web安全之机器学习入门——3.2 决策树与随机森林
目录
简介
决策树简单用法
决策树检测P0P3爆破
决策树检测FTP爆破
随机森林检测FTP爆破
简介
决策树和随机森林算法是最常见的分类算法;
决策树,判断的逻辑很多时候和人的思维非常接近。
随机森林算法,利用多棵决策树对样本进行训练并预测的一种分类器,并且其输出的类别是由个别决策树输出的类别的众数决定。
决策树简单用法
使用sklearn自带的iris数据集
# -*- coding: utf- -*-
from sklearn.datasets import load_iris
from sklearn import tree
import pydotplus
"""
如果报错GraphViz's executables not found,手动添加环境变量
"""
import os
os.environ["PATH"] += os.pathsep + 'D:/Program Files (x86)/Graphviz2.38/bin/' #注意修改你的路径
iris = load_iris() clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target) #可视化训练得到的决策树
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("../photo/6/iris.pdf")
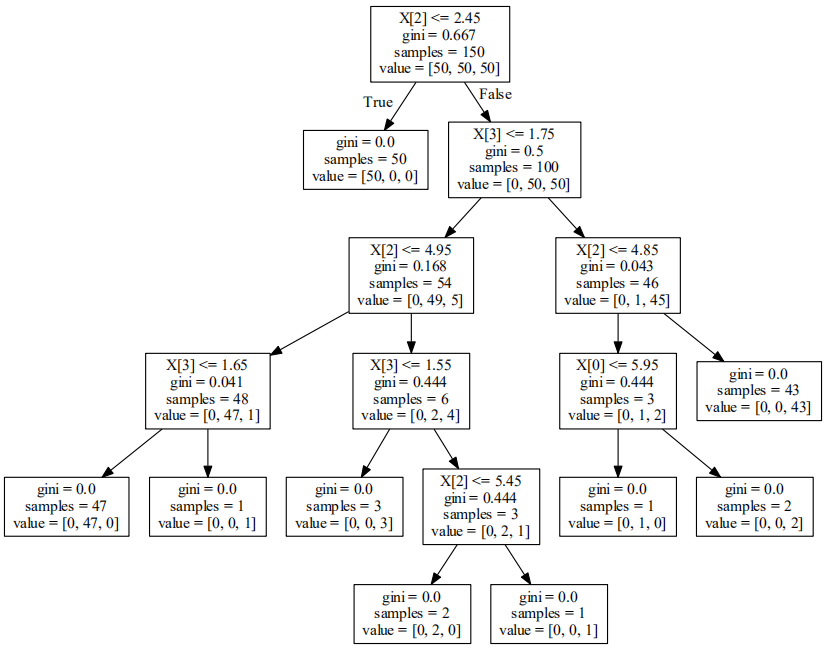
决策树算法检测P0P3爆破
# -*- coding:utf- -*- import re
from sklearn import cross_validation
from sklearn import tree
import pydotplus
import os
os.environ["PATH"] += os.pathsep + 'D:/Program Files (x86)/Graphviz2.38/bin/' #注意修改你的路径 """
收集并清洗数据
"""
def load_kdd99(filename):
x=[]
with open(filename) as f:
for line in f:
line=line.strip('\n')
line=line.split(',')
x.append(line)
return x def get_guess_passwdandNormal(x):
v=[]
w=[]
y=[]
"""
筛选标记为guess-passwd和normal且是P0P3协议的数据
"""
for x1 in x:
if ( x1[] in ['guess_passwd.','normal.'] ) and ( x1[] == 'pop_3' ):
if x1[] == 'guess_passwd.':
y.append()
else:
y.append()
"""
特征化
挑选与p0p3密码破解相关的网络特征以及TCP协议内容的特征作为样本特征
"""
x1 = [x1[]] + x1[:]+x1[:]
v.append(x1)
for x1 in v :
v1=[]
for x2 in x1:
v1.append(float(x2))
w.append(v1)
return w,y if __name__ == '__main__':
v=load_kdd99("../data/kddcup99/corrected")
x,y=get_guess_passwdandNormal(v)
"""
训练样本
实例化决策树算法
"""
clf = tree.DecisionTreeClassifier()
#十折交叉验证
print(cross_validation.cross_val_score(clf, x, y, n_jobs=-, cv=)) clf = clf.fit(x, y)
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("../photo/6/iris-dt.pdf")
准确率达到99%
[ 0.98637602 . . . . . .
. . . ]
可视化结果
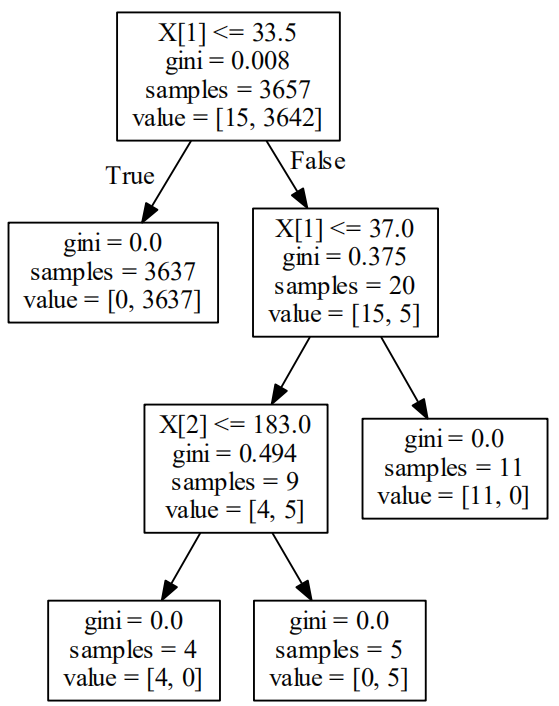
决策树算法检测FTP爆破
# -*- coding:utf- -*- import re
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import cross_validation
import os
from sklearn import tree
import pydotplus """ """
def load_one_flle(filename):
x=[]
with open(filename) as f:
line=f.readline()
line=line.strip('\n')
return line """
加载ADFA-LD中的正常样本数据
"""
def load_adfa_training_files(rootdir):
x=[]
y=[]
list = os.listdir(rootdir)
for i in range(, len(list)):
path = os.path.join(rootdir, list[i])
if os.path.isfile(path):
x.append(load_one_flle(path))
y.append()
return x,y """
定义遍历目录下文件的函数,作为load_adfa_hydra_ftp_files的子函数
"""
def dirlist(path, allfile):
filelist = os.listdir(path) for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
dirlist(filepath, allfile)
else:
allfile.append(filepath)
return allfile """
从攻击数据集中筛选和FTP爆破相关的数据
"""
def load_adfa_hydra_ftp_files(rootdir):
x=[]
y=[]
allfile=dirlist(rootdir,[])
for file in allfile:
"""
rootdir下有多个文件,多个文件里又有多个文件
"""
if re.match(r"../data/ADFA-LD/Attack_Data_Master/Hydra_FTP_\d+\\UAD-Hydra-FTP*",file):
x.append(load_one_flle(file))
y.append()
return x,y if __name__ == '__main__':
"""
特征化
由于ADFA-LD数据集都记录了函数调用的序列,每个文件包含的函数调用序列的个数都不一致
"""
x1,y1=load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/")
#x1{2184×833} y1{833}
x2,y2=load_adfa_hydra_ftp_files("../data/ADFA-LD/Attack_Data_Master/")
#x2{524×162} y2{162} x=x1+x2
y=y1+y2
#x{2184×995} y{955}
vectorizer = CountVectorizer(min_df=)
#min_df如果某个词的document frequence小于min_df,则这个词不会被当作关键词
x=vectorizer.fit_transform(x)
x=x.toarray()
#x{142×955}
#实例化决策树算法
clf = tree.DecisionTreeClassifier()
#效果验证
print(cross_validation.cross_val_score(clf, x, y, n_jobs=-, cv=)) clf = clf.fit(x, y)
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("../photo/6/ftp.pdf")
[ . 0.98019802 0.95 0.97979798 0.96969697 0.88888889
0.98989899 0.95959596 0.92929293 0.95959596]
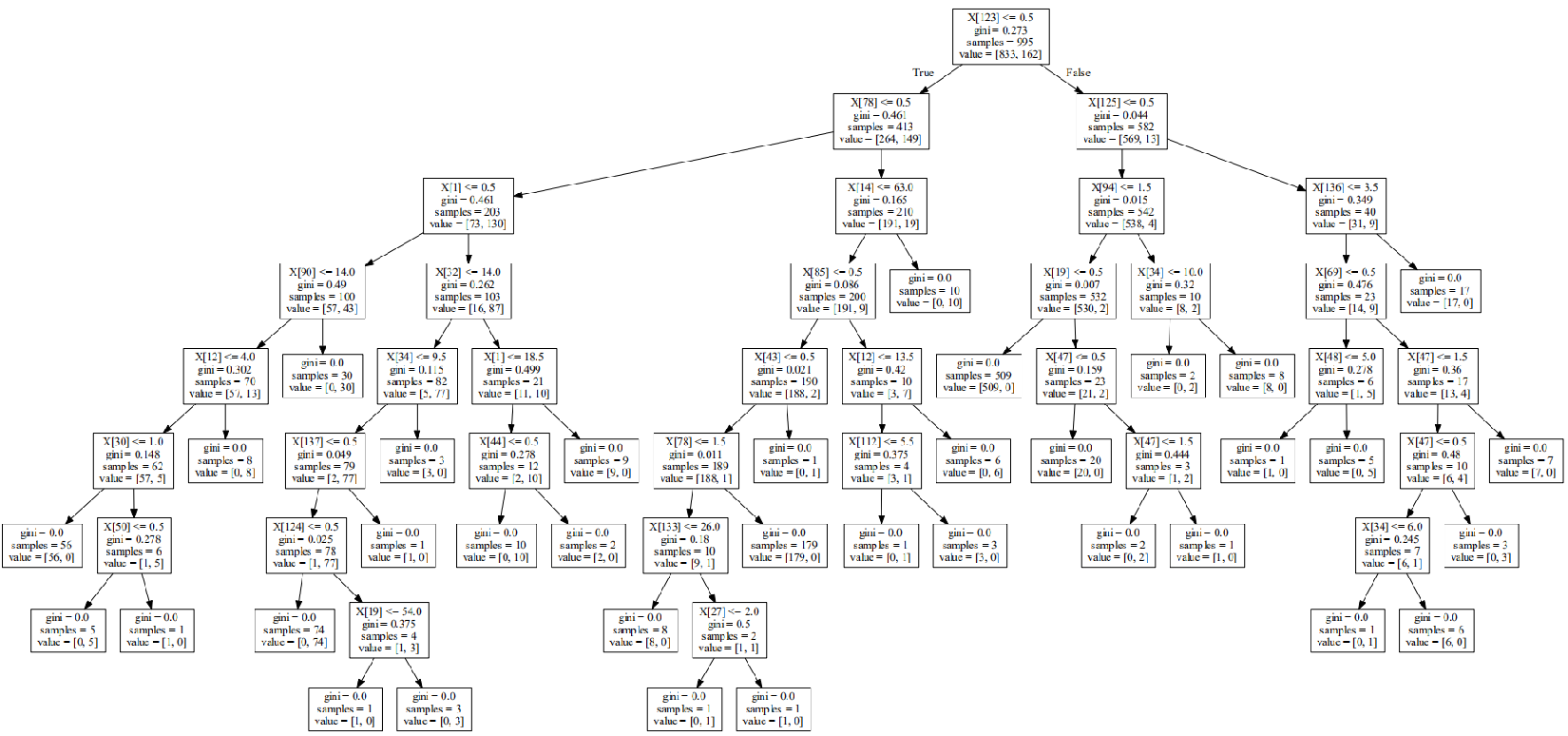
随机森林算法检测FTP爆破
# -*- coding:utf- -*-
#pydotplus只支持决策树
import re
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import cross_validation
import os
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
import numpy as np def load_one_flle(filename):
x=[]
with open(filename) as f:
line=f.readline()
line=line.strip('\n')
return line def load_adfa_training_files(rootdir):
x=[]
y=[]
list = os.listdir(rootdir)
for i in range(, len(list)):
path = os.path.join(rootdir, list[i])
if os.path.isfile(path):
x.append(load_one_flle(path))
y.append()
return x,y def dirlist(path, allfile):
filelist = os.listdir(path) for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
dirlist(filepath, allfile)
else:
allfile.append(filepath)
return allfile def load_adfa_hydra_ftp_files(rootdir):
x=[]
y=[]
allfile=dirlist(rootdir,[])
for file in allfile:
if re.match(r"../data/ADFA-LD/Attack_Data_Master/Hydra_FTP_\d+\\UAD-Hydra-FTP*",file):
x.append(load_one_flle(file))
y.append()
return x,y if __name__ == '__main__': x1,y1=load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/")
x2,y2=load_adfa_hydra_ftp_files("../data/ADFA-LD/Attack_Data_Master/") x=x1+x2
y=y1+y2
#print(x)
vectorizer = CountVectorizer(min_df=)
x=vectorizer.fit_transform(x)
x=x.toarray()
#print(y)
#选用决策树分类器
clf1 = tree.DecisionTreeClassifier()
score=cross_validation.cross_val_score(clf1, x, y, n_jobs=-, cv=)
print('决策树',np.mean(score))
#选用随机森林分类器
clf2 = RandomForestClassifier(n_estimators=, max_depth=None,min_samples_split=, random_state=)
score=cross_validation.cross_val_score(clf2, x, y, n_jobs=-, cv=)
print('随机森林',np.mean(score))
决策树 0.955736173617
随机森林 0.984888688869
web安全之机器学习入门——3.2 决策树与随机森林的更多相关文章
- web安全之机器学习入门——3.1 KNN/k近邻
目录 sklearn.neighbors.NearestNeighbors 参数/方法 基础用法 用于监督学习 检测异常操作(一) 检测异常操作(二) 检测rootkit 检测webshell skl ...
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
- 逻辑斯蒂回归VS决策树VS随机森林
LR 与SVM 不同 1.logistic regression适合需要得到一个分类概率的场景,SVM则没有分类概率 2.LR其实同样可以使用kernel,但是LR没有support vector在计 ...
- web安全之机器学习入门——2.机器学习概述
目录 0 前置知识 什么是机器学习 机器学习的算法 机器学习首先要解决的两个问题 一些基本概念 数据集介绍 1 正文 数据提取 数字型 文本型 数据读取 0 前置知识 什么是机器学习 通过简单示例来理 ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- chapter02 三种决策树模型:单一决策树、随机森林、GBDT(梯度提升决策树) 预测泰坦尼克号乘客生还情况
单一标准的决策树:会根每维特征对预测结果的影响程度进行排序,进而决定不同特征从上至下构建分类节点的顺序.Random Forest Classifier:使用相同的训练样本同时搭建多个独立的分类模型, ...
- 美团店铺评价语言处理以及分类(tfidf,SVM,决策树,随机森林,Knn,ensemble)
第一篇 数据清洗与分析部分 第二篇 可视化部分, 第三篇 朴素贝叶斯文本分类 支持向量机分类 支持向量机 网格搜索 临近法 决策树 随机森林 bagging方法 import pandas as pd ...
随机推荐
- 【HDFS API编程】副本系数深度剖析
上一节我们使用Java API操作HDFS文件系统创建了文件a.txt并写入了hello hadoop(回顾:https://www.cnblogs.com/Liuyt-61/p/10739018.h ...
- leetcode每日刷题计划-简单篇day13
Num 169 先码,回头再说,摩尔算法... tle了 class Solution { public: int majorityElement(vector<int>& num ...
- python爬虫相关
一.Python re模块的基本用法: https://blog.csdn.net/chenmozhe22/article/details/80601971 二.爬取网页图片 https://www. ...
- 编译安装Python3
转发https://www.cnblogs.com/resn/p/10135953.html 编译安装Python3 安装依赖 yum install -y ncurses-libs zlib-dev ...
- Python科学计算结果的存储与读取
Python科学计算结果的存储与读取 总结于2019年3月17日 荆楚理工学院 计算机工程学院 一.前言 显然,作为一名工科僧,执行科学计算,需用Python.PS:快忘记Matlab吧.我用了二十 ...
- servlet对象的生命周期
servlet对象默认第一次访问的时候创建,服务器关闭的时候销毁.当servlet对象创建的时候会调用init方法,当对象销毁的时候,会调用destroy方法,每次访问servlet时,都会调用ser ...
- nodeJs 使用 express-http-proxy 转发请求
开发过程中经常需要用到 nodeJs做转发层 使用express配合 express-http-proxy 可以轻松的完成转发 使用过程: 安装 express-http-proxy npm inst ...
- 手动(原生ajax)和自动发送ajax请求 伪ajax(Ifrname)
自动发送 ---> 依赖jQuery文件 实例-->GET请求: function AjaxSubmit() { $.ajax({ url:'/data', type:"GET ...
- MTK6261之Catcher工具的Database Path
在Catcher使用使用的时候我们常用要选择Database Path 设置数据库的路径,编译自动生成的文件: 设置路径选项: (一般是在对应工程文件的路径 \tst\database_classb) ...
- 深度学习实践-物体检测-faster-RCNN(原理和部分代码说明) 1.tf.image.resize_and_crop(根据比例取出特征层,进行维度变化) 2.tf.slice(数据切片) 3.x.argsort()(对数据进行排列,返回索引值) 4.np.empty(生成空矩阵) 5.np.meshgrid(生成二维数据) 6.np.where(符合条件的索引) 7.tf.gather取值
1. tf.image.resize_and_crop(net, bbox, 256, [14, 14], name) # 根据bbox的y1,x1,y2,x2获得net中的位置,将其转换为14*1 ...