HBase体系架构和集群安装
一、HBase体系架构
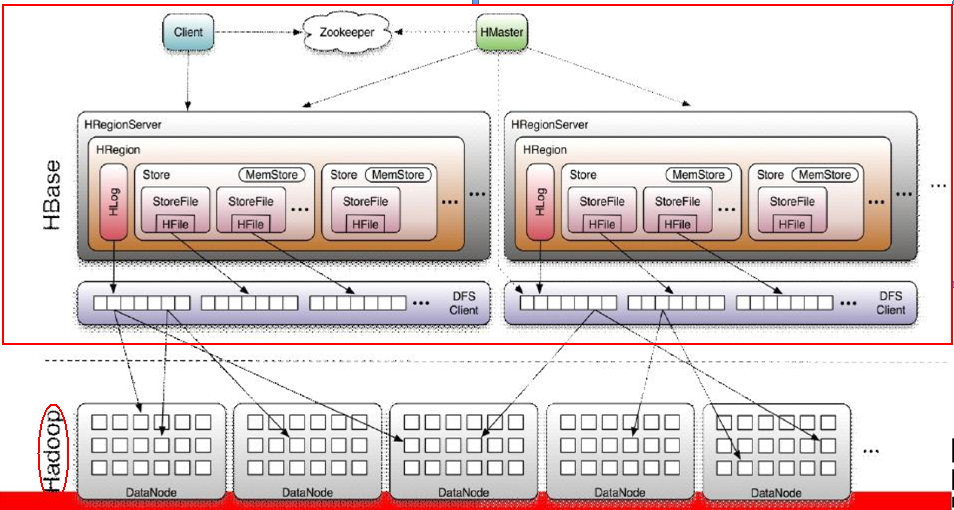
Hbase体系架构图
1.1、 Client
• 包含访问HBase的接口并维护cache来加快对HBase的访问
1.2、Region
• HBase自动把表水平划分成多个区域(region),每个region会保存一个表里面某段连续的数据;每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,region就会等分会两个新的region(裂变);
• 当table中的行不断增多,就会有越来越多的region。这样一张完整的表被保存在多个Regionserver 上。
1.3、Zookeeper
• 保证任何时候,集群中只有一个master;
• 存贮所有Region的寻址入口;
• 实时监控Region server的上线和下线信息,并实时通知Master;
• 存储HBase的schema和table元数据;
1.4、Master
• 为Region server分配region;
• 负责Region server的负载均衡;
• 发现失效的Region server并重新分配其上的region;
• 管理用户对table的增删改操作;
1.5、RegionServer
• Region server维护region,处理对这些region的IO请求
• Region server负责切分在运行过程中变得过大的region
1.6、Memstore与storefile
• 一个region由多个store组成,一个store对应一个CF(列族)
• store包括位于内存中的memstore和位于磁盘的storefile,写操作先写入memstore,当memstore中的数据达到某个阈值,hregionserver会启动flashcache进程写入storefile,每次写入形成单独的一个storefile;当storefile文件的数量增长到一定阈值后,系统会进行合并(minor、major compaction),在合并过程中会进行版本合并和删除工作(majar),形成更大的storefile
• 当一个region所有storefile的大小和超过一定阈值后,会把当前的region分割为两个,并由hmaster分配到相应的regionserver服务器,实现负载均衡
• 客户端检索数据,先在memstore找,找不到再找storefile
• HRegion是HBase中分布式存储和负载均衡的最小单元。最小单元就表示不同的HRegion可以分布在不同的 HRegion server上。
• HRegion由一个或者多个Store组成,每个store保存一个columns family。
• 每个Strore又由一个memStore和0至多个StoreFile组成。如图:StoreFile以HFile格式保存在HDFS上。
二、Hbase集群安装
1、上传tar包到集群里,这里我选择的是hbase-1.1.2-bin.tar包。
https://hbase.apache.org 这是hbase官网。
2、修改hbase-env.sh中配置JAVA_HOME:

不使用HBase的默认zookeeper配置:

3、修改配置hbase-site.xml

4、配置regionservers 添加你配置的regionservers 的主机名,如hadoop1,hadoop2,hadoop3 ...
5、vi并配置backup-masters 添加你配置的master备份的主机名

6、拷贝Hadoop的conf下配置文件hdfs-site.xml到当前conf下
7、启动:Zookeeper集群主机
8、启动hbase :因为HBase依赖于Hadoop和zookeeper之上的所以要Hadoop集群启动正常和Zookeeper集群启动正常之后,再启动hbase。

9、启动后

10、启动浏览器访问
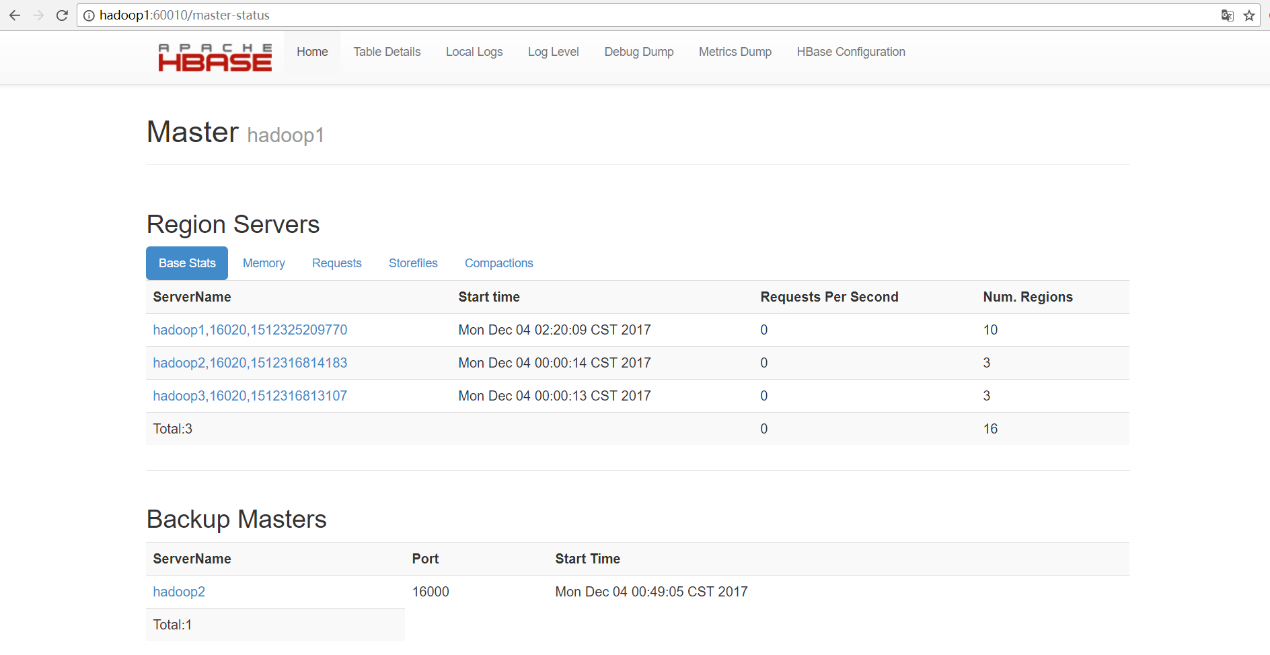
如果能成功显示出此页面,那么我们的hbase集群安装就算大功告成啦~。
好了,本次分享先告一段落,下次我们将继续为大家介绍hbase,下次见~~~
有问题的或者想获取更多资料的请茄薇 java8733
HBase体系架构和集群安装的更多相关文章
- hbase 0.98.1集群安装
本文将基于hbase 0.98.1解说其在linux集群上的安装方法,并对一些重要的设置项进行解释,本文原文链接:http://blog.csdn.net/bluishglc/article/deta ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- hadoop 2.2.0集群安装
相关阅读: hbase 0.98.1集群安装 本文将基于hadoop 2.2.0解说其在linux集群上的安装方法,并对一些重要的设置项进行解释,本文原文链接:http://blog.csdn.net ...
- HBase简介及集群安装
一.Hbase概述 Apache HBase™是Hadoop数据库,是一个分布式,可扩展的大数据存储. 当您需要对大数据进行随机,实时读/写访问时,请使用Apache HBase™.该项目的目标是托 ...
- hbase集群安装与部署
1.相关环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 hbase1.2.4 本篇文章仅涉及hbase集群的搭建,关于hadoop与zookeeper的相关部 ...
- hbase单机环境的搭建和完全分布式Hbase集群安装配置
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. @hbase单机环境的搭建 ...
- HBase集群安装部署
0x01 软件环境 OS: CentOS6.5 x64 java: jdk1.8.0_111 hadoop: hadoop-2.5.2 hbase: hbase-0.98.24 0x02 集群概况 I ...
- Hbase 集群安装(Hadoop 2.6.0 hbase0.99.2)
一:说明 该安装是在hadoop集群安装后进行,详情可见上一篇博客虚拟机centos7系统下安装hadoop ha和yarn ha(详细) .其中涉及五台机器,两台master(机器名:master, ...
- hbase和ZooKeeper集群安装配置
一:ZooKeeper集群安装配置 1:解压zookeeper-3.3.2.tar.gz并重命名为zookeeper. 2:进入~/zookeeper/conf目录: 拷贝zoo_sample.cfg ...
随机推荐
- python入门day02数据类型
字符串:数据类型的学习 #======================================基本使用====================================== #1.用途 ...
- Centos7 优盘U盘安装以及解决安装时引导错误
一.使用UltraISO将安装镜像iso文件,写入优盘(写入硬盘映像).将优盘盘符名改为CENTOS7,否则以后引导很麻烦二.将优盘插入要安装CentOS7的电脑,设置开机U盘启动三.并启动到安装界面 ...
- POJ 3162.Walking Race 树形dp 树的直径
Walking Race Time Limit: 10000MS Memory Limit: 131072K Total Submissions: 4123 Accepted: 1029 Ca ...
- pip更换源
#mkdir ~/.pipcd .pipvi pip.conf [global]trusted-host = pypi.tuna.tsinghua.edu.cnindex-url = https:/ ...
- pd 注意事项
- java的多态性
class test1{ int a=3; public test1(int a) { this.a=a; } public void aa() { ...
- redis多实例
1.首先在发布系统: 2.安装多实例利用cmd命令安装,切换目录到redis下 (1)首先拷贝一个redis的conf文件(如redis_6380.conf),并且修改里面的服务端口号.日志端口号,以 ...
- 微信小程序的一些小知识点
1. <text>hello</text> 只有包含在<text>标签内的文字,在手机上才可以长按选中. 2. 单位px:自适应rpx = 1:1 物理像素除以2得 ...
- 【ElasticSearch】 elasticsearch-head插件安装
本章介绍elasticsearch-head插件安装,elasticsearch安装参考:[ElasticSearch] 安装 elasticsearch-head安装和学习可参照官方文档: http ...
- python3 tkinter添加图片和文本
在前面一篇文章基础上,使用tkinter添加图片和文本.在开始之前,我们需要安装Pillow图片库. 一.Pillow的安装 1.方法一:需要下载exe文件,根据下面图片下载和安装 下载完 ...