利用python爬虫关键词批量下载高清大图
前言
在上一篇写文章没高质量配图?python爬虫绕过限制一键搜索下载图虫创意图片!中,我们在未登录的情况下实现了图虫创意无水印高清小图的批量下载。虽然小图能够在一些移动端可能展示的还行,但是放到pc端展示图片太小效果真的是很一般!建议阅读本文查看上一篇文章,在具体实现不做太多介绍,只讲个分析思路。
当然,本文可能技术要求不是特别高,但可以当作一个下图工具使用。
环境:python3+pycharm+requests+re+BeatifulSoup+json
 在这里插入图片描述
在这里插入图片描述
这个确实也属实有一些勉强,不少童鞋私信问我有木有下载大图的源码,我说可能会有,现在分享给大家。
当然对于一个图片平台来说,高质量图片下载可能是其核心业务,并且我看了以下,那些高质量大图下载起来很贵!所以笔者并没有尝试付费下载然后查看大图的地址,因为这个可以猜想成功率很低,并且成本比较高,退而求其次,笔者采取以下几种方法。
对图虫平台初步分析之后,得到以下观点:
- 原版高质量无水印图片下载太贵,由于没付费下载没有找到高质量图的高清无水印原图真实地址。没有办法(能力) 下载原版高清无水印。并且笔者也能猜测这个是一个网站的核心业务肯定也会层层设套。不会轻易获得,所以并没有对付费高清高质量无水印图片穷追不舍。
- 但是高质量展示图在预览时候的是可以查看带有水印的高清图的(带着图虫创意水印)。
- 网站有一些免费的高清大图图片可以获取到。虽然这个
不是精选图,但是质量也还可以!
下载免费高清大图
在图虫创意有个板块的图片是免费开放的。在共享图片专栏。的图片可以搜索下载。
https://stock.tuchong.com/topic?topicId=37 图虫创意url地址
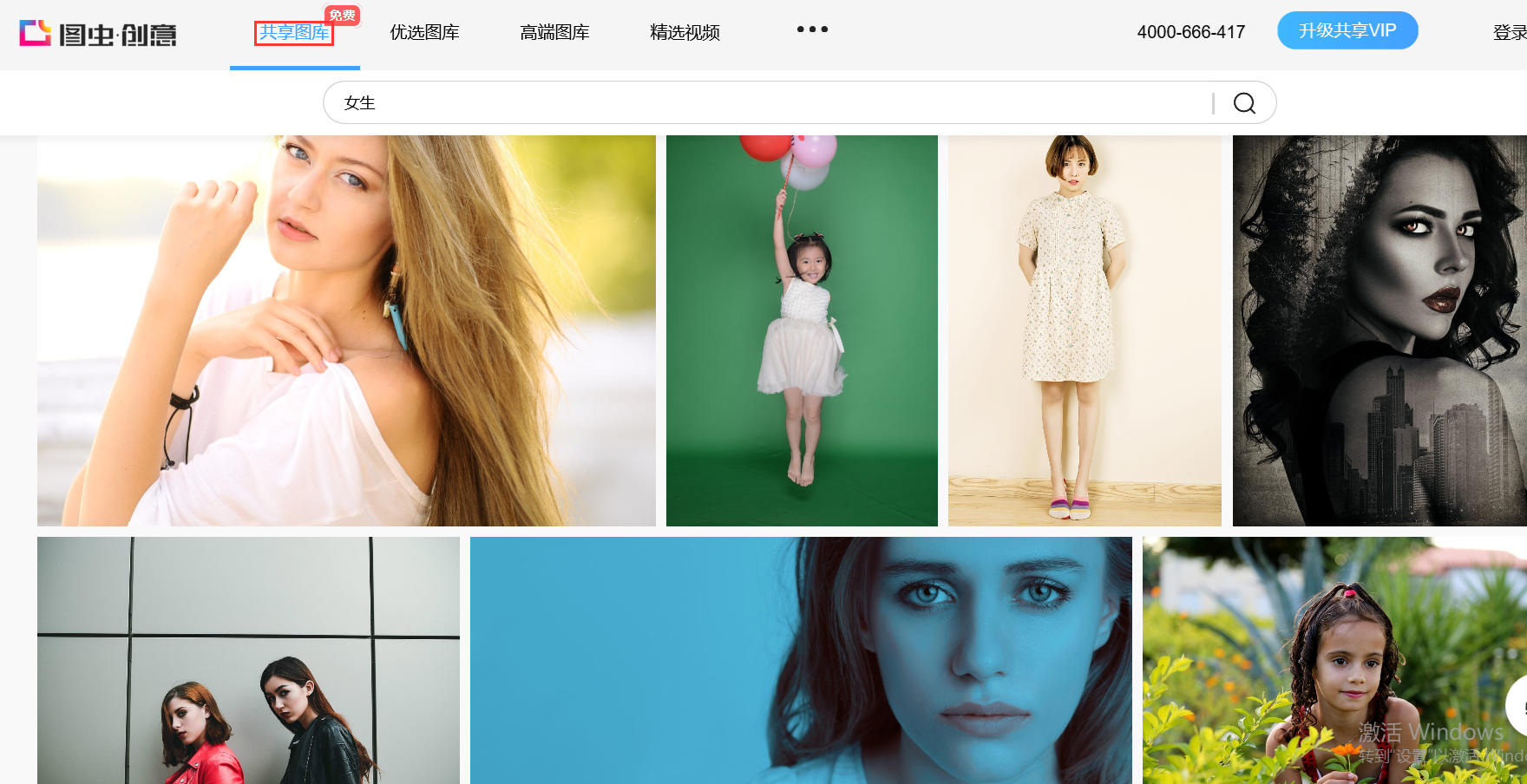 在这里插入图片描述
在这里插入图片描述
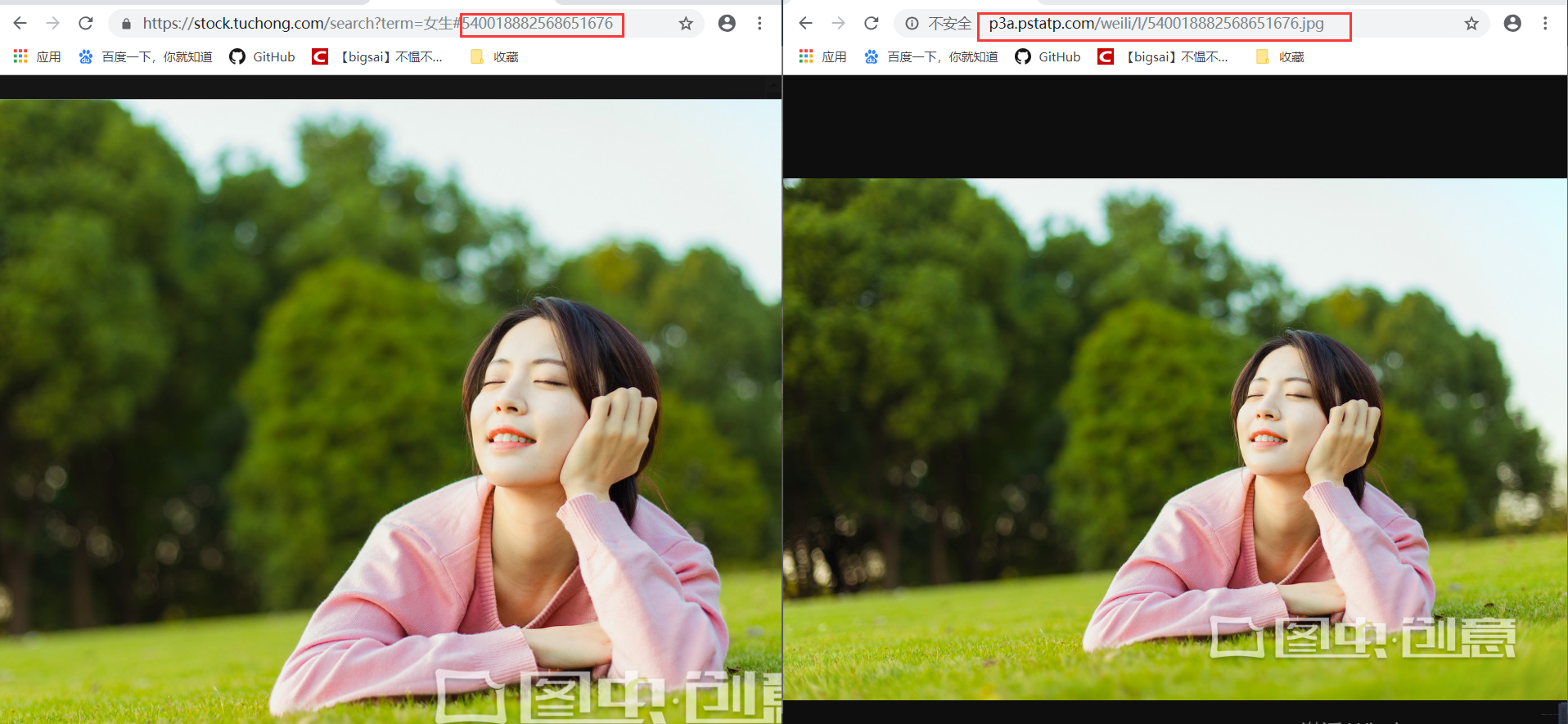
找到一张图片点进去,检查地址你可以直接访问得到。而有相关因素的就是一个图片服务器域名+图片id组成的图片url地址。也就是我们要批量找到这些图片的id。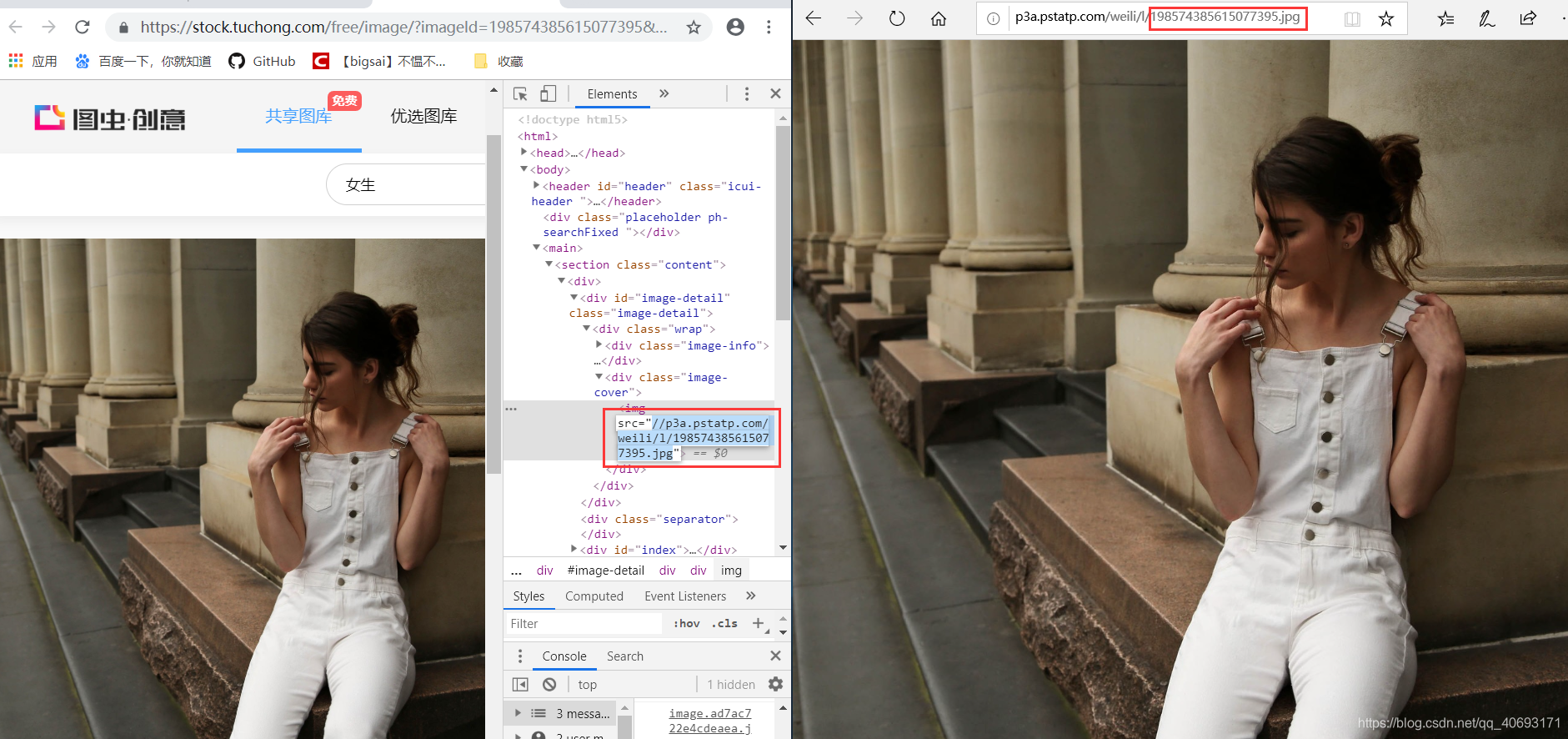 在这里插入图片描述
在这里插入图片描述
在搜索界面查看源码,发现这个和前面的分析如出一辙,它的图片id藏在js里面。我们只需通过正则解析。拿到id然后拼凑url即可完成所有图片地址,这个解析方式和上文基本完全一致,只不过是浏览器的URL和js的位置有相对的变化只需小量修改,然后直接爬虫下载保存即可!而这个搜索html的url就是https://stock.tuchong.com/free/search/?term=+搜索内容。这个下载内容的实现在上一篇已经分析过。请自行查看或看下文代码!这样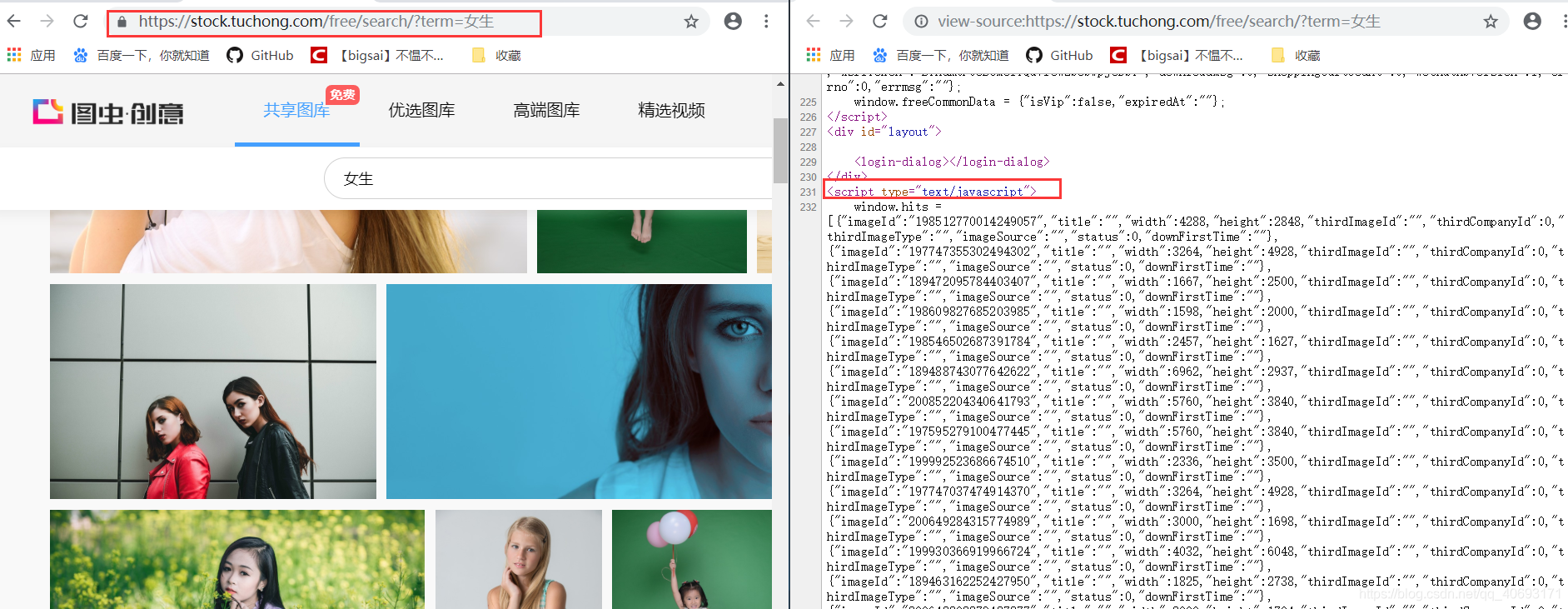 在这里插入图片描述
在这里插入图片描述
下载带水印的精选图
好的图片都在优选图片专栏。然而这部分图片我们可以免费获取带水印的图片。
在登录账号之后点开的图片预览,当你点开预览的时候是可以看得到图片的。每张图片对应一个唯一ID,这个地址可以获得但是比较麻烦。我们尝试能不能获得一个简单通用的url地址呢?
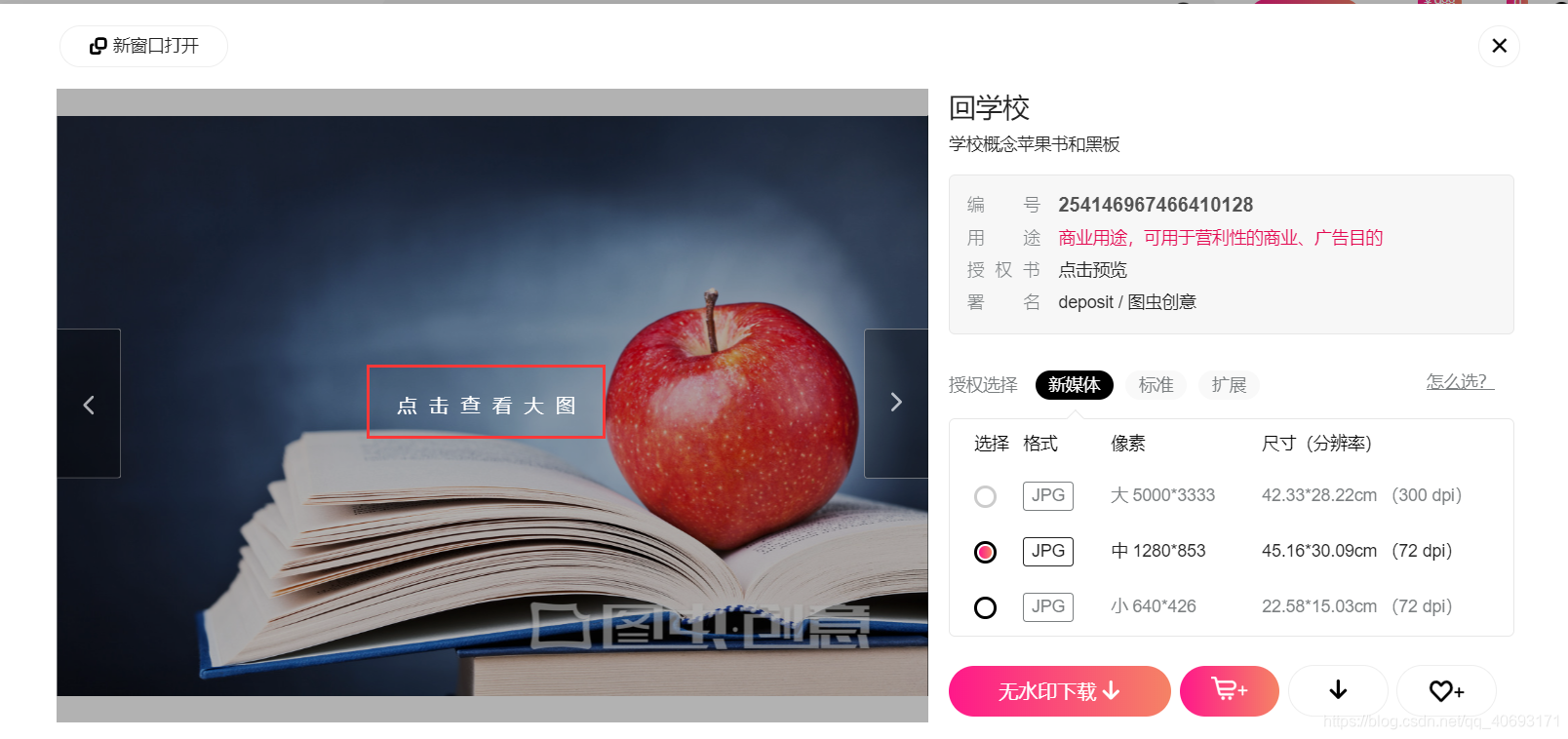 在这里插入图片描述
在这里插入图片描述
经过尝试发现这个图片的url可以在我们上面的免费高清大图url地址共用!也就是我们可以得到这个ID通过上个url来批量获取下载图片!下载图片的方法一致不需要重复造轮子。而id的获取方法我们在下载高清小图就已经详细介绍过了也是一样的。那么分析就已经成功了,代码将在后面给出,这样我们可以下载带水印的高清大图了!
##js的解析规则:
#----
js=soup.select('script') js=js[4]
pattern = re.compile(r'window.hits = (\[)(.*)(\])')
va = pattern.search(str(js)).group(2)#解析js内容
#-------
 在这里插入图片描述
在这里插入图片描述
当然,就配图而言还是高质量图的质量高很多,如果可以接受的话可以使用。唯一缺点就是图创水印。
代码与总结
import requests
from urllib import parse
from bs4 import BeautifulSoup
import re
import json
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36',
'Cookie': 'wluuid=66; ',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-encoding': 'gzip, deflate, br',
'Accept-language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'connection': 'keep-alive'
, 'Host': 'stock.tuchong.com',
'Upgrade-Insecure-Requests': '1'
}
def mkdir(path):
import os# 引入模块
path = path.strip()# 去除首位空格
path = path.rstrip("\\") # 去除尾部 \ 符号
isExists = os.path.exists(path) # 判断路径是否存在 # 存在 True # 不存在 False
if not isExists: # 判断结果
os.makedirs(path)# 如果不存在则创建目录 # 创建目录操作函数
return True#print (path + ' 创建成功')
else:
# 如果目录存在则不创建,并提示目录已存在
#print(path + ' 目录已存在')
return False
def downloadimage(imageid,imgname):##下载大图和带水印的高质量大图
url = 'https://weiliicimg9.pstatp.com/weili/l/'+str(imageid)+'.webp'
url2 = 'https://icweiliimg9.pstatp.com/weili/l/'+str(imageid)+'.webp'
b=False
r = requests.get(url)
print(r.status_code)
if(r.status_code!=200):
r=requests.get(url2)
with open(imgname+'.jpg', 'wb') as f:
f.write(r.content)
print(imgname+" 下载成功")
def getText(text,free):
texturl = parse.quote(text)
url="https://stock.tuchong.com/"+free+"search?term="+texturl+"&use=0"
print(url)
req=requests.get(url,headers=header)
soup=BeautifulSoup(req.text,'lxml')
js=soup.select('script')
path=''
if not free.__eq__(''):
js=js[1]
path='无水印/'
else:
js=js[4]
path='图虫创意/'
print(js)
pattern = re.compile(r'window.hits = (\[)(.*)(\])')
va = pattern.search(str(js)).group(2)#解析js内容
print(va)
va = va.replace('{', '{').replace('}', '},,')
print(va)
va = va.split(',,,')
print(va)
index = 1
for data in va:
try:
dict = json.loads(data)
print(dict)
imgname='img2/'+path+text+'/'+dict['title']+str(index)
index+=1
mkdir('img2/'+path+text)
imgid=dict['imageId']
downloadimage(imgid,imgname)
except Exception as e:
print(e)
if __name__ == '__main__':
num=input("高质量大图带水印输入1,普通不带水印输入2:")
num=int(num)
free=''
if num==2:
free='free/'
text = input('输入关键词:')
getText(text,free)
这样,整个流程就完成了,对于目录方面,我也对图虫有水印的和没水印的进行了区分,供大家使用。在使用方面,先输入1或2(1代表有水印高质量图,2代表共享图),在输入关键词即可批量下载。
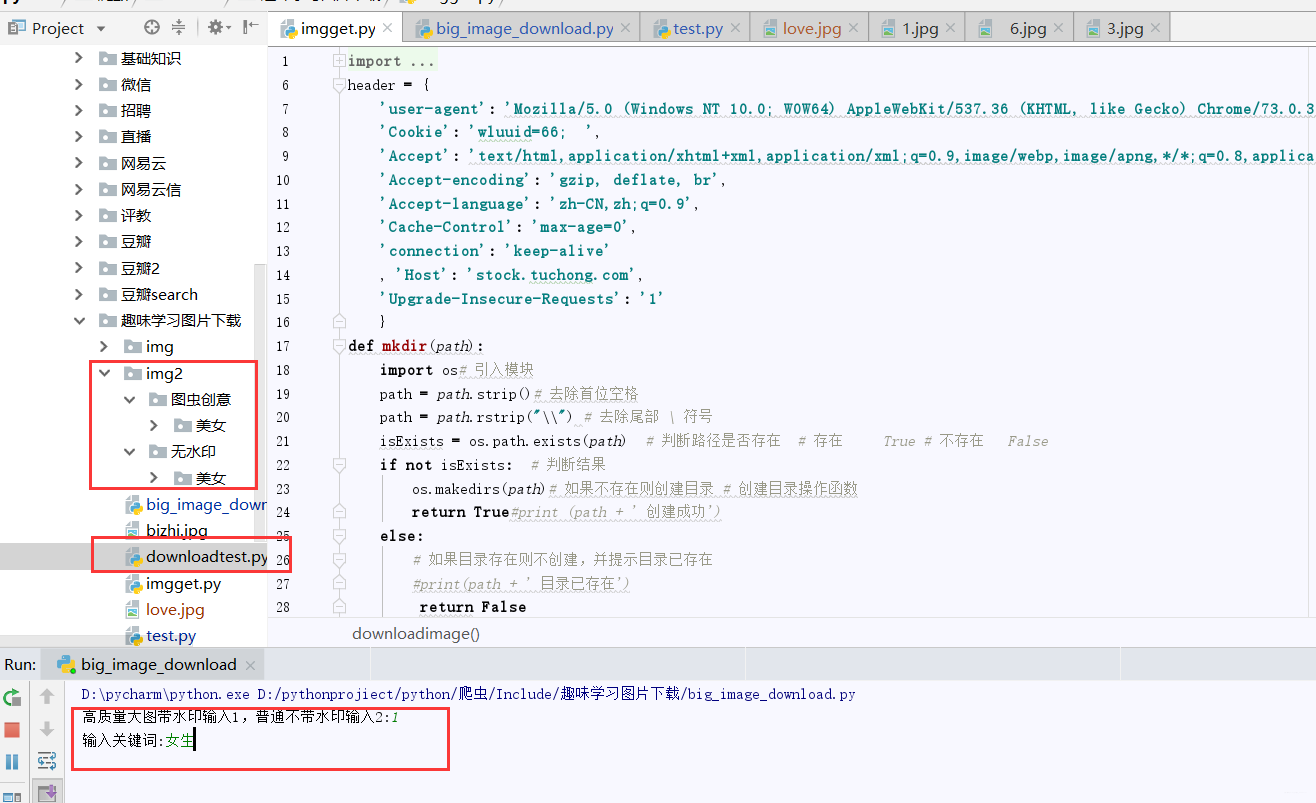 在这里插入图片描述
在这里插入图片描述 在这里插入图片描述
在这里插入图片描述
最后,如果感觉可以的话欢迎点赞呗!欢迎关注笔者公众号:bigsai
IT圈不嫌多一个朋友,笔者也希望能成为你的朋友,共同学习,共同进步!
利用python爬虫关键词批量下载高清大图的更多相关文章
- Python爬虫实战 批量下载高清美女图片
彼岸图网站里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过python爬虫批量下载网站里的高清美女图片,熟悉python写爬虫的基本方法: ...
- python爬虫-图片批量下载
# 爬起摄图网的图片批量下载# coding:utf-8 import requests from bs4 import BeautifulSoup from scipy.misc import im ...
- python妹子图爬虫5千张高清大图突破防盗链福利5千张福利高清大图
meizitu-spider python通用爬虫-绕过防盗链爬取妹子图 这是一只小巧方便,强大的爬虫,由python编写 所需的库有 requests BeautifulSoup os lxml 伪 ...
- Python静态网页爬取:批量获取高清壁纸
前言 在设计爬虫项目的时候,首先要在脑内明确人工浏览页面获得图片时的步骤 一般地,我们去网上批量打开壁纸的时候一般操作如下: 1.打开壁纸网页 2.单击壁纸图(打开指定壁纸的页面) 3.选择分辨率(我 ...
- 《Python金融大数据分析》高清PDF版|百度网盘免费下载|Python数据分析
<Python金融大数据分析>高清PDF版|百度网盘免费下载|Python数据分析 提取码:mfku 内容简介 唯一一本详细讲解使用Python分析处理金融大数据的专业图书:金融应用开发领 ...
- Python编程初学者指南PDF高清电子书免费下载|百度云盘
百度云盘:Python编程初学者指南PDF高清电子书免费下载 提取码:bftd 内容简介 Python是一种解释型.面向对象.动态数据类型的高级程序设计语言.Python可以用于很多的领域,从科学计算 ...
- python 爬取王者荣耀高清壁纸
代码地址如下:http://www.demodashi.com/demo/13104.html 一.前言 打过王者的童鞋一般都会喜欢里边设计出来的英雄吧,特别想把王者荣耀的英雄的高清图片当成电脑桌面 ...
- 学习推荐《从Excel到Python数据分析进阶指南》高清中文版PDF
Excel是数据分析中最常用的工具,本书通过Python与Excel的功能对比介绍如何使用Python通过函数式编程完成Excel中的数据处理及分析工作.在Python中pandas库用于数据处理,我 ...
- Python + Selenium +Chrome 批量下载网页代码修改【新手必学】
Python + Selenium +Chrome 批量下载网页代码修改主要修改以下代码可以调用 本地的 user-agent.txt 和 cookie.txt来达到在登陆状态下 批量打开并下载网页, ...
随机推荐
- C#开发BIMFACE系列16 服务端API之获取模型数据1:查询满足条件的构件ID列表
系列目录 [已更新最新开发文章,点击查看详细] 源文件/模型转换完成之后,可以获取模型的具体数据.本篇介绍根据文件ID查询满足条件的构件ID列表. 请求地址:GET https://api.b ...
- PHP小补充
code1-1 <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> < ...
- html基础——下拉式菜单
一个网站能否让用户容易使用该网站往往是由菜单栏体现出来,因为它为网页的大多数页面提供功能入口.一个轻轻的点击以后,即可显示出菜单项,将网站的大部分页面和功能显示出来让用户清楚了解从而用户节约一定的时间 ...
- win8调出右侧菜单栏
1.快捷键:win+c 2.鼠标放在右下角1s
- kick start 2019 round D T2题解
题目大意:由N个房子围成一个环,G个人分别顺时针/逆时针在房子上走,一共走M分钟,每分钟结束,每个人顺/逆时针走到相邻的房子.对于每个房子都会记录最后时刻到达的人(可能是一群人).最终输出每个人会被几 ...
- js中的兼容问题汇总
在使用js的过程中,往往会发现关于IE浏览器的兼容问题,当然微软现在自己也打算抛弃IE,推出了edge浏览器,对于前端来说是个好消息. 但IE的用户占比仍然不容小觑,因此这里整理下常见的几个兼容问题附 ...
- Educational Codeforces Round 68 Editorial
题目链接:http://codeforces.com/contest/1194 A.Remove a Progre ...
- SpringBoot发送邮箱验证码
一.开启QQ邮箱服务 (1)登陆QQ找到设置,点击账户 (2)往下拉,开启POP3/SMTP服务和IMAP/SMTP服务 当开启IMAP/SMTP会有一串密文密码,保存起来后面要用到 二.spring ...
- CSS特效集锦:视觉魔法的碰撞与融合(二)
引言 长久以来,我认识到.CSS,是存在极限的.正如曾经替你扛下一切的那个男人,也总有他眼含热泪地拼上一切,却也无法帮你做到的事情,他只能困窘地让你看到他的无能为力,怅然若失. 然后和曾经他成长的时代 ...
- 手把手告诉你如何安装多个版本的node,妈妈再也不用担心版本高低引发的一系列后遗症(非常详细,非常实用)
简介 最近好多人都问到node怎么同时安装多个版本? 如何配置node的环境变量,如何自如的在多个版本中切换node?还有就是自己在做appium自动化的时候,有时候会因为node的版本过高或者是太低 ...