C++ 过滤出字符串的中文(GBK,UTF-8)
最近在处理游戏敏感词之类的东西,为了加强屏蔽处理,所以需要过滤掉字符串中的除汉字之外的是其他东西如数字,符号,英文字母等。
首先我查阅资料并写了个函数:
示例:返回输入字符串中汉字的个数:
std::string StrWithOutSymbol(const std::string &source)
{
string sourceWithOutSymbol; int i = ;
while (source[i] != )
{
if (source[i] & 0x80 )
{
sourceWithOutSymbol += source[i];
sourceWithOutSymbol += source[i + ];
i += ;
else
{
i ++;
}
}
return
sourceWithOutSymbol;
}
这个函数的原理是ord($str)&0x80来判断汉字
80对应的二进制代码为1000 0000,最高位为一,代表汉字汉字编码格式通称为10格式一个汉字占2字节,但只代表一个字符
"Windows中,中文简体字符集的编码是同时用1个字节和2个字节来表示的。当高位是0x00~0x7f时,为一个字节,高位为0x80以上时用2个字节表示"
当你发现一个字节的内容大于0x7f,那它肯定是个(跟另外一个字节拼凑成一个)汉字,如何判断肯定大于0x7f呢?
0x7f(1111111)后面一个数就是0x80(10000000),所以想要大于0x7f,这个字节的最高位都肯定是1,我们只需要判断这个最高位是否为1就行了。
判断方法:
位与(相同的位都是1的才为1,否则为0):
如:要判断一个数的第三位是否是1,只要跟4(100)位与,判断一个数的第2位是否为1就跟2(10)位与.
同理判断第八位是否为1只要跟(10000000)也就是0x80位与了.
这里为什么不用>0x7f?php可能还行,但在其他强类型语言里面,1个字节的最高位用来标示负数,一个负数肯定不可能大于0x7f(最大的整数)
再举个例子:
a的assic码是97(1100001)
A的assic码是65(1000001)
b的assic码是98(1100010)
B的assic码是66(1000010)
发现一个规律:一个a-z的字母,只要是小写字母,第六位肯定是1,我们可以用这个来判断大小写:
这时候只要跟用以个字母跟0x20(100000)来位与判断:
if(ord($a)&0x20){
//大写
}
如何把所有字母改成大写?第六位的1改成0就行了:
$a='a';
$a = chr(ord($a)&(~0x20));
echo $a;
然后我信心满满的吧这个函数加入到项目中去,点击运行,输入中文进行检查,当!项目报错了????数组越界????
这是为什么,我又定位到报错的地方,发现我使用的cocos-lua,在向c++传递字符串的时候传进来的字符串是以UTF-8来进行编码的,我又去找UIF-8的编码规则发现
UTF-8编码规则:如果只有一个字节则其最高二进制位为0;如果是多字节,其第一个字节从最高位开始,连续的二进制位值为1的个数决定了其编码的字节数,其余各字节均以10开头。UTF-8转换表表示如下:
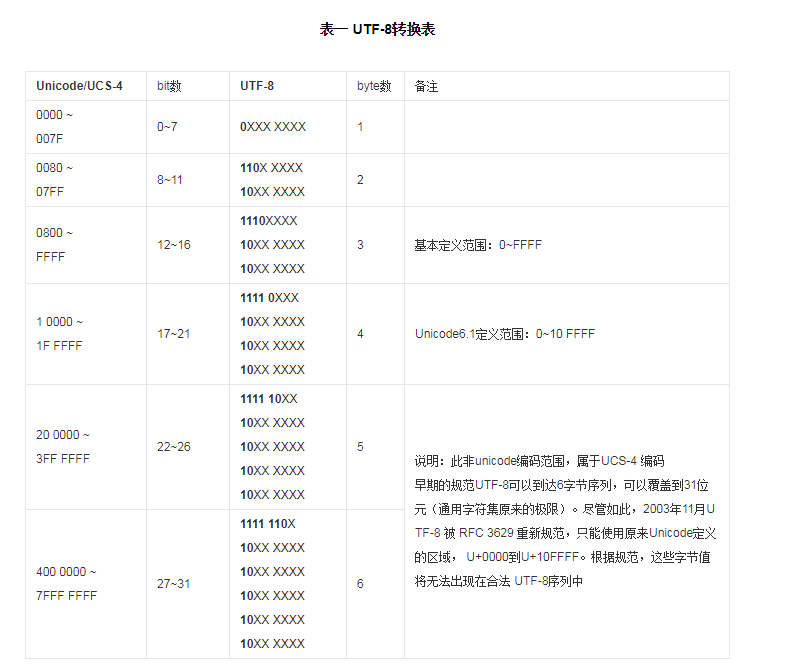
而我之前的是按照GBK编码进行操作的,GBK每个中文字符只占两个字节,而utf-8的话中文可能占3个字节,四个字节,甚至是五个六个,所以用刚才那样的函数就会有越界的情况发生,所以对用UTF-8进行编码的字符串,就需要进行另外的处理,所以我写了一个新函数:
对UTF-8编码的字符串进行中文筛选的函数:
std::string censorStrWithOutSymbol(const std::string &source)
{
string sourceWithOutSymbol; int i = ;
while (source[i] != )
{
if (source[i] & 0x80 && source[i] & 0x40 && source[i] & 0x20)
{
int byteCount = ;
if (source[i] & 0x10)
{
byteCount = ;
}
else
{
byteCount = ;
}
for (int a = ; a < byteCount; a++)
{
sourceWithOutSymbol += source[i];
i++;
}
}
else if (source[i] & 0x80 && source[i] & 0x40)
{
i += ;
}
else
{
i += ;
}
}
return sourceWithOutSymbol;
}
点击运行,成功了!舒服。
C++ 过滤出字符串的中文(GBK,UTF-8)的更多相关文章
- Java中过滤出字母、数字和中文的正则表达式
1.Java中过滤出字母.数字和中文的正则表达式 (1)过滤出字母的正则表达式 [^(A-Za-z)] (2)过滤出数字的正则表达式 [^(0-9)] (3)过滤出中文的正则表达式 [^(\\u4e0 ...
- AJPFX总结关于Java中过滤出字母、数字和中文的正则表达式
1.Java中过滤出字母.数字和中文的正则表达式 (1)过滤出字母的正则表达式 [^(A-Za-z)] (2) 过滤出 数字 的正则表达式 [^(0-9)] (3) 过滤出 中文 的正则 ...
- Java正则表达式过滤出字母、数字和中文
原文:http://blog.csdn.net/k21325/article/details/54090066 1.Java中过滤出字母.数字和中文的正则表达式 (1)过滤出字母的正则表达式 [^(A ...
- PHP用substr截取字符串出现中文乱码问题用mb_substr
PHP用substr截取字符串出现中文乱码问题用mb_substr实例:mb_substr('截取中文乱码问题测试',0,5, 'utf-8'); 语法 : string substr (string ...
- Python中文GBK编码解决实例
http://eatsalt.blog.163.com/blog/static/879402662009420508748/ #coding:gbk l=['我'.decode('gbk'),'我'. ...
- Qt5程序参数包含中文GBK编码的问题
1.背景 Qt5程序(WeekReport.exe)的main函数里有如下代码: //only for test int main(int argc, char *argv[]) { QCoreApp ...
- Java判断字符串是中文还是英文
在做开发的时候我们经常需要用到根据某个字符或者字符串来判断其是中文还是英文,从而做相应的处理,其实不难,大多数人们都是用到正则来判断的,下面小贝就给大家分享一下Java判断字符串是中文还是英文 推荐文 ...
- 通过freemarker生成一个word,解决生成的word用wps打开有问题的问题,解决出word时中文文件名乱码问题,解决打开出word时打开的word出现问题的问题,出图片,解决动态列表
通过freemarker制作word比较简单 步骤:制作word模板.制作方式是:将模板word保存成为xml----在xml的word模板中添加相应的标记----将xml的word文件的后缀名 ...
- C# 过滤特殊字符,保留中文,字母,数字,和-
#region public static string FilterChar(string inputValue) 过滤特殊字符,保留中文,字母,数字,和- /// <summary> ...
随机推荐
- 源码解读·RT-Thread小内存管理算法分析
这篇文章最初发布在RT-Thread官方论坛中,最近准备整理放到博客中来让更多人一起探讨学习. 2012年9月28日星期五 前言: 母语能力有限 概述: 这篇文字和大家分享一下今晚对RT-Thread ...
- Docker PHP7 Cannot find OpenSSL's <evp.h>
configure: error: Cannot find OpenSSL's <evp.h> apt-get install libssl-dev
- net开发框架never
[一] 摘要 never是纯c#语言开发的一个框架,同时可在netcore下运行. 该框架github地址:https://github.com/shelldudu/never 同时,配合never_ ...
- HBase 学习之路(八)——HBase协处理器
一.简述 在使用HBase时,如果你的数据量达到了数十亿行或数百万列,此时能否在查询中返回大量数据将受制于网络的带宽,即便网络状况允许,但是客户端的计算处理也未必能够满足要求.在这种情况下,协处理器( ...
- Mui a 链接失效的解决办法
方法一: mui('body').on('tap', 'a', function() { if(this.href){ //判断链接是否存在 location.href = this.href; ...
- 【粗略版】Linux deploy手机上创建自己的服务器
偶尔看见了一篇安卓手机z安装linux的文章,正好自己有一个旧手机,心里有个大胆的想法. 简单来说,就是把旧手机安装linux然后装上容器,尝试部署一个简单项目,下面会记录下过程: 首先了解下这个软件 ...
- 【转载】一起来学Spring Cloud | Eureka Client注册到Eureka Server的秘密
LZ看到这篇文章感觉写得比较详细,理解以后,便转载到自己博客中,留作以后回顾学习用,喝水不忘挖井人,内容来自于李刚的博客:http://www.spring4all.com/article/180 一 ...
- Linux上安装Nginx依赖环境和库、Nginx安装,Nginx服务命令
安装Nginx依赖环境和库.Nginx安装,Nginx服务命令 因为Nginx官方提供的是C源码,要自己进行编译,所以需要自己拥有编译所依赖的环境和库才可正常编译 安装gcc yum -y insta ...
- 前端页面统计beacon调研
目录 为什么使用beacon beacon特性 beacon 示例 参考资料 主要用于测试html的新特性beacon,使用beacon向后端发送请求,代替xhr或jsonp, 好处是支持页面unlo ...
- Python连载20-偏函数&zip函数&enumerate函数
一. 偏函数 二. #先举个例子 #把字符串转换为十进制数字 int(') #help(int),int函数中有一个参数base代表把它转换某个进制的数字 #把八进制的字符串转换为十进制 eight ...