Elasticsearch 7.x 之文档、索引和 REST API 【基础入门篇】
前几天写过一篇《Elasticsearch 7.x 最详细安装及配置》,今天继续最新版基础入门内容。这一篇简单总结了 Elasticsearch 7.x 之文档、索引和 REST API。
- 什么是文档
- 文档Unique ID
- 文档元数据
- 什么是索引
- REST API
一、索引文档(Document)
1.1 白话什么是文档
从使用案例出发,Elasticsearch 是面向文档,文档是所有搜索数据的最小单元。
案例一:每个公司都有业务日志平台,比如交易业务日志。
文档:每一条日志文件中的日志项,就是文档案例二:可以搜索并播放电影的在线视频网站
文档:每一个电影的具体信息,就是文档案例三:可以搜索并下载文件的云存储网站,类似百度云
文档:每一个文件具体内容信息,就是文档
等等案例很多,那么文档就是类似数据库里面的一条长长的存储记录。文档(Document)是索引信息的基本单位。
文档被序列化成为 JSON 格式,物理保存在一个索引中。JSON 是一种常见的互联网数据交换格式:
- 文档字段名:JSON 格式由 name/value pairs 组成,对应的 name 就是文档字段名
- 文档字段类型:每个字段都有对应的字段类型:String、integer、long 等,并支持数据&嵌套
1.2 文档的 Unique ID
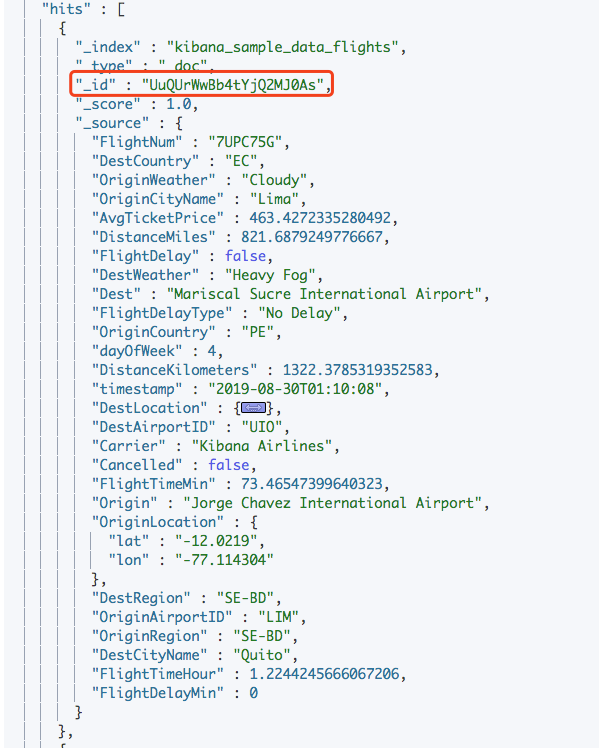
每个文档都会有一个 Unique ID,其字段名称为 _id :
- 自行设置指定 ID 或通过 Elasticsearch 自动生成
- 其值不会被索引
- 注意:该 _id 字段的值可以在某些查询 term, terms, match, query_string, simple_query_string 等中访问,但不能在 aggregations,scripts 或 sorting 中使用。如果需要对 _id 字段进行排序或汇总,建议新建一个文档字段复制 _id 字段的内容
PUT my_index/_doc/1
{
"text": "Document with ID 1"
}
PUT my_index/_doc/2&refresh=true
{
"text": "Document with ID 2"
}
GET my_index/_search
{
"query": {
"terms": {
"_id": [ "1", "2" ]
}
}
}
1.3 文档元数据

元数据是用于标注文档的相关信息,那么索引文档的元数据如下:
- _index 文档所属索引名称
- _type 文档所属类型名
- _id 文档唯一 ID
- _score 文档相关性打分
- _source 文档 JSON 数据
- _version 文档版本信息
其中 _type 文档所属类型名,需要关注版本不同之间区别:
- 7.0 之前,一个索引可以设置多个 types
- 7.0 开始,被 Deprecated 了。一个索引只能创建一个 type,值为 _doc
二、索引(Index)
2.1 索引不同意思
作为名词,索引代表是在 Elasticsearch 集群中,可以创建很多不同索引。也是本小节要总结的内容。
作为动词,索引代表保存一个文档到 Elasticsearch。就是在 Elasticsearch 创建一个倒排索引的意思
2.2 什么是索引
索引,就是相似类型文档的集合。类似 Spring Bean 容器装载着很多 Bean ,ES 索引就是文档的容器,是一类文档的集合。
以前导入了 kibana_sample_data_flights 索引,通过 GET 下面这个 URL ,就能得到索引一些信息:
GET http://localhost:9200/kibana_sample_data_flights
结果如下:
{
"kibana_sample_data_flights": {
"aliases": {},
"mappings": {
"properties": {
"AvgTicketPrice": {
"type": "float"
},
"Cancelled": {
"type": "boolean"
},
"Carrier": {
"type": "keyword"
},
"DestLocation": {
"type": "geo_point"
},
"FlightDelay": {
"type": "boolean"
},
"FlightDelayMin": {
"type": "integer"
},
"timestamp": {
"type": "date"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"auto_expand_replicas": "0-1",
"blocks": {
"read_only_allow_delete": "true"
},
"provided_name": "kibana_sample_data_flights",
"creation_date": "1566271868125",
"number_of_replicas": "0",
"uuid": "SfR20UNiSLKJWIpR1bcrzQ",
"version": {
"created": "7020199"
}
}
}
}
}
根据返回结果,我们知道:
- mappings:定义文档字段的类型
- settings:定义不同数据分布
- aliases:定义索引的别名,可以通过别名访问该索引
索引,是逻辑空间概念,每个索引有对那个的 Mapping 定义,对应的就是文档的字段名和字段类型。相比后面会讲到分片,是物理空间概念,索引中存储数据会分散到分片上。
实战经验总结:aliases 别名大有作为,比如 my_index 迁移到 my_index_new , 数据迁移后,只需要保持一致的别名配置。那么通过别名访问索引的业务方都不需要修改,直接迁移即可。
2.3 跟 MySQL 类比
基本理解了 Elasticsearch 重要的两个概念,可以将 ES 关键点跟关系型数据库类比如下:

三、REST API 方便 ES 被各种语言调用
如图,Elasticsearch 提供了 REST API,方便,相关索引 API 如下:
# 查看索引相关信息
GET kibana_sample_data_ecommerce
# 查看索引的文档总数
GET kibana_sample_data_ecommerce/_count
# 查看前10条文档,了解文档格式
POST kibana_sample_data_ecommerce/_search
{
}
# _cat indices API
# 查看indices
GET /_cat/indices/kibana*?v&s=index
# 查看状态为绿的索引
GET /_cat/indices?v&health=green
# 按照文档个数排序
GET /_cat/indices?v&s=docs.count:desc
# 查看具体的字段
GET /_cat/indices/kibana*?pri&v&h=health,index,pri,rep,docs.count,mt
# How much memory is used per index?
GET /_cat/indices?v&h=i,tm&s=tm:desc
具体 API 可以通过 POSTMan 等工具操作,或者安装 kibana ,对应的 Dev Tools
工具进行访问。
(完),更多可以看 ES 7.x 系列教程 bysocket.com
资料:
- Elasticsearch 7.x 最详细安装及配置
https://www.bysocket.com/elasticsearch/2417.html - 极客时间 Elasticsearch核心技术与实战
- CAT Index API https://www.elastic.co/guide/en/elasticsearch/reference/7.1/cat-indices.html
- 为什么不再支持单个Index下,多个Tyeps https://www.elastic.co/cn/blog/moving-from-types-to-typeless-apis-in-elasticsearch-7-0
转载,请保留原文地址,谢谢 ~
Elasticsearch 7.x 之文档、索引和 REST API 【基础入门篇】的更多相关文章
- 分布式文档存储数据库之MongoDB基础入门
一.MongoDB简介 MongoDB是用c++语言开发的一款易扩展,易伸缩,高性能,开源的,schema free 的基于文档的nosql数据库:所谓nosql是指不仅仅是sql的意思,它拥有部分s ...
- 详细描述一下 Elasticsearch 更新和删除文档的过程?
1.删除和更新也都是写操作,但是 Elasticsearch 中的文档是不可变的,因此不 能被删除或者改动以展示其变更: 2.磁盘上的每个段都有一个相应的.del 文件.当删除请求发送后,文档并没有真 ...
- Indri中的动态文档索引技术
Indri中的动态文档索引技术 戴维 译 摘要: Indri 动态文档索引的实现技术,支持在更新索引的同时处理用户在线查询请求. 文本搜索引擎曾被设计为针对固定的文档集合进行查询,对不少应用来说,这种 ...
- elasticsearch 5.x 系列之六 文档索引,更新,查询,删除流程
一.elasticsearch index 索引流程 步骤: 客户端向Node1 发送索引文档请求 Node1 根据文档ID(_id字段)计算出该文档应该属于shard0,然后请求路由到Node3的P ...
- 【ElasticSearch学习】之一图读懂文档索引全过程
ES索引过程详解: 1.客户端发送索引请求. 客户端向ES节点发送索引请求,以RestClient客户端发起请求为例: ES提供了Java High Level REST Client,用户可以通过R ...
- ElasticSearch 6.x 父子文档[join]分析
ES6.0以后,索引的type只能有一个,使得父子结构变的不那么清晰,毕竟对于java开发者来说,index->db,type->table的结构比较容易理解. 按照官方的说明,之前一个索 ...
- AUTOSAR-标准文档索引
https://mp.weixin.qq.com/s/6yl5dBP1mSFGVsfE7YRm6w 索引的两种方法: 关键字检索:用Document Search搜索下载,https://www. ...
- 几个方便的基于es 的开源文档索引系统
Apache Tika 比较有名的内容提取工具 FsCrawler 使用java 开发,内部使用了Tika Ambar nodejs,python应用开发,轻量,支持基于docker 的快速部署,同时 ...
- [API]使用Blueprint来高雅的编写接口文档 前后端api文档,移动端api文档
网址:http://apiary.io/ 介绍:一款非常强大的前后端交互api设计编辑工具(编辑器采用Markdown类似的描述标记,非常高效),高颜值的api文档,还能生成多种语言的测试代码. 中文 ...
随机推荐
- 逆向破解之160个CrackMe —— 030
CrackMe —— 030 160 CrackMe 是比较适合新手学习逆向破解的CrackMe的一个集合一共160个待逆向破解的程序 CrackMe:它们都是一些公开给别人尝试破解的小程序,制作 c ...
- Java连载29-方法执行内存分析、方法重载
一.JVM包含三个内存区:栈内存.堆内存.方法区内存 二.注意点 (1)在MyEclipse中字体是红色的是一个类的名字,并且这个类除了我们自定义的类是JavaSE类库中自带的 (2)其实JavaSE ...
- Redis缓存和数据库一致性问题
工作中,经常会遇到缓存和数据库数据一致性问题.从理论上设置过期时间,是保证最终一致性的解决方案.这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可 ...
- Linux防火墙管理
1.临时关闭防火墙 systemctl stop firewalld 2.查看防火墙运行状态 firewall-cmd --state 3.开启防火墙 systemctl start firewall ...
- Airflow:TypeError an integer is required (got type NoneType) 一次诡异问题排查
当使用rabbitmq作为airflow的broker的时候,启动scheduler,即执行airflow scheduler命令的时候抛出以下异常: Traceback (most recent ...
- map转java对象
pom依赖: <dependency> <groupId>commons-beanutils</groupId> <artifactId>commons ...
- Laravel 5.4 快速开发简书:
Laravel 5.4 快速开发简书第1章 课程介绍 介绍课程的大体脉络和课程安排 第2章 Laravel 5.4介绍 本节课会带领大家介绍laravel的各个版本历史以及讨论php框架的未来发展趋势 ...
- DirectX12 3D 游戏开发与实战第四章内容(下)
Direct3D的初始化(下) 学习目标 了解Direct3D在3D编程中相对于硬件所扮演的角色 理解组件对象模型COM在Direct3D中的作用 掌握基础的图像学概念,例如2D图像的存储方式,页面翻 ...
- centos下nc的安装和使用
安装:yum install nc.x86_64 发送文件: nc -l port < somefile.xxx 接收文件: nc -n x.x.x.x port > somefile.x ...
- MOOC 数据库系统笔记(二):数据库系统的基本结构及其演变发展
数据库系统的结构抽象与演变 数据库的标准结构 DBMS管理数据的三个层次 1.External Level = User Level 某一用户能够看到与处理的数据,全局数据中的某一部分 2.Conce ...