Paper | Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform
发表在2018年CVPR。
摘要
Despite that convolutional neural networks (CNN) have recently demonstrated high-quality reconstruction for single-image super-resolution (SR), recovering natural and realistic texture remains a challenging problem. In this paper, we show that it is possible to recover textures faithful to semantic classes. In particular, we only need to modulate features of a few intermediate layers in a single network conditioned on semantic segmentation probability maps. This is made possible through a novel Spatial Feature Transform (SFT) layer that generates affine transformation parameters for spatial-wise feature modulation. SFT layers can be trained end-to-end together with the SR network using the same loss function. During testing, it accepts an input image of arbitrary size and generates a high-resolution image with just a single forward pass conditioned on the categorical priors. Our final results show that an SR network equipped with SFT can generate more realistic and visually pleasing textures in comparison to state-of-the-art SRGAN [27] and EnhanceNet [38].
结论
We have explored the use of semantic segmentation maps as categorical prior for constraining the plausible solution space in SR. A novel Spatial Feature Transform (SFT) layer has been proposed to efficiently incorporate the categorical conditions into a CNN-based SR network. Thanks to the SFT layers, our SFT-GAN is capable of generating distinct and rich textures for multiple semantic regions in a super-resolved image in just a single forward pass. Extensive comparisons and a user study demonstrate the capability of SFT-GAN in generating realistic and visually pleasing textures, outperforming previous GAN-based methods [27, 38]. Our work currently focuses on SR of outdoor scenes.
Despite robust to out-of-category images, it does not consider priors of finer categories, especially for indoor scenes, e.g., furniture, appliance and silk. In such a case, it puts forward challenging requirements for segmentation tasks from an LR image. Future work aims at addressing these shortcomings. Furthermore, segmentation and SR may benefit from each other and jointly improve the performance.
要点
本文的重点,是在SR时更好地恢复自然纹理信息。
具体而言,通过输入语义分割概率图(semantic segmentation probability maps),为CNN提供类别先验(categorical priors),从而让纹理与类别一一对应。
实现该功能的网络层称为空域特征转换层(spatial feature transform layer)。它可以生成对空域特征进行仿射变换的参数,并且与SR网络一起训练。
尽管SFT-GAN对于未知类别的图像也是健壮的,但未知类别确实是一个问题。
亮点
这算是一个借助语义分割信息的超分辨工作,思想符合逻辑,实验效果也好。Fig. 1给出了说明:

这种思想还可以拓展到其他先验,例如深度图(depth map),从而增强纹理的颗粒度(granularity)。
类似于BN,对特征进行正则化,从而置入类别先验。
局限
语义分割图是LR图像经过双三次插值后,输入已训练好的分割网络[31]得到的,与超分辨网络独立。
作者通过仿射变换特征的方式,置入类别先验。这种方式有效果,但可能还有更好的方式。
故事背景
如上图,如果缺乏对类别的先验,我们的解空间是很难约束的。特别是对于两个相似的场景,如上图的植物和砖块。
历史工作中,就有人专门对不同的分类训练各自的模型。但在这里,作者想让语义分割图作为CNN的输入。关键就在于如何输入。如果只是简单地输入分割图,或者在中间层输入分割图,效果是不好的。
空域特征转换
为了解决语义分割图的输入有效性问题,我们引出了空域特征转换(SFT)层。
实际上,SFT的思想起源于BN。BN是对特征作仿射变换。条件正则化(conditional normalization, CN)则是采用在某条件下学习得到的函数,代替BN中的仿射变换。那么SFT是怎么做的呢?
具体而言,SFT基于先验,输出调整参数对(modulation parameter pair)\((\gamma, \beta)\)。该调整参数对将会对中间层的特征\(F\)进行仿射变换:\(SFT(F|\gamma, \beta) = \gamma \odot F + \beta\),其中\(\odot\)是哈达玛乘积(逐点点乘)。换句话说:借助SFT,原本关于类别的先验,就转化为了调整参数信息。
在网络中是这么实现的:
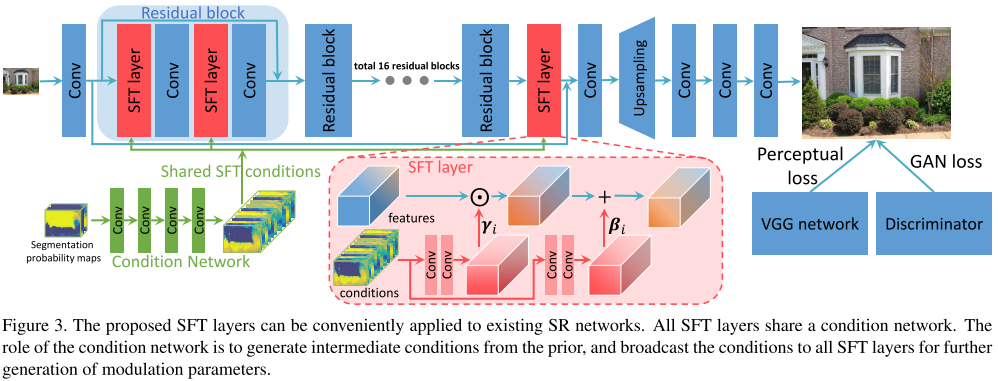
我们先关注SFT结构。
如图,分割概率图没有直接输入网络,而是先经过一个浅层CNN学习,我们称之为condition network。
网络的输出(conditions)会在整个网络的每一个中间层共享。在内部,如图,conditions分别经过2层CNN,得到参数对即可。然后执行仿射变换,完毕。
4.3节实验发现,直接拼接分割信息图,效果是很差的。
超分辨率网络
我们首先看一看分割网络。
LR图像先经过了双三次插值升采样,然后经过分割网络[31],得到语义分割概率图。该网络是独立训练的,与我们现在的工作独立。
实验发现,哪怕经过放缩因子为4的降采样,分割效果也是不错的(如图4)。如果类别未知,那么该目标会落入背景(background)。
整体结构是一个GAN,参见3.2节。
实验略。
Paper | Recovering Realistic Texture in Image Super-resolution by Deep Spatial Feature Transform的更多相关文章
- 使用深度学习的超分辨率介绍 An Introduction to Super Resolution using Deep Learning
使用深度学习的超分辨率介绍 关于使用深度学习进行超分辨率的各种组件,损失函数和度量的详细讨论. 介绍 超分辨率是从给定的低分辨率(LR)图像恢复高分辨率(HR)图像的过程.由于较小的空间分辨率(即尺寸 ...
- Computer Vision Applied to Super Resolution
Capel, David, and Andrew Zisserman. "Computer vision applied to super resolution." Signal ...
- Super Resolution
Super Resolution Accepted : 121 Submit : 187 Time Limit : 1000 MS Memory Limit : 65536 KB Super ...
- ASRWGAN: Wasserstein Generative Adversarial Network for Audio Super Resolution
ASEGAN:WGAN音频超分辨率 这篇文章并不具有权威性,因为没有发表,说不定是外国的某个大学的毕业设计,或者课程结束后的作业.或者实验报告. CS230: Deep Learning, Sprin ...
- Speech Super Resolution Generative Adversarial Network
博客作者:凌逆战 博客地址:https://www.cnblogs.com/LXP-Never/p/10874993.html 论文作者:Sefik Emre Eskimez , Kazuhito K ...
- Google Pixel 超分辨率--Super Resolution Zoom
Google Pixel 超分辨率--Super Resolution Zoom Google 的Super Res Zoom技术,主要用于在zoom时增强画面细节以及提升在夜景下的效果. 文章的主要 ...
- RAISR: rapid and accurate image super resolution
准确地说,RAISR并不是用来压缩图像的,而是用来upsample图像的. 众所周知,图片缩小到半分辨率后,在拉回原大小,会出现强烈的锯齿.从80年代开始就有很多super sampling的方法 ...
- 【论文学习】A Fuzzy-Rule-Based Approach for Single Frame Super Resolution
加尔各答印度统计研究所,作者: Pulak Purkait (pulak_r@isical.ac.in) 2013 年 代码:CodeForge.cn http://www.codeforge.cn/ ...
- paper 124:【转载】无监督特征学习——Unsupervised feature learning and deep learning
来源:http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio c ...
随机推荐
- docker搭建zookeeper集群
1.在官网拉取镜像 docker pull zookeeper 2.根据镜像启动zookeeper容器 docker run -itd --name zookeeper1 -h zookeeper1 ...
- BERT-wwm、BERT-wwm-ext、RoBERTa、SpanBERT、ERNIE2
一.BERT-wwm wwm是Whole Word Masking(对全词进行Mask),它相比于Bert的改进是用Mask标签替换一个完整的词而不是子词,中文和英文不同,英文中最小的Token就是一 ...
- golang数据结构之栈
stack.go package stack import ( "errors" "fmt" ) type Stack struct { MaxTop int ...
- 重磅来袭!Reactive 架构专场四城巡回演讲
Reactive 究竟是什么?Reactive 对架构设计的影响和冲击,以及给开发方式带来的改变有哪些?为什么阿里巴巴.Pivotal.Facebook 纷纷在生产环境中实践 Reactive? 本次 ...
- MySQL(8)---游标
Mysql(8)-游标 上一遍博客写了有关存储过程的语法知识 Mysql(7)---存储过程 游标或许你在工作中很少用到,但用不到不代表不去了解它,但你真正需要它来解决问题的时候,再花时间去学习很可能 ...
- Modbus RTU通信协议详解以及与Modbus TCP通信协议之间的区别和联系
Modbus通信协议由Modicon公司(现已经为施耐德公司并购,成为其旗下的子品牌)于1979年发明的,是全球最早用于工业现场的总线规约.由于其免费公开发行,使用该协议的厂家无需缴纳任何费用,Mod ...
- python基础(4):用户交互、if判断、while循环、break和continue
1. 用户交互 使⽤input()函数,可以让我们和计算机互动起来 语法: 内容 = input(提⽰信息) 这⾥可以直接获取到⽤户输入的内容 content = input("你吃了么?& ...
- 调用大漠插件发送QQ和微信消息 C#版
大漠插件:3.1233 找图,找色,识字,找字,窗口,按鼠标,按键盘 0.注册dm.dll: regsvr32 xxx\dm.dll 1.添加com引用: 2.dmsoft各种调用: 原理: 查找窗口 ...
- 如何给HTML页面设置行高
设置行高 由于简单还是老样子直接上代码了哦,注意:line-height属性值可以使用固定值如:20px..和百分比如:20%. 如果想让文字垂直居中如下:行高的主要作用是用来设置文本的垂直方向居中对 ...
- springboot依赖
springboot依赖整合 <parent> <groupId>org.springframework.boot</groupId> <artifactId ...