web安全之机器学习入门——3.2 决策树与随机森林
目录
简介
决策树简单用法
决策树检测P0P3爆破
决策树检测FTP爆破
随机森林检测FTP爆破
简介
决策树和随机森林算法是最常见的分类算法;
决策树,判断的逻辑很多时候和人的思维非常接近。
随机森林算法,利用多棵决策树对样本进行训练并预测的一种分类器,并且其输出的类别是由个别决策树输出的类别的众数决定。
决策树简单用法
使用sklearn自带的iris数据集
# -*- coding: utf- -*-
from sklearn.datasets import load_iris
from sklearn import tree
import pydotplus
"""
如果报错GraphViz's executables not found,手动添加环境变量
"""
import os
os.environ["PATH"] += os.pathsep + 'D:/Program Files (x86)/Graphviz2.38/bin/' #注意修改你的路径
iris = load_iris() clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target) #可视化训练得到的决策树
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("../photo/6/iris.pdf")
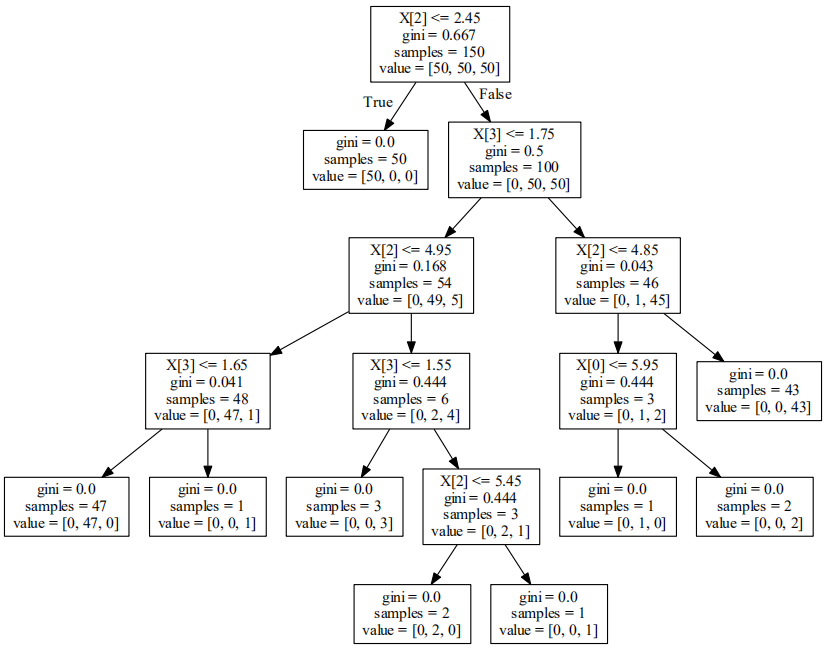
决策树算法检测P0P3爆破
# -*- coding:utf- -*- import re
from sklearn import cross_validation
from sklearn import tree
import pydotplus
import os
os.environ["PATH"] += os.pathsep + 'D:/Program Files (x86)/Graphviz2.38/bin/' #注意修改你的路径 """
收集并清洗数据
"""
def load_kdd99(filename):
x=[]
with open(filename) as f:
for line in f:
line=line.strip('\n')
line=line.split(',')
x.append(line)
return x def get_guess_passwdandNormal(x):
v=[]
w=[]
y=[]
"""
筛选标记为guess-passwd和normal且是P0P3协议的数据
"""
for x1 in x:
if ( x1[] in ['guess_passwd.','normal.'] ) and ( x1[] == 'pop_3' ):
if x1[] == 'guess_passwd.':
y.append()
else:
y.append()
"""
特征化
挑选与p0p3密码破解相关的网络特征以及TCP协议内容的特征作为样本特征
"""
x1 = [x1[]] + x1[:]+x1[:]
v.append(x1)
for x1 in v :
v1=[]
for x2 in x1:
v1.append(float(x2))
w.append(v1)
return w,y if __name__ == '__main__':
v=load_kdd99("../data/kddcup99/corrected")
x,y=get_guess_passwdandNormal(v)
"""
训练样本
实例化决策树算法
"""
clf = tree.DecisionTreeClassifier()
#十折交叉验证
print(cross_validation.cross_val_score(clf, x, y, n_jobs=-, cv=)) clf = clf.fit(x, y)
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("../photo/6/iris-dt.pdf")
准确率达到99%
[ 0.98637602 . . . . . .
. . . ]
可视化结果
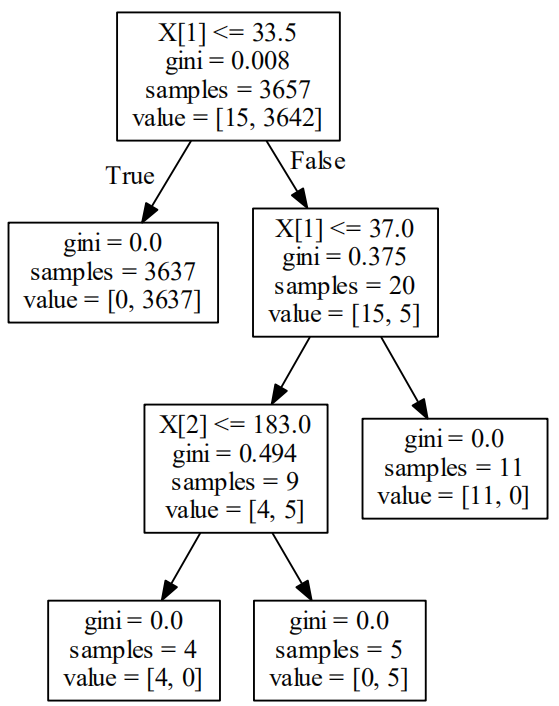
决策树算法检测FTP爆破
# -*- coding:utf- -*- import re
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import cross_validation
import os
from sklearn import tree
import pydotplus """ """
def load_one_flle(filename):
x=[]
with open(filename) as f:
line=f.readline()
line=line.strip('\n')
return line """
加载ADFA-LD中的正常样本数据
"""
def load_adfa_training_files(rootdir):
x=[]
y=[]
list = os.listdir(rootdir)
for i in range(, len(list)):
path = os.path.join(rootdir, list[i])
if os.path.isfile(path):
x.append(load_one_flle(path))
y.append()
return x,y """
定义遍历目录下文件的函数,作为load_adfa_hydra_ftp_files的子函数
"""
def dirlist(path, allfile):
filelist = os.listdir(path) for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
dirlist(filepath, allfile)
else:
allfile.append(filepath)
return allfile """
从攻击数据集中筛选和FTP爆破相关的数据
"""
def load_adfa_hydra_ftp_files(rootdir):
x=[]
y=[]
allfile=dirlist(rootdir,[])
for file in allfile:
"""
rootdir下有多个文件,多个文件里又有多个文件
"""
if re.match(r"../data/ADFA-LD/Attack_Data_Master/Hydra_FTP_\d+\\UAD-Hydra-FTP*",file):
x.append(load_one_flle(file))
y.append()
return x,y if __name__ == '__main__':
"""
特征化
由于ADFA-LD数据集都记录了函数调用的序列,每个文件包含的函数调用序列的个数都不一致
"""
x1,y1=load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/")
#x1{2184×833} y1{833}
x2,y2=load_adfa_hydra_ftp_files("../data/ADFA-LD/Attack_Data_Master/")
#x2{524×162} y2{162} x=x1+x2
y=y1+y2
#x{2184×995} y{955}
vectorizer = CountVectorizer(min_df=)
#min_df如果某个词的document frequence小于min_df,则这个词不会被当作关键词
x=vectorizer.fit_transform(x)
x=x.toarray()
#x{142×955}
#实例化决策树算法
clf = tree.DecisionTreeClassifier()
#效果验证
print(cross_validation.cross_val_score(clf, x, y, n_jobs=-, cv=)) clf = clf.fit(x, y)
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("../photo/6/ftp.pdf")
[ . 0.98019802 0.95 0.97979798 0.96969697 0.88888889
0.98989899 0.95959596 0.92929293 0.95959596]
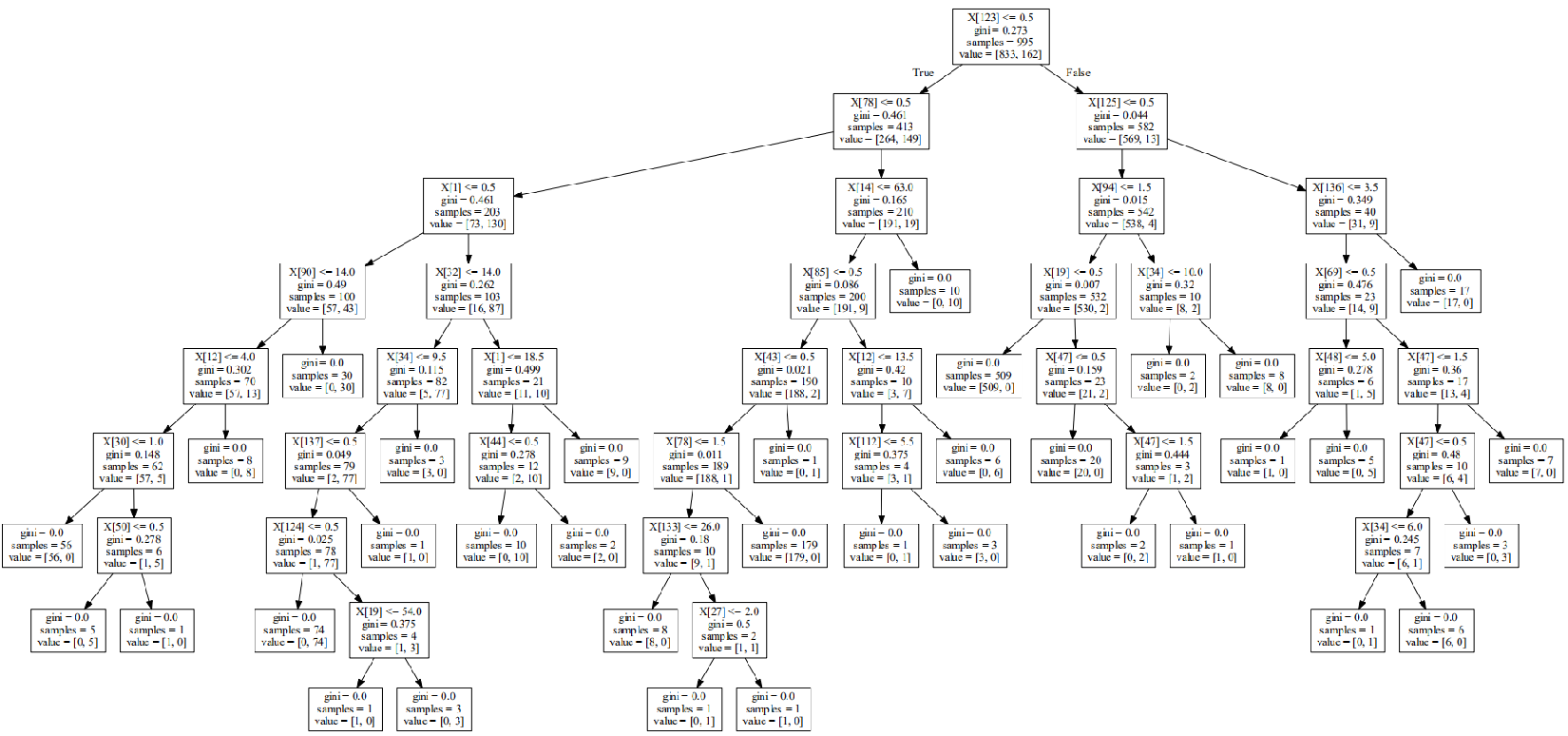
随机森林算法检测FTP爆破
# -*- coding:utf- -*-
#pydotplus只支持决策树
import re
import os
from sklearn.feature_extraction.text import CountVectorizer
from sklearn import cross_validation
import os
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
import numpy as np def load_one_flle(filename):
x=[]
with open(filename) as f:
line=f.readline()
line=line.strip('\n')
return line def load_adfa_training_files(rootdir):
x=[]
y=[]
list = os.listdir(rootdir)
for i in range(, len(list)):
path = os.path.join(rootdir, list[i])
if os.path.isfile(path):
x.append(load_one_flle(path))
y.append()
return x,y def dirlist(path, allfile):
filelist = os.listdir(path) for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
dirlist(filepath, allfile)
else:
allfile.append(filepath)
return allfile def load_adfa_hydra_ftp_files(rootdir):
x=[]
y=[]
allfile=dirlist(rootdir,[])
for file in allfile:
if re.match(r"../data/ADFA-LD/Attack_Data_Master/Hydra_FTP_\d+\\UAD-Hydra-FTP*",file):
x.append(load_one_flle(file))
y.append()
return x,y if __name__ == '__main__': x1,y1=load_adfa_training_files("../data/ADFA-LD/Training_Data_Master/")
x2,y2=load_adfa_hydra_ftp_files("../data/ADFA-LD/Attack_Data_Master/") x=x1+x2
y=y1+y2
#print(x)
vectorizer = CountVectorizer(min_df=)
x=vectorizer.fit_transform(x)
x=x.toarray()
#print(y)
#选用决策树分类器
clf1 = tree.DecisionTreeClassifier()
score=cross_validation.cross_val_score(clf1, x, y, n_jobs=-, cv=)
print('决策树',np.mean(score))
#选用随机森林分类器
clf2 = RandomForestClassifier(n_estimators=, max_depth=None,min_samples_split=, random_state=)
score=cross_validation.cross_val_score(clf2, x, y, n_jobs=-, cv=)
print('随机森林',np.mean(score))
决策树 0.955736173617
随机森林 0.984888688869
web安全之机器学习入门——3.2 决策树与随机森林的更多相关文章
- web安全之机器学习入门——3.1 KNN/k近邻
目录 sklearn.neighbors.NearestNeighbors 参数/方法 基础用法 用于监督学习 检测异常操作(一) 检测异常操作(二) 检测rootkit 检测webshell skl ...
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
- 逻辑斯蒂回归VS决策树VS随机森林
LR 与SVM 不同 1.logistic regression适合需要得到一个分类概率的场景,SVM则没有分类概率 2.LR其实同样可以使用kernel,但是LR没有support vector在计 ...
- web安全之机器学习入门——2.机器学习概述
目录 0 前置知识 什么是机器学习 机器学习的算法 机器学习首先要解决的两个问题 一些基本概念 数据集介绍 1 正文 数据提取 数字型 文本型 数据读取 0 前置知识 什么是机器学习 通过简单示例来理 ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- Python数据科学手册-机器学习: 决策树与随机森林
无参数 算法 随机森林 随机森林是一种集成方法,集成多个比较简单的评估器形成累计效果. 导入标准程序库 随机森林的诱因: 决策树 随机森林是建立在决策树 基础上 的集成学习器 建一颗决策树 二叉决策树 ...
- chapter02 三种决策树模型:单一决策树、随机森林、GBDT(梯度提升决策树) 预测泰坦尼克号乘客生还情况
单一标准的决策树:会根每维特征对预测结果的影响程度进行排序,进而决定不同特征从上至下构建分类节点的顺序.Random Forest Classifier:使用相同的训练样本同时搭建多个独立的分类模型, ...
- 美团店铺评价语言处理以及分类(tfidf,SVM,决策树,随机森林,Knn,ensemble)
第一篇 数据清洗与分析部分 第二篇 可视化部分, 第三篇 朴素贝叶斯文本分类 支持向量机分类 支持向量机 网格搜索 临近法 决策树 随机森林 bagging方法 import pandas as pd ...
随机推荐
- !!!常用bootstrap代码
http://v3.bootcss.com/components/ 组件 http://v3.bootcss.com/customize/ bootstrap定制 http://v3.bootcs ...
- python自动化,使用unittest对界面操作,读取excel表格数据输入到页面查询结果,在把结果保存到另外一张excel中
# -*- coding: utf-8 -*-from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom ...
- php laravel+nginx 除了根目录都报404 解决
在nginx的配置文件加 location / { try_files $uri $uri/ /index.php?$query_string; } 即可!!!!!!!
- java中Method.invoke方法参数解析
通过发射的机制,可以通过invoke方法来调用类的函数.invoke函数的第一个参数是调用该方法的实例,如果该方法是静态方法,那么可以用null或者用类来代替,第二个参数是变长的,是调用该方法的参数. ...
- eclipse中的javaEE插件
1.在Eclipse中菜单help选项中选择install new software选项 2.在work with 栏中输入 Juno - http://download.eclipse.org/re ...
- EMF32名词解释
(EFM32)32位节能微控制器(Energy Friendly Microcontroller 32-bit) (Gecko)壁虎 (Starter Kit)入门套件 (STK)入门套件 (Debu ...
- MySQL 8.0 中统计信息直方图的尝试
直方图是表上某个字段在按照一定百分比和规律采样后的数据分布的一种描述,最重要的作用之一就是根据查询条件,预估符合条件的数据量,为sql执行计划的生成提供重要的依据在MySQL 8.0之前的版本中,My ...
- 如何激活已经运行过的Activity, 而不是重新启动新的Activity
Intent i=new Intent(this,Activity1.class); i.addFlags(Intent.FLAG_ACTIVITY_REORDER_TO_FRONT); st ...
- 多功能网页刷新工具,刷pv工具
多功能网页刷新工具,刷pv工具,在线刷流量,刷PV,刷UV小牛刷新助手功能介绍:1.设置多个刷新网页地址.2.设置刷新时间3.开始工作4.其他操作:老板键:打开时自动刷新:置系统托盘5.可手动输入地址 ...
- Oracle获取一周前,一个月前,一年前, 本周,本月,当年的日期
1.获取当前时间一周前的日期 ' day from dual 类似的 --当前时间减去7分钟的时间 ' MINUTE from dual --当前时间减去7小时的时间 ' hour from dual ...