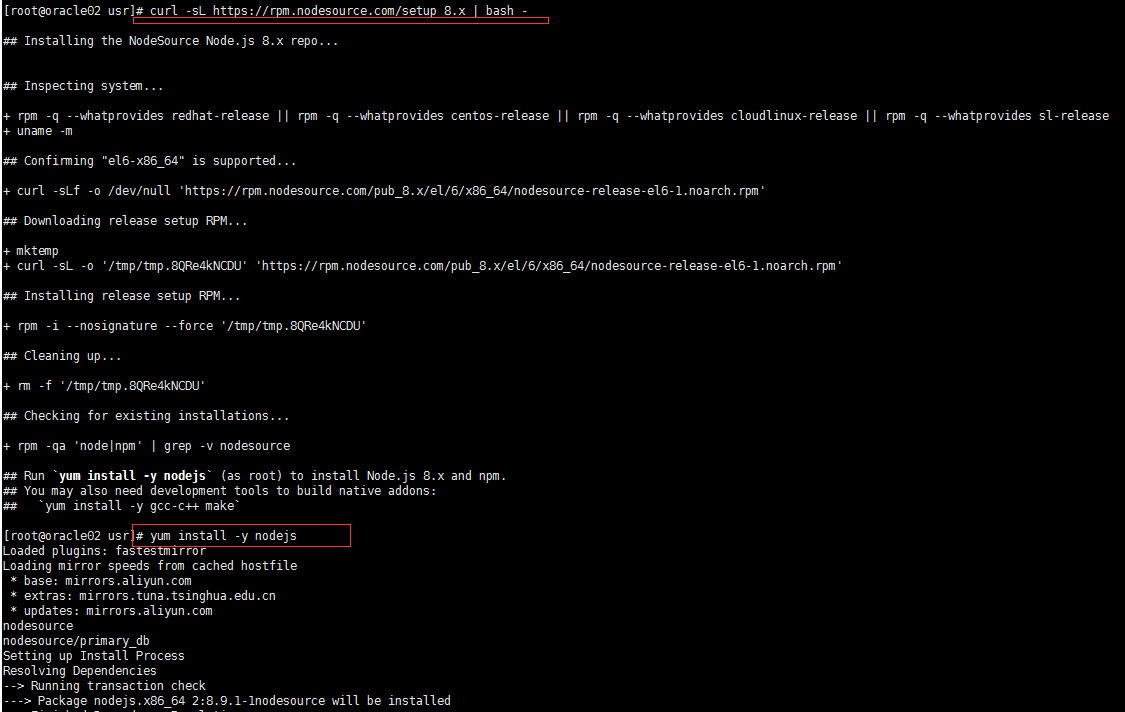
OK,执行完成后,可以使用命令 node -v 验证是否安装成功,同时npm 也安装成功了;执行命令 npm -v 也是可以验证的。

5.3 安装grunt ,由于head 插件的执行文件是有grunt 命令来执行的,所以这个命令必须安装
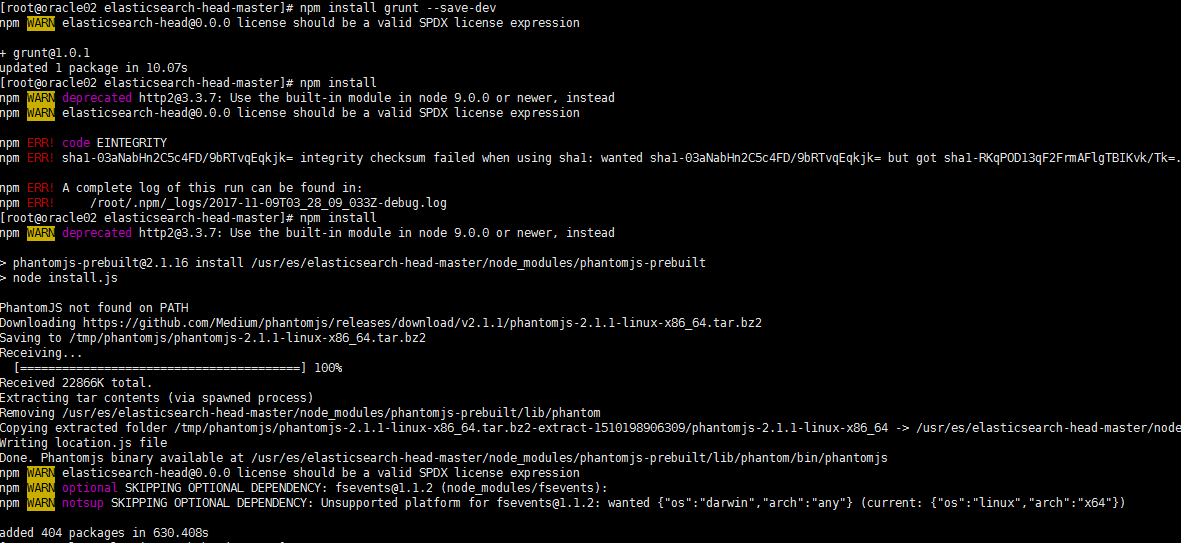
5.3.1 安装命令一:npm install grunt --save-dev
命令二:npm install
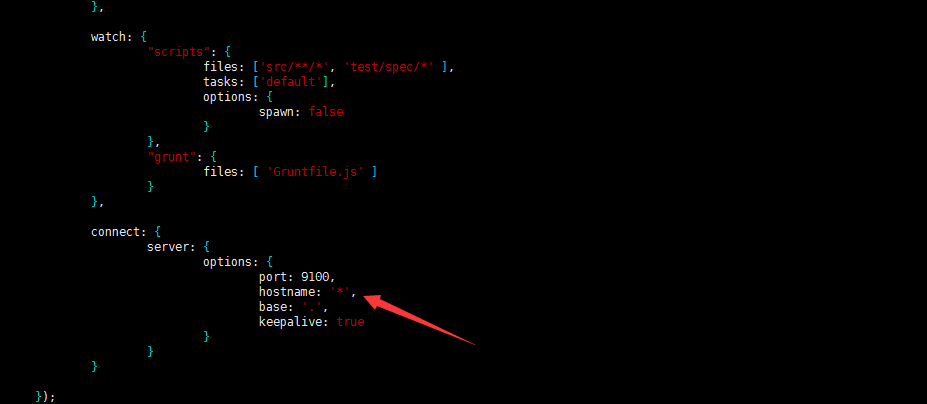
5.3.2 修改配置文件,cd 进入elasticsearch-head-master 文件夹下,执行命令vim Gruntfile.js文件:增加hostname属性,设置为*;如图:
5.3.3 修改 vim _site/app.js 文件:修改head的连接地址:,如图所示:

5.3.4 最后一个命令: grunt server & 执行完成后就OK了
5.3.5 涉及到的问题,在网页上无法正常访问;查看防火墙是否关闭
5.3.5.1 执行命令service iptables status 查看状态 ;直接将防火墙关闭就好了 执行命令service iptables stop

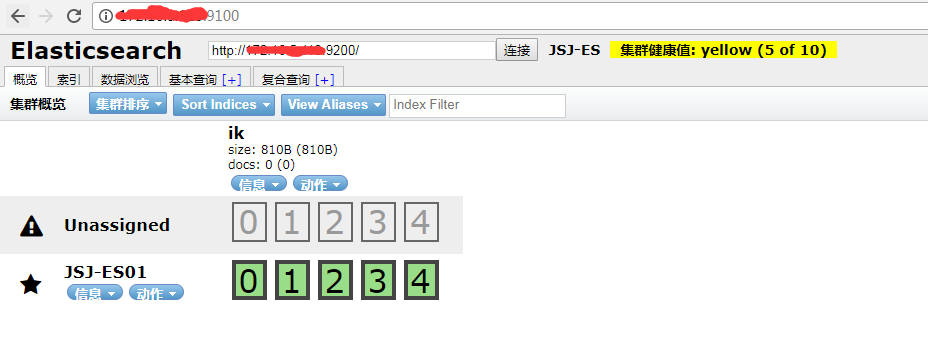
最后执行的结果是这样的,我没有配置集群: 注意下面使用的端口号,不在是9200 了 而是head 插件中的 9100 了

看到上面的出现的健康值了吗,说明的连接还是有问题的,解决方案是修改 cd 命令进入到elasticsearch-5.6.3 /config 文件中 vi elasticsearch.yml
文件下添加 :
http.cors.enabled: true
http.cors.allow-origin: "*"

然后重新执行ES ./elasticsearch 成功起来就可以了,执行结果就是这样的
欢迎各位朋友拍砖,相互学习!!!
转:linux 安装 Elasticsearch5.6.x 详细步骤以及问题解决方案的更多相关文章
- linux 安装 Elasticsearch5.6.x 详细步骤以及问题解决方案
在网上有很多那种ES步骤和问题的解决 方案的,不过没有一个详细的整合,和问题的梳理:我就想着闲暇之余,来记录一下自己安装的过程以及碰到的问题和心得:有什么不对的和问题希望及时拍砖. 第一步:环境 li ...
- linux 安装 Elasticsearch6.4.0详细步骤以及问题解决方案
1.jdk 安装 参考资料:https://www.cnblogs.com/shihaiming/p/5809553.html 2.elasticsearch 安装 下载:https://artifa ...
- linux下vsftpd的安装及配置使用详细步骤(推荐)
vsftpd 是“very secure FTP daemon”的缩写,安全性是它的一个最大的特点. vsftpd 是一个 UNIX 类操作系统上运行的服务器的名字,它可以运行在诸如 Linux.BS ...
- Linux如何安装JDK1.8版本详细步骤
Linux如何安装JDK1.8版本详细步骤 1.下载JDK1.8版本压缩包 进入官网:https://www.oracle.com/java/technologies/downloads/ 2.将压缩 ...
- 在Linux 安装Python3.5.6详细文档!!!!
在Linux 安装Python3.5.6详细文档!!!! 1.安装相关依赖库(工具包) yum install gcc patch libffi-devel python-devel zlib-de ...
- centos7安装zabbix3.0超详细步骤解析
centos7安装zabbix3.0超详细步骤解析 很详细,感谢作者 以下是我操作的history 622 java -version 623 javac -version 624 grep SELI ...
- 在U盘上安装Windows 7的详细步骤
买到苹果新款MacBook Air后大家最想干的事是什么?体验一下Mac OS X?事实告诉我们有几乎一半的人第一件想要做的事是装一个微软的Windows系统,但问题是新版的MBA已经没有光驱了,这可 ...
- win10 anaconda3 python3.6安装tensorflow keras tensorflow_federated详细步骤及在jupyter notebook运行指定的conda虚拟环境
本文链接:https://blog.csdn.net/weixin_44290661/article/details/1026789071. 安装tensorflow keras tensorflow ...
- ubuntu/linux中安装Tomcat(附图解详细步骤)
我的linux系统使用的是ubuntu14 1.首先需要先到Tomcat官网上下载对应linux系统的压缩包,可以直接在Ubuntu系统中进行下载,下载后的默认路径为主文件夹路径下的下载文件目录下 注 ...
随机推荐
- (十二)golang--进制和位运算
1.基本进制 (1)二进制:0,1,满2进1 在golang中,不能直接使用一个二进制表示一个整数,可以用八进制.十进制和十六进制表示 (2)十进制:0-9,满10进1 (3)八进制:0-7,满8进1 ...
- 安装Windows和Ubuntu双系统--Ubuntu安装过程识别不了硬盘
Linux识别不了固态硬盘 安装过程: 自己本身的是Windows 10,一块125g 固态 ,一块1T的机械硬盘. 通过rufus 制作ubuntu的启动盘 在BIOS中关闭电脑的安全启动选项,并且 ...
- web常用自动化库——selenium总结
概述 selenium是一个模拟控制浏览器操作的自动化库,它可以做到元素定位,鼠标事件,浏览器事件,js脚本执行等操作 与request不同的是,request是单独请求一个http,而seleniu ...
- python3学习,有c++的基础
# 为注释一行 ''' ''' 和 """ """为注释多行 用缩进表示代码块,不用{},同一等级代码用的缩进数一致 一条语句写在多行:a= ...
- javascript 解决默认取整的坑(目前已知的最佳解决方案)
javascript 解决默认取整的坑(目前已知的最佳解决方案) 复现该问题 js在数字操作时总会取更高精度的结果,例如1234/10结果就是123.4,但是在c或者java中整数除以10的结果还是整 ...
- Python 面向对象-上篇
概述 面向过程:根据业务逻辑从上到下写垒代码 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可 面向对象:对函数进行分类和封装,让开发“更快更好更强...” 面向过程编程最易被初学 ...
- PhpStudy BackDoor2019 深度分析
笔者<Qftm>原文发布<合天>:https://mp.weixin.qq.com/s?__biz=MjM5MTYxNjQxOA==&mid=2652852661&am ...
- 移动端自动化测试Appium环境搭建(part1-2-3)
Appium移动端自动化测试相信大家都不陌生,appium的铁哥们是selenium,不管是selenium还是appium,都是调用webdriver来做自动化测试.今天关于appium的介绍我们不 ...
- SpringSecurity退出功能实现的正确方式
本文将介绍在Spring Security框架下如何实现用户的"退出"logout的功能.其实这是一个非常简单的功能,我见过很多的程序员在使用了Spring Security之后, ...
- 你真的会用JavaScript中的sort方法吗
在平时的业务开发中,数组(Array) 是我们经常用到的数据类型,那么对数组的排序也很常见,除去使用循环遍历数组的方法来排列数据,使用JS数组中原生的方法 sort 来排列(没错,比较崇尚JS原生 ...